溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么用Python+Excel+Word制作百份合同”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么用Python+Excel+Word制作百份合同”吧!
大家好,又到了Python辦公自動化系列。
今天我們繼續分享一個真實的辦公自動化需求:如何使Python+Excel+Word批量生成指定格式內容的合同。
主要涉及的知識點有:openpyxl模塊的綜合運用與Word文檔的兩種遍歷邏輯。
你是乙方建筑公司,手上有一份空白合同模板的Word文件,如下圖:


另外還有一份Excel合同信息表,其中是所有甲方(發包人)在合同中需要填寫的內容
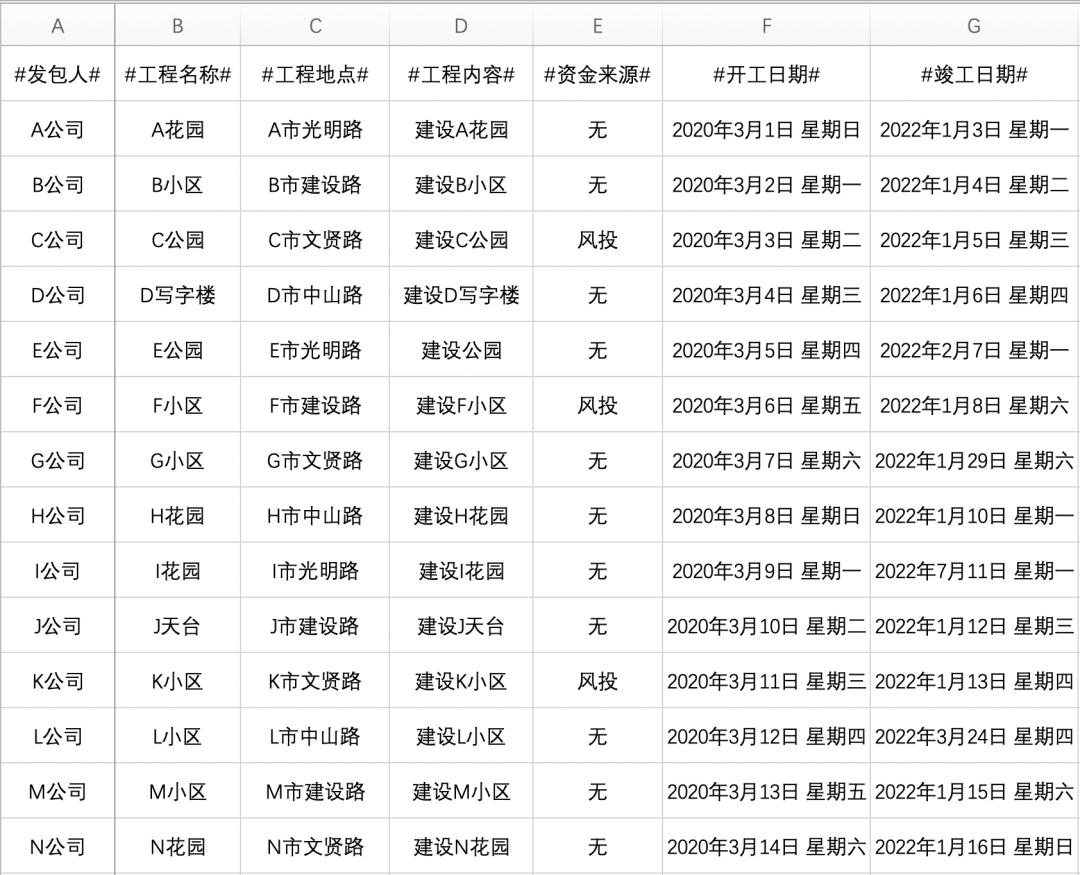
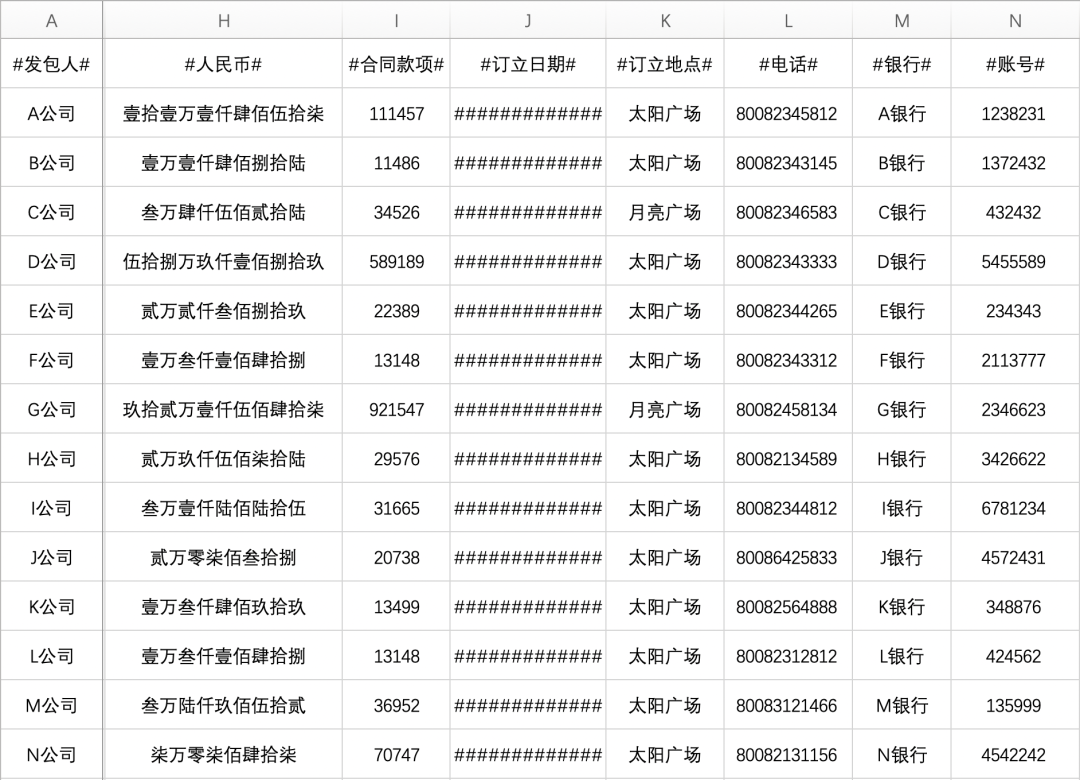
可見一行為一個公司的全部信息,現在需要把Excel中每一個公司的信息填入空白Word合同模板中,生成各公司的合同,最終結果如下
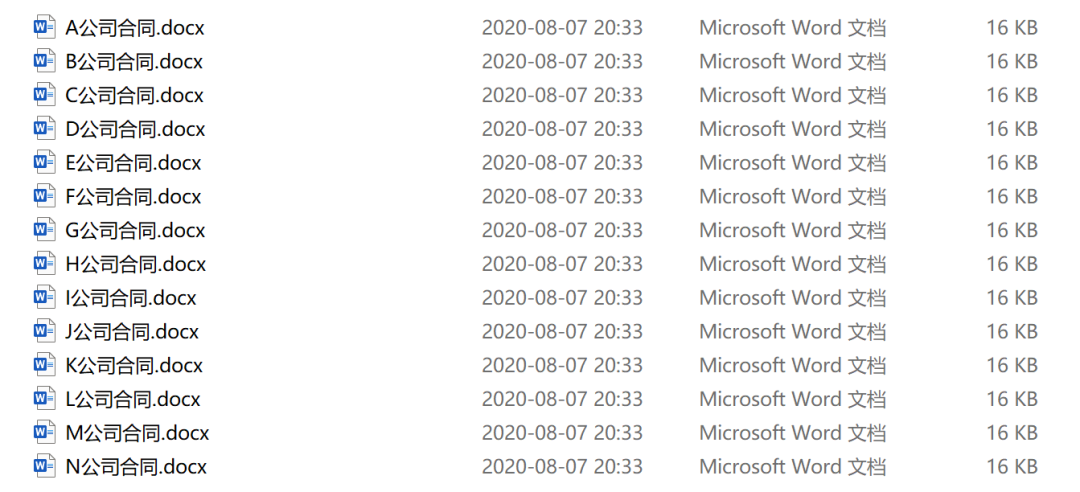

原本我們需要將Excel匯總表中每一行的信息填進word模板中,生成相應的合同。
現在我們需要交給Python來實現,就引出了一個問題:程序如何知道要將某個信息填到哪個下劃線? 為了解決這個問題,我們需要對模板進行修改。
即將下劃線改成某種標識,讓程序可以看到標識就明白此處應該放什么信息,這里采取的策略是:將需要填寫的下劃線改成匯總表中的列名,即下圖所示

這樣程序就可以識別需要填寫什么內容了。所謂的識別在這里可以換一個特別簡單的詞,即文本替換。只要檢索到#xxxx#(excel中的列名),把這個替換成具體的信息就可以了。
出于這種策略,列名就需要用#xxxx#的格式,否則正常的無關文本中的信息也會被替換,就破壞了原有的需求,最后模板被修改成如下:

通過Excel表我們可以看到,一行為一個公司的信息,而每一列的列名就存在于模板中,用各個公司的實際信息替換到模板中的列名(程序識別和文本替換的依據)
用這樣的方法就可以完成這個需求。整個大需求的實現可以按照下面的步驟:
分析后的步驟:
