溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行Scrapy的安裝與基本使用,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
一、簡單實例,了解基本。
1、安裝Scrapy框架
這里如果直接pip3 install scrapy可能會出錯。
所以你可以先安裝lxml:pip3 install lxml(已安裝請忽略)。
安裝pyOpenSSL:在官網下載wheel文件。
安裝Twisted:在官網下載wheel文件。
安裝PyWin32:在官網下載wheel文件。
下載地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
配置環境變量:將scrapy所在目錄添加到系統環境變量即可。
ctrl+f搜索即可。
最后安裝scrapy,pip3 install scrapy
2、創建一個scrapy項目
新創建一個目錄,按住shift-右鍵-在此處打開命令窗口
輸入:scrapy startproject tutorial即可創建一個tutorial文件夾
文件夾目錄如下:
|-tutorial
|-scrapy.cfg
|-__init__.py
|-items.py
|-middlewares.py
|-pipelines.py
|-settings.py
|-spiders
|-__init__.py
文件的功能:
scrapy.cfg:配置文件
spiders:存放你Spider文件,也就是你爬取的py文件
items.py:相當于一個容器,和字典較像
middlewares.py:定義Downloader Middlewares(下載器中間件)和Spider Middlewares(蜘蛛中間件)的實現
pipelines.py:定義Item Pipeline的實現,實現數據的清洗,儲存,驗證。
settings.py:全局配置
3、創建一個spider(自己定義的爬蟲文件)
例如以爬取貓眼熱映口碑榜為例子來了解一下:
在spiders文件夾下創建一個maoyan.py文件,你也可以按住shift-右鍵-在此處打開命令窗口,輸入:scrapy genspider 文件名 要爬取的網址。
自己創建的需要自己寫,使用命令創建的包含最基本的東西。
我們來看一下使用命令創建的有什么。

介紹一下這些是干嘛的:
name:是項目的名字
allowed_domains:是允許爬取的域名,比如一些網站有相關鏈接,域名就和本網站不同,這些就會忽略。
atart_urls:是Spider爬取的網站,定義初始的請求url,可以多個。
parse方法:是Spider的一個方法,在請求start_url后,之后的方法,這個方法是對網頁的解析,與提取自己想要的東西。
response參數:是請求網頁后返回的內容,也就是你需要解析的網頁。
還有其他參數有興趣可以去查查。
4、定義Item
item是保存爬取數據的容器,使用的方法和字典差不多。
我們打開items.py,之后我們想要提取的信息有:
index(排名)、title(電影名)、star(主演)、releasetime(上映時間)、score(評分)
于是我們將items.py文件修改成這樣。
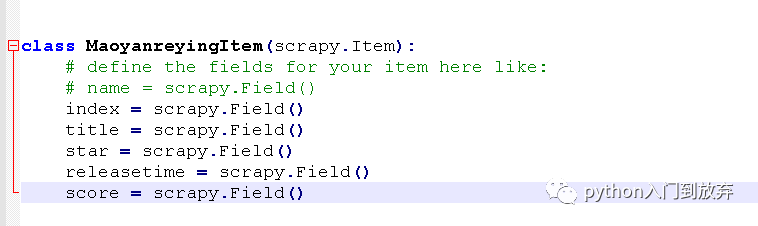
即可。
5、再次打開spider來提取我們想要的信息
修改成這樣:

