溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python正則爬蟲的方法是什么”,在日常操作中,相信很多人在Python正則爬蟲的方法是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python正則爬蟲的方法是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
正則表達式(Regular Expression, Regex 或 RE)又稱正規表示法或常規表示法,常用來檢索、替換那些符合某個模式的文本。
它首先設定好一些特殊的字符及字符組合,然后通過組合的“規則字符串”來對表達式進行過濾,從而獲取或匹配用戶想要的特定內容。
Python 通過 re 模塊提供對正則表達式的支持,但在使用正則表達式之前需要導入 re 模塊才能調用該模塊的功能函數。
import re
其基本步驟是:
常用函數是 findall,原型如下:
findall(String[, pos[, endpos]])|re.findall(pattern, string[, flags])
該函數表示搜索字符串 string,然后以列表形式返回全部匹配字符串。
其中,參數 re 包括3個常見值。(括號內是完整寫法)
re.I(re.IGNORECASE) # 使匹配忽略大小寫
re.M(re.MULTILINE) # 允許多行匹配
re.S(re.DOTALL) # 匹配包括換行在內的所有字符另外,pattern 對象是一個編譯好的正則表達式,通過 pattern 提供的一系列方法可以對文本進行匹配查找;pattern 對象不能直接實例化,必須使用 re.compile() 進行構造。
re 模塊包括一些常用的操作函數,比如 complie() 函數,其原型如下:
re.compile(pattern[, flags])
該函數根據包含正則表達式的字符串創建模式對象,返回一個 pattern 對象。其中,參數 flags 是匹配模式,可以使用按位或“|”表示同時生效,也可以在正則表達式字符串中指定。
# 舉例說明如何使用正則表達式來獲取字符串中的數字內容
import re
string = 'A1.45, b5, 6.45, 8.82'
regex = re.compile(r"\d+\.?\d*")
print(regex.findall(string))結果如下:

match 方法是從字符串的 pos 下標處開始匹配 pattern,如果 pattern 結束時已經匹配,則返回一個 match 對象;如果匹配過程中 pattern 無法匹配,或者匹配未結束就已達到 endpos,則返回 None。
match 方法原型如下:
match(string[, pos[, endpos]]) | re.match(patter, string[, flags])
其中,參數 string 表示字符串;pos 表示下標,pos 和 endpos 的默認值分別為 0 和 len(string);參數 flags 用于編譯 pattern 時指定匹配模式。
search 方法用于查找字符串中可以匹配成功的子字符串。從字符串的 pos 下標處嘗試匹配 pattern,如果 pattern 結束時仍可匹配,則返回一個 match 對象,如果 pattern 結束時仍無法匹配,則將 pos 加 1 后重新嘗試匹配,若知道 pos = endpos 時仍無法匹配,則返回 None。
search 方法函數原型如下:
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
其中,參數 string 表示字符串;pos 表示下標,pos 和 endpos 的默認值分別為 0 和 len(string);參數 flags 用于編譯 pattern 時指定匹配模式。
1.5 group和groups方法
group([group1, …]) 方法用于獲得一個或多個分組截獲的字符串,當它指定多個參數時將以元組形式返回 None,截獲多次的組返回最后一次截獲的字符串。
groups([default]) 方法以元組形式返回全部分組截獲的字符串,相當于多次調用 group,其中參數 default 表示沒有截獲字符串的組以該值代替,默認為 None。
urllib 是 Python 用于獲取 URL(Uniform Resource Locators,同意資源定位器)的庫函數,可以用于爬取遠程的數據并保存,甚至可以設置消息頭(header)、代理、超時認證等。
urllib 模塊提供的上策接口使用戶能夠像讀取本地文件一樣讀取 WWW 或 FTP 上的數據,使用起來比C++、C#等編程語言更加方便。
函數原型如下:
urlopen(url, data = None, proxies = None)
該方法用于創建一個遠程 URL 的類文件對象,然后像本地文件一樣操作這個類文件對象來獲取遠程數據。其中參數 url 表示遠程數據的路徑,一般是網址;參數 data 表示以 post 方式提交到 url 的數據;參數 proxies 用于設置代理;返回值是一個類文件對象。

