溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何使用OpenCV進行圖像全景拼接”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何使用OpenCV進行圖像全景拼接”吧!

圖像拼接是計算機視覺中最成功的應用之一。如今,很難找到不包含此功能的手機或圖像處理API。在本文中,我們將討論如何使用Python和OpenCV進行圖像拼接。也就是,給定兩張共享某些公共區域的圖像,目標是“縫合”它們并創建一個全景圖像場景。當然也可以是給定多張圖像,但是總會轉換成兩張共享某些公共區域圖像拼接的問題,因此本文以最簡單的形式進行介紹。
本文主要的知識點包含一下內容:
關鍵點檢測
局部不變描述符(SIFT,SURF等)
特征匹配
使用RANSAC進行單應性估計
透視變換
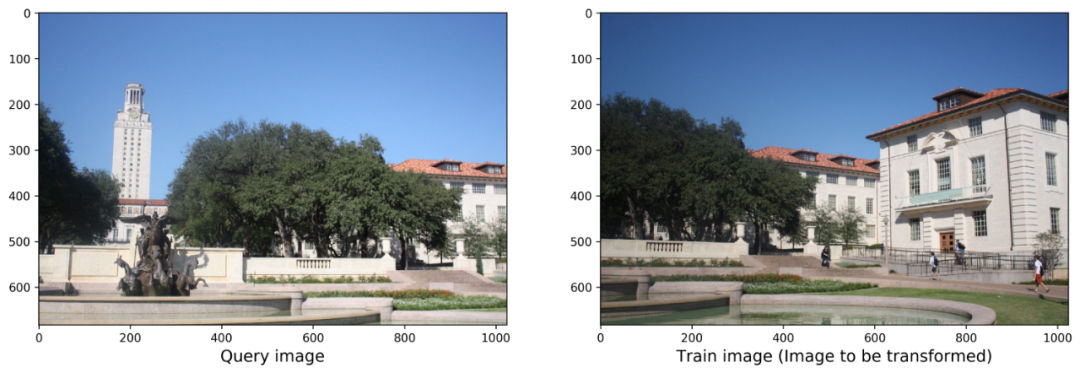
我們需要拼接的兩張圖像如下:
特征檢測與提取
給定上述一對圖像,我們希望將它們縫合以創建全景場景。重要的是要注意,兩個圖像都需要有一些公共區域。當然,我們上面給出的兩張圖像時比較理想的,有時候兩個圖像雖然具有公共區域,但是同樣還可能存在縮放、旋轉、來自不同相機等因素的影響。但是無論哪種情況,我們都需要檢測圖像中的特征點。
關鍵點檢測
最初的并且可能是幼稚的方法是使用諸如Harris Corners之類的算法來提取關鍵點。然后,我們可以嘗試基于某種相似性度量(例如歐幾里得距離)來匹配相應的關鍵點。眾所周知,角點具有一個不錯的特性:角點不變。這意味著,一旦檢測到角點,即使旋轉圖像,該角點仍將存在。
但是,如果我們旋轉然后縮放圖像怎么辦?在這種情況下,我們會很困難,因為角點的大小不變。也就是說,如果我們放大圖像,先前檢測到的角可能會變成一條線!