好了,一個簡單的爬蟲就寫完了。
6、運行
在該文件夾下,按住shift-右鍵-在此處打開命令窗口,輸入:scrapy crawl maoyan(項目的名字)
即可看到:
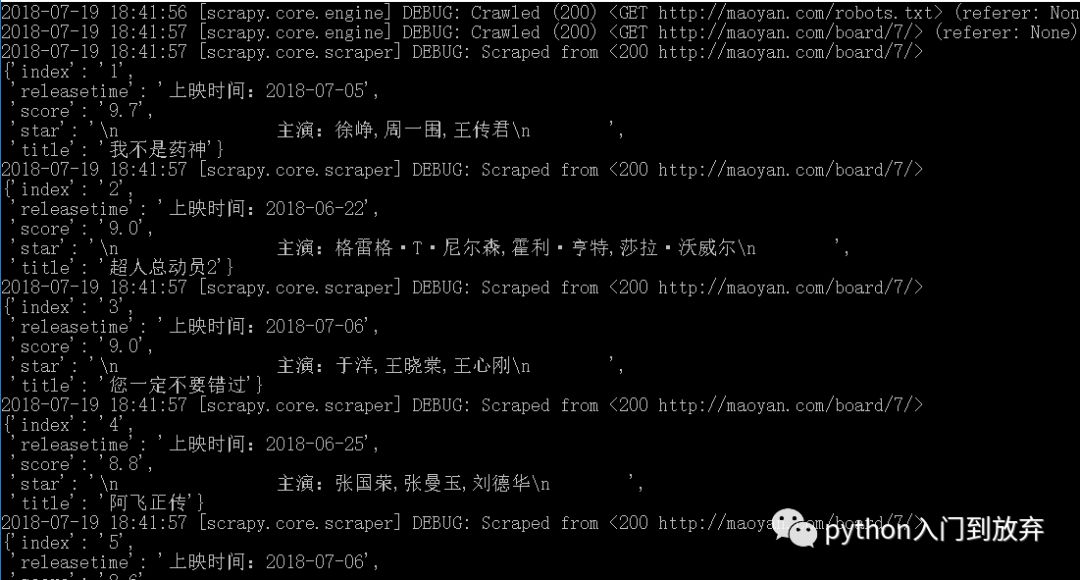
7、保存
我們只運行了代碼,看看有沒有報錯,并沒有保存。
如果我們想保存為csv、xml、json格式,可以直接使用命令:
在該文件夾下,按住shift-右鍵-在此處打開命令窗口,輸入:
scrapy crawl maoyan -o maoyan.csv
scrapy crawl maoyan -o maoyan.xml
scrapy crawl maoyan -o maoyan.json
選擇其中一個即可。當然如果想要保存為其他格式也是可以的,這里只說常見的。這里選擇json格式,運行后會發現,在文件夾下多出來一個maoyan.json的文件。打開之后發現,中文都是一串亂碼,這里需要修改編碼方式,當然也可以在配置里修改
(在settings.py文件中添加FEED_EXPORT_ENCODING='UTF8'即可),
如果想直接在命令行中修改:
scrapy crawl maoyan -o maoyan.json -s FEED_EXPORT_ENCODING=UTF8
即可。
這里自己試試效果吧。
當然我們保存也可以在運行的時候自動保存,不需要自己寫命令。后面介紹(我們還有還多文件沒有用到呦)。
二、scrapy如何解析?
之前寫過一篇文章:三大解析庫的使用
但是scrapy也提供了自己的解析方式(Selector),和上面的也很相似,我們來看一下:
1、css
首先需要導入模塊:from scrapy import Selector
例如有這樣一段html代碼:
html='<html><head><title>Demo</title><body>
<div class='cla'>This is Demo</div></body></head></html>'
1.1、首先需要構建一個Selector對象
sel = Selector(html)
text = sel.css('.cla::text').extract_first()
.cla表示選中上面的div節點,::text表示獲取文本,這里和以前的有所不同。
extract_first()表示返回第一個元素,因為上述 sel.css('.cla::text')返回的是一個列表,你也可以寫成sel.css('.cla::text')[0]來獲取第一個元素,但是如果為空,就會報出超出最大索引的錯誤,不建議這樣寫,而使用extract_first()就不會報錯,同時如果寫成extract_first('123')這樣,如果為空就返回123
1.2、有了選取第一個,就有選取所有:extract()表示選取所有,如果返回的是多個值,就可以是這樣寫。
1.3、獲取屬性就是sel.css('.cla::attr('class')').extract_first()表示獲取class
1.4、獲取指定屬性的文本:sel.css('div[class="cla"]::text')
1.5、其他寫法和css的寫法如出一轍。
1.6、在scrapy中為我們提供了一個簡便的寫法,在上述的簡單實例中,我們知道了response為請求網頁的返回值。
我們可以直接寫成:response.css()來解析,提取我們想要的信息。同樣,下面要說的XPath也可以直接寫成:
response.xpath()來解析。
2、Xpath
Xpath的使用可以看上面的文章:三大解析庫的使用
注意:獲取的還是列表,所以還是要加上extract_first()或者extract()
3、正則匹配(這里用response操作)
例如:response.css('a::text').re('寫正則')
這里如果response.css('a::text')匹配的是多個對象,那么加上正則也是匹配符合要求的多個對象。
這里如果想要匹配第一個對象,可以把re()修改成re_first()即可。
注意:response不可以直接調用re(),response.xpath('.').re()可以相當于達到直接使用正則的效果。
正則的使用:萬能的正則表達式
三、Dowmloader Middleware的使用
本身scrapy就提供了很多Dowmloader Middleware,但是有時候我們要修改,
比如修改User-Agent,使用代理ip等。
以修改User-Agent為例(設置代理ip大同小異):
第一種方法,可以在settings.py中直接添加USER-AGENT='xxx'
但是我們想要添加多個User-Agent,每次隨機獲取一個可以利用Dowmloader Middleware來設置。
第一步將settings中的USER-AGENT='xxx'修改成USER-AGENT=["xxx","xxxxx","xxxxxxx"]
第二步在middlewares.py中添加:

from_crawler():通過參數crawler可以拿到配置的信息,我們的User-Agent在配置文件里,所以我們需要獲取到。
方法名不可以修改。
第三步在settings.py中添加:

將scrapy自帶的UserAgentmiddleware的鍵值設置為None,
自定義的設置為400,這個鍵值越小表示優先調用的意思。
四、Item Pipeline的使用。
1、進行數據的清洗
在一的實例中我們把評分小于等于8.5分的score修改為(不好看!),我們認為是不好看的電影,我們將pipeline.py修改成這樣:

在setting.py中添加:

我們執行一下:

2、儲存
2.1儲存為json格式
我們將pipeline.py修改成這樣:
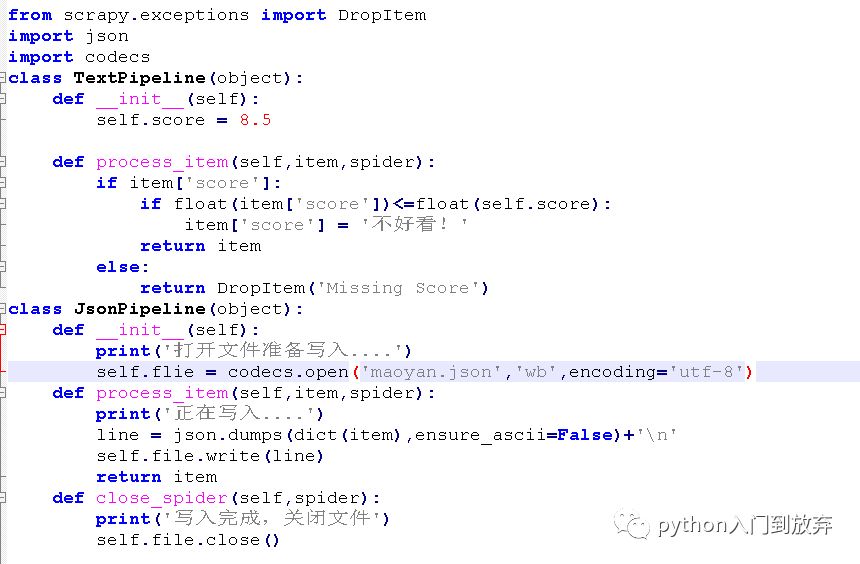
在setting.py中添加:

表示先執行TextPipeline方法,再執行JsonPipeline方法,先清洗,再儲存。
2.2儲存在mysql數據庫
首先在mysql數據庫中創建一個數據庫maoyanreying,創建一個表maoyan。
我們將pipeline.py修改成這樣:
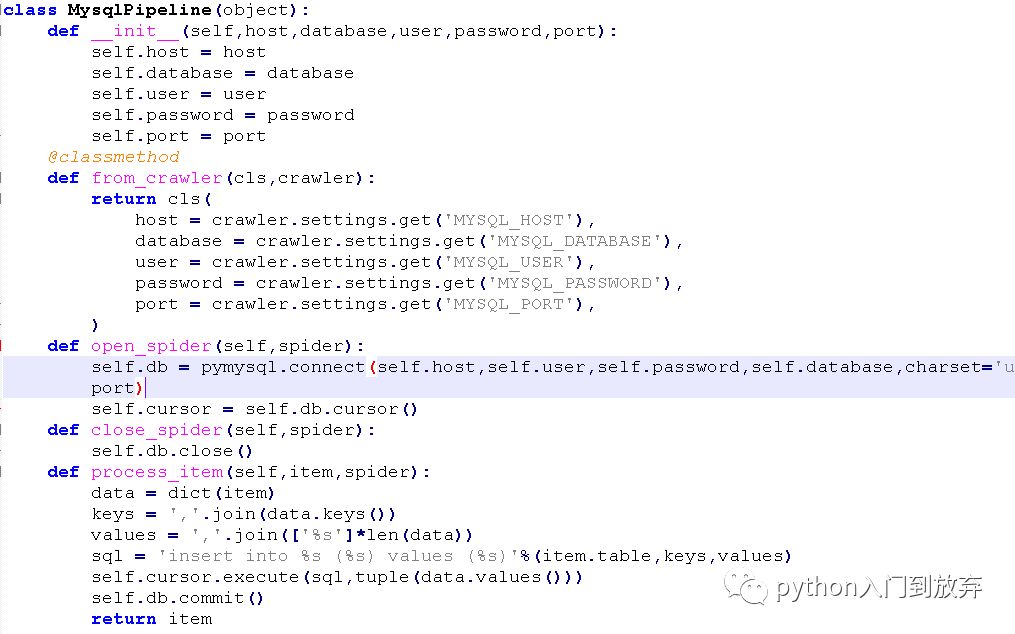
在setting.py中添加:
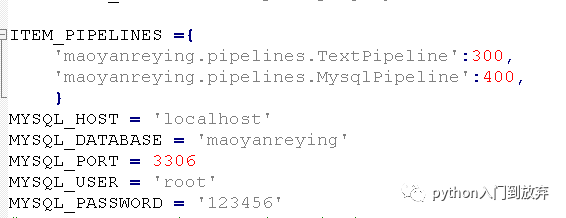
即可
完。
關于如何進行Scrapy的安裝與基本使用問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