本實例用來介紹 urllib 庫函數爬取百度官網的實例
import urllib.request
import webbrowser as web
url = 'http://www.baidu.com'
content = urllib.request.urlopen(url) # 打開鏈接
print(content.info) # 頭信息
print(content.geturl) # 請求url
print(content.getcode) # HTTP狀態碼
# 保存至本地并通過瀏覽器打開
response = urllib.request.urlopen(url).read()
open('baidu.html', 'w').write(response.decode('UTF-8'))結果如下:
urlretrieve 方法是將遠程數據下載到本地,函數原型如下:
urlretrieve(url, filename = None, reporthook = None, data = None)
其中,參數 filename 指定了保存到本地的路徑,如果省略該函數,則 urllib 會自動生成一個臨時文件來保存數據;
參數 reporthook 是一個回調參數,當連接上服務器,響應的數據塊傳輸完畢時,會觸發該調回函數,通常使用該回調函數來顯示當前的下載進度;
參數 data 是指傳遞到服務器的數據。
本實例用來演示如何將新浪首頁爬取到本地,并保存在“F:/sina.html”文件中,同時顯示下載進度。
from urllib.request import urlretrieve
# 設置函數來表示下載文件至本地,并顯示下載進度
def Download(a, b, c):
# a--已經下載的數據塊
# b--數據塊的大小
# c--遠程文件的大小
per = 100.0 * a * b / c
if per >100:
per = 100
print('%.2f%%' % per)
url = 'http://www.sina.com.cn'
local = 'F:/sina.html'
urlretrieve(url, local, Download)結果如下:
urlparse 模塊主要是對 url 進行分析,其主要的操作時拆分和合并 url 各個部件。它可以將 url 拆分成 6 個部分,并返回元組,也可以把拆分后的部分再組成一個 url。
urlparse 模塊包括的函數主要有 urlparse、urlunparse 等。
# python3版本中已經將urllib2、urlparse、和robotparser并入了urllib模塊中,并且修改urllib模塊
from urllib.parse import urlunparse
from urllib.parse import urlparse函數原型如下:
urlparse(urlstring[, scheme[, allow_fragments]])
該函數將 urlstring 值解析成 6 各部分,從 urlstring 中獲取 URL,并返回元組(scheme,netloc,path、params、query、fragment)。該函數可用于確定網絡協議(HTTP、FTP等)、服務器地址、文件路徑等。
from urllib.parse import urlparse
url = urlparse('https://blog.csdn.net/IT_charge/article/details/105714745')
# 輸出內容包括以下六個部分scheme, netloc, path, params, query, fragment
print(url)
print(url.netloc)結果如下:

同樣可以調用 urlunparse() 函數將一個元祖內容構建成一條 url,函數原型如下:
urlunparse(parts)
該元組類似 urlparse 函數,它接收元組(scheme, netloc, path, params, query, fragment)后,會重新組成一個具有正確格式的URL,以便共 Python 的其他 HTML 解析模塊使用。
from urllib.parse import urlunparse
from urllib.parse import urlparse
url = urlparse('https://blog.csdn.net/IT_charge/article/details/105714745')
# 輸出內容包括以下六個部分scheme, netloc, path, params, query, fragment
print(url)
print(url.netloc)
# 重組url
u = urlunparse(url)
print(u)結果如下:

requests 模塊是用 Python 語言編寫的、基于 urllib 的第三方庫,其采用 Apache2 Licensed 開源協議的 HTTP 庫。它比 urllib 更加方便,既可以節約大量的工作,又完全滿足 HTTP 的測試需求。
安裝 requests 模塊方法
pip install requests
使用語句如下:
import requests
requests 模塊可以發送 HTTP 的兩種請求,GET 請求和 POST 請求。其中 GET 請求可以采用 url 參數傳遞數據,它從服務器上獲取數據,而 POST 請求是向服務器傳遞數據,該方法更為安全。
# 這里給出 get 和 post 請求獲取某個網站網頁的方法,得到一個命名為 response 的響應對象,通過這個對象獲取我們所需要的信息
r = requests.get('https://github.com/timeline.json)
r = requests.post('https://httpbin.org/post)url 通常會傳遞某種數據,這種數據采用鍵值對的參數形式置于 URL 中。
requests通過 params 關鍵字設置 URL 的參數,以一個字符串字典來提供這些參數。
# 傳遞 key1=value1 和 key2=value2 到 httpbin.org/get 后
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('http://httpbin.org/get', params = payload)
print(r.url)結果如下:

requests 會自動解碼來自服務器的內容,并且大多數 Unicode 字符集都能被無縫解碼。當請求發出后,requests 會基于 HTTP 頭部對響應的編碼做出有根據的推測。
import requests
r = requests.get('https://github.com/timeline.json')
print(r.text)結果如下:

只需要簡單地傳遞一個字典(dict)給消息頭 headers 參數即可。以網站“堆糖”為例,其 headers 參數在 User-Agent 里找。
定制請求頭是為了偽裝爬蟲程序,不會被網站輕易檢測出來,亦即不會返回 403 錯誤。
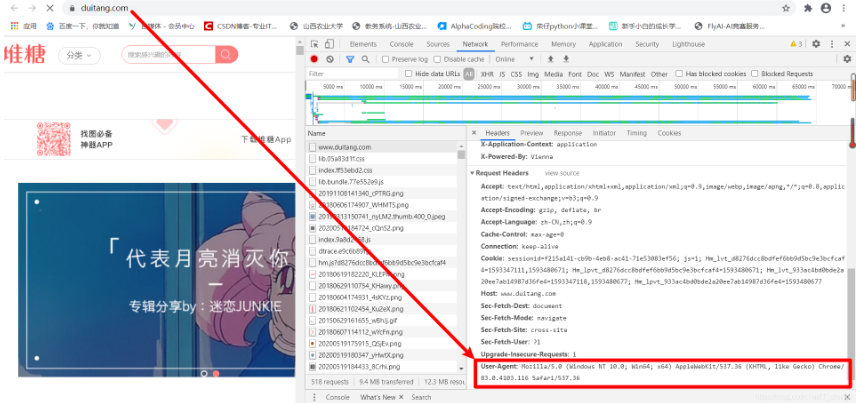
演示如下:
# 這里假設給 堆糖 網站指定一個消息頭
import requests
base_url = 'https://www.duitang.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
response = requests.get(url=base_url, headers=headers)
print(response)結果如下:

HTML語言是采用標簽對的形式來編寫網站的,包括起始標簽和結束標簽,比如、、等。
首先可以采用正則表達式“‘’”來爬取起始標簽之間的內容。
# 本實例用來爬取百度官網標題——“百度一下,你就知道”
import re
import requests
url = 'https://www.baidu.com/?tn=78040160_5_pg&ch=8'
response = requests.get(url).content.decode('utf-8')
title = re.findall(r'<title>(.*?)</title>', response)
print(title[0])結果如下:

在 HTML 中, 超鏈接標題 用于表示超鏈接。
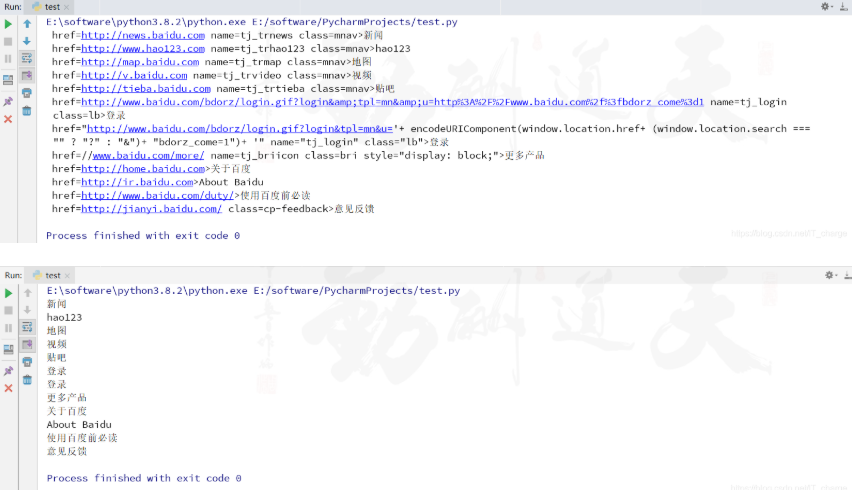
import re
import requests
url = "http://www.baidu.com"
content = requests.get(url).content.decode('utf-8')
# 獲取完整的超鏈接
res1 = re.compile('<a(.*?)</a>')
urls1 = re.findall(res1, content)
for u1 in urls1:
print(u1)
# 獲取超鏈接<a>和</a>之間的內容
res2 = re.compile('<a.*?>(.*?)</a>')
urls2 = re.findall(res2, content)
for u2 in urls2:
print(u2)結果如下:
網頁常用的布局包括 table 布局和 div 布局,其中,table 布局中常見的標簽包括tr,th和td,tr(table row)表示表格行為,td(table data)表示表格數據,th(table heading)表示表格表頭。
首先假設存在下面這樣一個HTML代碼。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>表格</title>
</head>
<body>
<table border="1">
<tr><th>編號</th><th>課程名</th></tr>
<tr><td>001</td><td>Python程序設計語言</td></tr>
<tr><td>002</td><td>JavaScript</td></tr>
<tr><td>003</td><td>網絡數據爬取及分析</td></tr>
</table>
</body>
</html>結果如下:
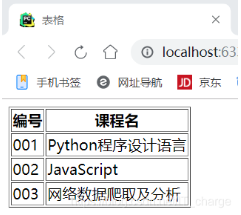
此時,看看怎么使用Python代碼獲取上述信息呢?
import re
# 獲取<tr> </tr>之間的內容
f = open("t.html","r",encoding="utf-8") # 讀取文件
f = f.read() # 把文件內容轉化為字符串
trs = re.findall(r'<tr>(.*?)</tr>', f, re.S|re.M)
for tr in trs:
print(tr)
# 獲取<th> </th>之間的內容
print('\n')
for m in trs:
ths = re.findall(r'<th>(.*?)</th>', m, re.S|re.M)
for th in ths:
print(th)
# 獲取<td> </td>之間的內容
print('\n')
tds = re.findall(r'<td>(.*?)</td><td>(.*?)</td>', f, re.S|re.M)
for td in tds:
print(td[0], td[1])結果如下:
HTML超鏈接的基本格式為 “ 鏈接內容 ”。
import re
content = '''
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新聞</a>
<a href="http://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地圖</a>
'''
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
urls = re.findall(res, content, re.I|re.S|re.M)
for url in urls:
print(url)結果如下:

在HTML中,我們可以看到各式各樣的圖片,其中圖片標簽的基本格式為“ <img src = 圖片地址/> ” ,只有通過爬取這些圖片原地址,才能下載對應的圖片至本地。
import re
content = '''
<img alt = "meizi" src = "http://img.ivsky.com/img/tupian/pre/202001/15/gancaoduo-002.jpg"/>
'''
res = '<img .*? src = "(.*?)"/>'
urls = re.findall(res, content, re.I|re.S|re.M)
print(urls)結果如下:
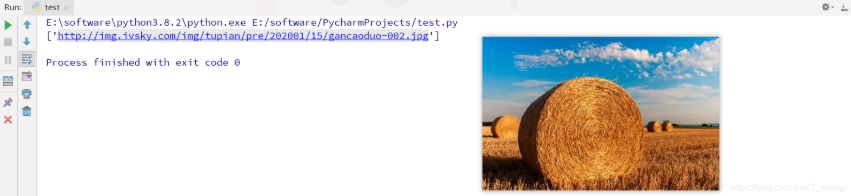
在使用 Python 爬取圖片的過程中,通常會遇到圖片對應的 URL 最后一個字段用來對圖片命名的情況,如前面的“gancaoduo-002.jpg”,因此就需要通過解析 URL “/” 后面的參數來獲取圖片名字。
import re
content = '''
<img alt = "meizi" src = "http://img.ivsky.com/img/tupian/pre/202001/15/gancaoduo-002.jpg"/>
'''
# res = '<img .*? src = "(.*?)"/>'
# urls = re.findall(res, content, re.I|re.S|re.M)
# print(urls)
urls = 'http://img.ivsky.com/img/tupian/pre/202001/15/gancaoduo-002.jpg'
# 采用“/”分隔字符串,進而獲取最后一個值
picture_name = urls.split('/')[-1]
print(picture_name)結果如下:

當使用正則表達式爬取網頁文本時,首先需要調用 find() 函數來找到指定的位置,然后在進行進一步爬取。
# 比如先獲取class屬性為“infobox”的表格table,然后再進行定位爬取
start = content.find(r'<table class="infobox>') # 起點位置
end = content.find(r'</table>') # 終點位置
infobox = text[start:end]
print(infobox)在爬取過程中可能會爬取無關變量,此時需要對無關內容進行過濾,這里推薦使用replace()函數和正則表達式進行處理。
import re
content = '''
<tr><td>000</td><td>軟件工程</td></tr>
<tr><td>001</td><td>Python程序設計語言<br/></td></tr>
<tr><td>002</td><td><B>JavaScript</B></td></tr>
<tr><td>003</td><td>網絡數據 爬取及分析</td></tr>
'''
res = r'<td>(.*?)</td><td>(.*?)</td>'
texts = re.findall(res, content, re.S|re.M)
for text in texts:
print(text[0], text[1])結果如下:

此時需要過濾掉多余的字符串,如換行()、空格( )、加粗(),過濾代碼如下。
import re
content = '''
<tr><td>000</td><td>軟件工程</td></tr>
<tr><td>001</td><td>Python程序設計語言<br/></td></tr>
<tr><td>002</td><td><B>JavaScript</B></td></tr>
<tr><td>003</td><td>網絡數據 爬取及分析</td></tr>
'''
res = r'<td>(.*?)</td><td>(.*?)</td>'
texts = re.findall(res, content, re.S|re.M)
for text in texts:
value0 = text[0].replace('<br/>', "").replace(' ', "")
value1 = text[1].replace('<br/>', "").replace(' ', "")
if '<B>' in value1:
text_value = re.findall(r'<B>(.*?)</B>', value1, re.S|re.M)
print(value0, text_value[0])
else:
print(value0, value1)結果如下:

采用 replace() 函數將字符串 “” 和 “< >” 轉換成空白實現過濾,而加粗()則需要使用正則表達式進行過濾 。
到此,關于“Python正則爬蟲的方法是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