總而言之,我們需要旋轉和縮放不變的特征。那就是更強大的方法(如SIFT,SURF和ORB)。
諸如SIFT和SURF之類的方法試圖解決角點檢測算法的局限性。通常,角點檢測器算法使用固定大小的內核來檢測圖像上的感興趣區域(角)。不難看出,當我們縮放圖像時,該內核可能變得太小或太大。為了解決此限制,諸如SIFT之類的方法使用高斯差分(DoD)。想法是將DoD應用于同一圖像的不同縮放版本。它還使用相鄰像素信息來查找和完善關鍵點和相應的描述符。
首先,我們需要加載2個圖像,一個查詢圖像和一個訓練圖像。最初,我們首先從兩者中提取關鍵點和描述符。通過使用OpenCV detectAndCompute()函數,我們可以一步完成它。請注意,為了使用detectAndCompute(),我們需要一個關鍵點檢測器和描述符對象的實例。它可以是ORB,SIFT或SURF等。此外,在將圖像輸入給detectAndCompute()之前,我們將其轉換為灰度。
def detectAndDescribe(image, method=None):"""Compute key points and feature descriptors using an specific method"""assert method is not None, "You need to define a feature detection method. Values are: 'sift', 'surf'"# detect and extract features from the imageif method == 'sift':descriptor = cv2.xfeatures2d.SIFT_create()elif method == 'surf':descriptor = cv2.xfeatures2d.SURF_create()elif method == 'brisk':descriptor = cv2.BRISK_create()elif method == 'orb':descriptor = cv2.ORB_create()# get keypoints and descriptors(kps, features) = descriptor.detectAndCompute(image, None)return (kps, features)
我們為兩個圖像都設置了一組關鍵點和描述符。如果我們使用SIFT作為特征提取器,它將為每個關鍵點返回一個128維特征向量。如果選擇SURF,我們將獲得64維特征向量。下圖顯示了使用SIFT,SURF,BRISK和ORB得到的結果。
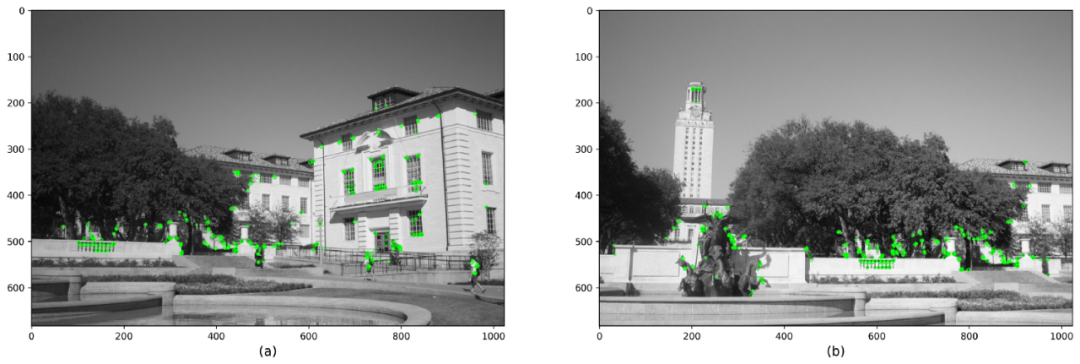
使用ORB和漢明距離檢測關鍵點和描述符
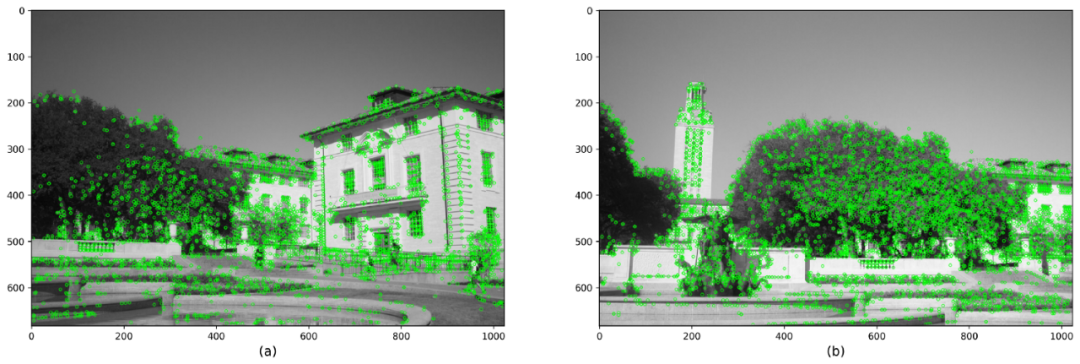
使用SIFT檢測關鍵點和描述符

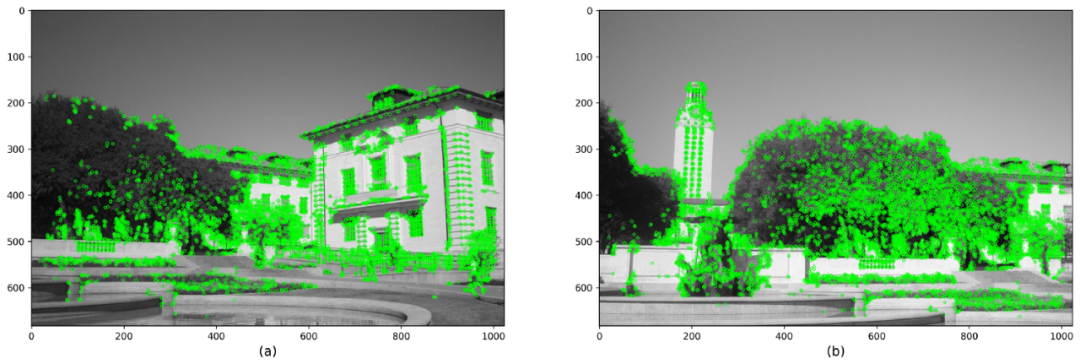
使用BRISK和漢明距離檢測關鍵點和描述符