將 空白合同 調整成 合同模板,需要填寫的下劃線改成專屬的列名 打開Excel表,按行循環,然后按單元格逐個循環各個信息,每個信息都找到模板中存在的對應列名并將其替換(如果不理解下文還有解釋) 每次循環完一行的全部單元格后保存合同,生存各個公司單獨的合同
分析清楚后邏輯就非常簡單了,但有一個隱含的知識點沒有提到,讓我們邊寫代碼邊說!
首先導入模塊,設置路徑,建立文件夾,本例中涉及Excel表的打開和Word的創建,因此需要從openpyxl導入load_workbook,而Word無論打開還是創建,用docx模塊的Document均可
from docx import Document
from openpyxl import load_workbook
# 利用os模塊建立文件夾,用于存放生成的合同
import os
# 給定合同模板和匯總表所在的文件夾路徑,方便復用
path = r'C:\Users\chenx\Desktop\合同'
# 結合路徑判斷生成文件夾,規避程序報錯而終止的風險
if not os.path.exists(path + '/' + '全部合同'):
os.mkdir(path + '/' + '全部合同')
接著打開Excel文件
workbook = load_workbook(path + '/' + '合同信息表.xlsx')
sheet = workbook.active
現在遍歷Excel,生成合同。前面也反復提到,Excel的每一行是一份特定合同的信息,因此docx針對Word文件的實例化和保存一定是在循環體里的,而不像Excel的實例化是在循環體外面
# 有效信息行是從第二行開始的,第二行是表頭,包含列名,也是文本替換的依據
for table_row in range(2, sheet.max_row + 1):
# 每循環一行實例化一個新的word文件
wordfile = Document(path + '/' + '合同模板.docx')
# 單元格需要逐個遍歷,每一個都包含著有用的信息
for table_col in range(1, sheet.max_column + 1):
# 舊的文本也就是列名,已經在模板里填好了,用于文本替換,將row限定在第一行后就是列名
old_text = str(sheet.cell(row=1, column=table_col).value)
