溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了PostgreSQL 邏輯復制學習中的深入與疑問,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
首先邏輯復制早期在 PG 10 之前是通過插件的方式來實現其功能的,在PG10合并進數據庫系統中。
邏輯復制主要解決的問題(是物理復制不能,或很難解決的問題)
1 表級別的復制
2 主從數據表的結構有條件的不一致
3 復制的數據進行過濾,僅僅復制 INSERT ,或者 UPATE 等操作
4 同cluster 中的不同庫的的數據復制到另一個庫中
如果說物理復制解決的是數據同步,數據庫高可用,讀寫分離這方面的事情。邏輯復制應該解決的是更貼近業務,或者滿足更細粒度的業務場景中的數據同步。
邏輯復制原理圖
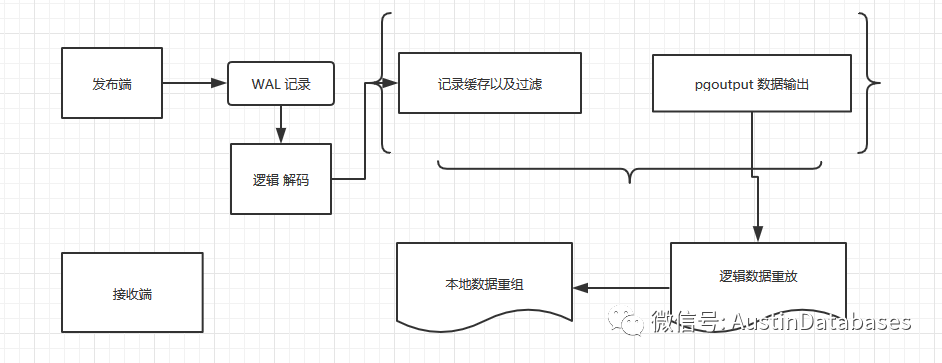
之前是有一篇邏輯復制輸出其他格式的數據的文字,在下面這張圖找到了他所處的層次和機理
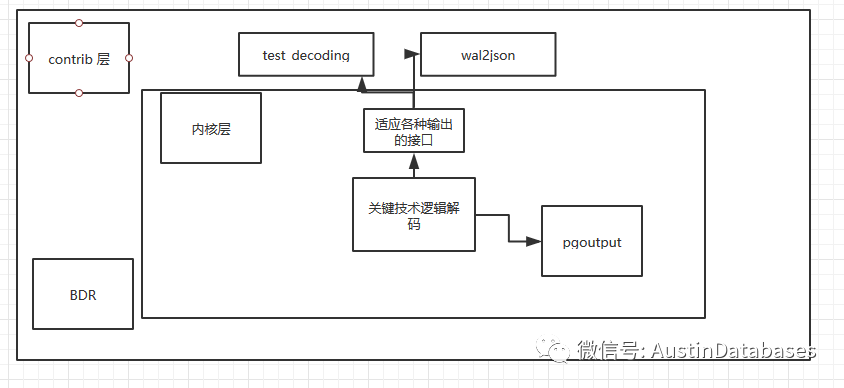
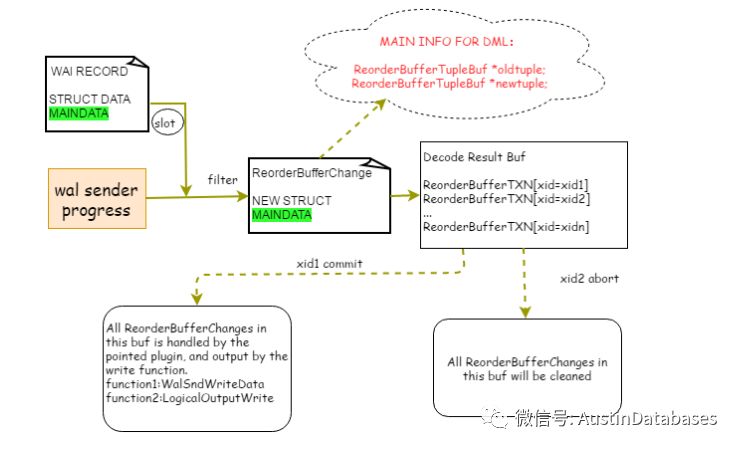
在查看文檔中,下面這張圖,其中有一點不是很理解,在解碼中 產生
tuplebuf * oldtuple 和 tuplebuf * newtuple 之間的意義在哪里
而圖中的另一個BDR,到底是什么,這里又挖掘了一下,BDR 是2quadrant 提供的一個 異步多主邏輯復制的功能。
他定義如下四個概念
Mulit-master ,asynchronous , logical , replication
他們定義的復制是將數據從一個地方復制到另一個地方的過程。在BDR中,指的是BDR不是共享存儲架構;每個節點都有自己的數據庫副本,包括所有相關索引等。節點可以滿足查詢而不需要與其他節點通信,但是還必須有足夠的存儲空間來保存數據庫中的所有數據
邏輯復制(基于行)是使用單個行值進行復制。它與發送數據塊更改的物理(基于塊的)復制形成對比。
在本地提交對一個BDR節點所做的更改之前,不會將其復制到其他節點。因此,在任何給定時間,所有節點上的數據并不完全相同;一些節點將擁有尚未到達其他節點的數據。PostgreSQL的基于塊的復制解決方案也默認為異步復制。
從上面學習和了解的情況來說,從某個層面看邏輯復制有兩個模塊
DBR + 解碼 + 解碼發送 + 外部接收 幾個部分組成。
其中我們已經知道 DBR 是哪里來的,而decording 是怎么回事,下面來說說
整體的decording 的過程,從上一次最后讀取后的LSN號對應的事務開始,從 cache 中讀取日志,如果cache 里面沒有日志會在磁盤中的日志段里面讀取獲取日志記錄,存儲到結構體 xlogrecord, 然后在 logicaldecodingprocess record 模塊中進行decode,然后進行循環將log 解析完畢。
在LogicalDecodingProcessRecord 是解析日志的關鍵,其中內存中維護一個哈希表,存放正在處理的事務信息,在處理每個日志記錄是如果遇到一個begin 操作就會在哈希表中插入相應的事務,在遇到commit 會將整個事務所有的語句進行解析,每個事務都有一個快照,每次做事務都要更新快照,等到事務commit時獲得最新的快照,f按崗位系統表,得到relation node id 與 relation name 之間關系信息,從而完成Decode,在完成Decode后,會調用 RecorderBuffercommit 函數,通過其中的 apply_change 函數將日志信息打印成可輸出的內容,最終完成整個的Decode 過程。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“PostgreSQL 邏輯復制學習中的深入與疑問”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