如我們所見,兩個圖像都有大量特征點。現在,我們想比較兩組特征,并盡可能顯示更多相似性的特征點對。使用OpenCV,特征點匹配需要Matcher對象。在這里,我們探索兩種方式:暴力匹配器(BruteForce)和KNN(k最近鄰)。
BruteForce(BF)Matcher的作用恰如其名。給定2組特征(來自圖像A和圖像B),將A組的每個特征與B組的所有特征進行比較。默認情況下,BF Matcher計算兩點之間的歐式距離。因此,對于集合A中的每個特征,它都會返回集合B中最接近的特征。對于SIFT和SURF,OpenCV建議使用歐幾里得距離。對于ORB和BRISK等其他特征提取器,建議使用漢明距離。我們要使用OpenCV創建BruteForce Matcher,一般情況下,我們只需要指定2個參數即可。第一個是距離度量。第二個是是否進行交叉檢測的布爾參數。具體代碼如下:
def createMatcher(method,crossCheck):"Create and return a Matcher Object"if method == 'sift' or method == 'surf':bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=crossCheck)elif method == 'orb' or method == 'brisk':bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=crossCheck)return bf
交叉檢查布爾參數表示這兩個特征是否具有相互匹配才視為有效。換句話說,對于被認為有效的一對特征(f1,f2),f1需要匹配f2,f2也必須匹配f1作為最接近的匹配。此過程可確保提供更強大的匹配功能集,這在原始SIFT論文中進行了描述。
但是,對于要考慮多個候選匹配的情況,可以使用基于KNN的匹配過程。KNN不會返回給定特征的單個最佳匹配,而是返回k個最佳匹配。需要注意的是,k的值必須由用戶預先定義。如我們所料,KNN提供了更多的候選功能。但是,在進一步操作之前,我們需要確保所有這些匹配對都具有魯棒性。
比率測試
為了確保KNN返回的特征具有很好的可比性,SIFT論文的作者提出了一種稱為比率測試的技術。一般情況下,我們遍歷KNN得到匹配對,之后再執行距離測試。對于每對特征(f1,f2),如果f1和f2之間的距離在一定比例之內,則將其保留,否則將其丟棄。同樣,必須手動選擇比率值。
本質上,比率測試與BruteForce Matcher的交叉檢查選項具有相同的作用。兩者都確保一對檢測到的特征確實足夠接近以至于被認為是相似的。下面2個圖顯示了BF和KNN Matcher在SIFT特征上的匹配結果。我們選擇僅顯示100個匹配點以清晰顯示。
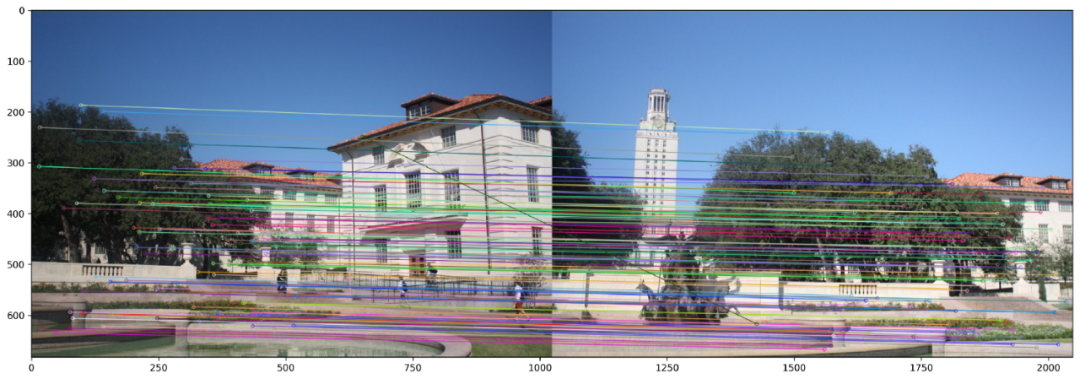
使用KNN和SIFT的定量測試進行功能匹配
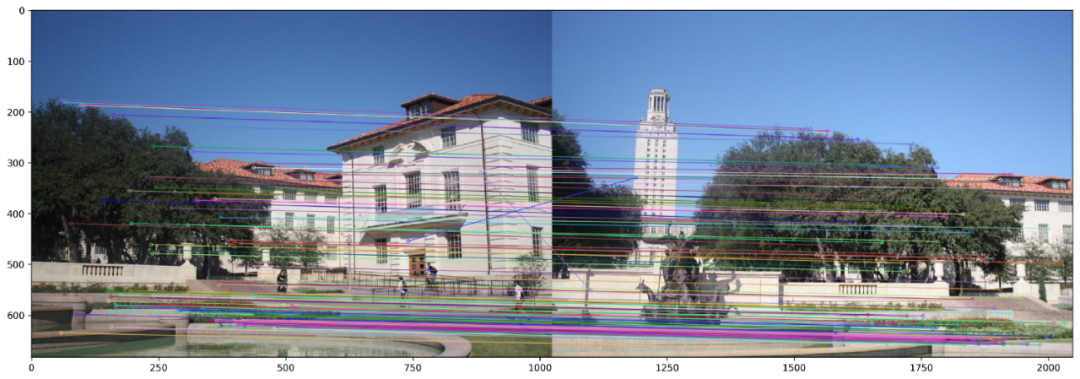