# 新的文本就是實際的信息,table_col循環到某個數值時,實際的單元格和列名就確定了
new_text = str(sheet.cell(row=table_row, column=table_col).value)
# 加上這個判斷是因為日期信息讀進程序是“日期 時間”格式的,如果要保留日期信息可以用字符串方法或者用time/datetime模塊處理
if ' ' in new_text:
new_text = new_text.split()[0]
通過下圖進一步理解這個替換:
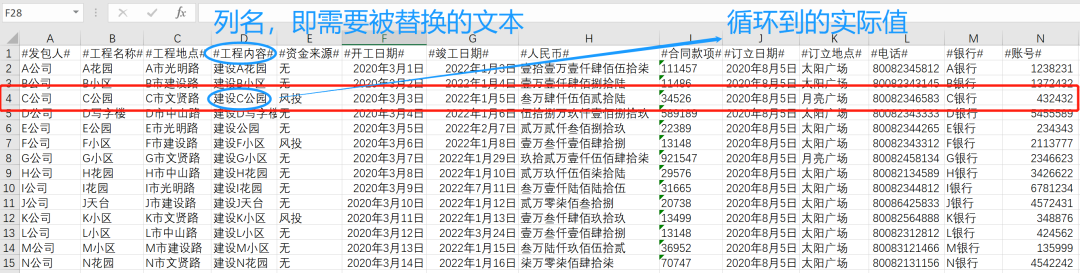 例如程序已經進入第3個循環(循環到第3個公司),針對單元格的循環進入第4個循環,那么此時獲取的實際值是
例如程序已經進入第3個循環(循環到第3個公司),針對單元格的循環進入第4個循環,那么此時獲取的實際值是建設C公園,對應的列名是#工程內容#。
此時就明確了需要被替換的內容了,只要在模板中找到#工程內容#把它替換為建設C公園即可!了解了這個替換后,下一步就是遍歷Word模板,找到對應列名替換!
之前我們說過docx模塊,Word文本存在文檔Document-段落Paragraph-文字塊Run的三級結構,需要遍歷文本可以用以下代碼:
all_paragraphs = wordfile.paragraphs
for paragraph in all_paragraphs:
print(paragraph.text)
for run in paragraph.runs:
print(run.text)
針對段落和文字塊均可用.text獲取到文字信息。本需求隱含的陷阱就在這里,注意一下合同最后需要填寫的內容:

這部分內容如果用上述代碼是遍歷不到的。為什么?因為這是Word文檔中的表格!
遍歷表格需要有專門的遍歷邏輯:文檔Document-表格Table-行Row/列Column-單元格Cell,遍歷表格中文本的代碼如下:
all_tables = wordfile.tables
for table in all_tables:
# 也可按列遍歷
for row in table.rows:
for cell in row.cells:
print(cell.text)
有了這些補充的知識之后,本案例中最核心的代碼就可以這么寫
for table_row in range(2, sheet.max_row + 1):
wordfile = Document(path + '/' + '合同模板.docx')
for table_col in range(1, sheet.max_column + 1):
old_text = str(sheet.cell(row=1, column=table_col).value)
new_text = str(sheet.cell(row=table_row, column=table_col).value)
if ' ' in new_text:
new_text = new_text.split()[0]
# 文檔Document - 段落Paragraph - 文字塊Run
all_paragraphs = wordfile.paragraphs
for paragraph in all_paragraphs:
for run in paragraph.runs:
run.text = run.text.replace(old_text, new_text)
# 文檔Document - 表格Table - 行Row/列Column - 單元格Cell
all_tables = wordfile.tables
for table in all_tables:
for row in table.rows:
for cell in row.cells:
cell.text = cell.text.replace(old_text, new_text)
# 獲取公司名用以生成合同的名稱
company = str(sheet.cell(row=table_row, column=1).value)
wordfile.save(path + '/' + f'全部合同/{company}合同.docx')本次的案例具有較強的實用性,并且需求可以延伸成為:將一份信息匯總表Excel中的每一個單獨信息(每一行或者每一列為個人、公司或者其他的信息)填寫到指定的模板Eord中,生成單獨的文檔,不過在寫自動化腳本之前也要先拆分任務,明確思路再進行!
到此,相信大家對“怎么用Python+Excel+Word制作百份合同”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