在SIFT特征上使用暴力匹配器進行特征匹配
需要注意的是,即使做了多種篩選來保證匹配的正確性,也無法完全保證特征點完全正確匹配。盡管如此,Matcher算法仍將為我們提供兩幅圖像中最佳(更相似)的特征集。接下來,我們利用這些點來計算將兩個圖像的匹配點拼接在一起的變換矩陣。
這種變換稱為單應矩陣。簡而言之,單應性是一個3x3矩陣,可用于許多應用中,例如相機姿態估計,透視校正和圖像拼接。它將點從一個平面(圖像)映射到另一平面。
隨機采樣一致性(RANSAC)是用于擬合線性模型的迭代算法。與其他線性回歸器不同,RANSAC被設計為對異常值具有魯棒性。
像線性回歸這樣的模型使用最小二乘估計將最佳模型擬合到數據。但是,普通最小二乘法對異常值非常敏感。如果異常值數量很大,則可能會失敗。RANSAC通過僅使用數據中的一組數據估計參數來解決此問題。下圖顯示了線性回歸和RANSAC之間的比較。需要注意數據集包含相當多的離群值。

我們可以看到線性回歸模型很容易受到異常值的影響。那是因為它試圖減少平均誤差。因此,它傾向于支持使所有數據點到模型本身的總距離最小的模型。包括異常值。相反,RANSAC僅將模型擬合為被識別為點的點的子集。
這個特性對我們的用例非常重要。在這里,我們將使用RANSAC來估計單應矩陣。事實證明,單應矩陣對我們傳遞給它的數據質量非常敏感。因此,重要的是要有一種算法(RANSAC),該算法可以從不屬于數據分布的點中篩選出明顯屬于數據分布的點。
估計了單應矩陣后,我們需要將其中一張圖像變換到一個公共平面上。在這里,我們將對其中一張圖像應用透視變換。透視變換可以組合一個或多個操作,例如旋轉,縮放,平移或剪切。我們可以使用OpenCV warpPerspective()函數。它以圖像和單應矩陣作為輸入。
# Apply panorama correctionwidth = trainImg.shape[1] + queryImg.shape[1]height = trainImg.shape[0] + queryImg.shape[0]result = cv2.warpPerspective(trainImg, H, (width, height))result[0:queryImg.shape[0], 0:queryImg.shape[1]] = queryImgplt.figure(figsize=(20,10))plt.imshow(result)plt.axis('off')plt.show()
生成的全景圖像如下所示。如我們所見,結果中包含了兩個圖像中的內容。另外,我們可以看到一些與照明條件和圖像邊界邊緣效應有關的問題。理想情況下,我們可以執行一些處理技術來標準化亮度,例如直方圖匹配,這會使結果看起來更真實和自然一些。






感謝各位的閱讀,以上就是“如何使用OpenCV進行圖像全景拼接”的內容了,經過本文的學習后,相信大家對如何使用OpenCV進行圖像全景拼接這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





