溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何理解一致性hash算法和實現,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
一致性hash算法,是麻省理工學院1997年提出的一種算法,目前主要應用于分布式緩存當中。
一致性hash算法可以有效地解決分布式存儲結構下動態增加和刪除節點所帶來的問題。
在Memcached、Key-Value Store、Bittorrent DHT、LVS中都采用了一致性hash算法,可以說一致性hash算法是分布式系統負載均衡的首選算法。
常用的算法是對hash結果取余數 (hash() mod N):對機器編號從0到N-1,按照自定義的hash算法,對每個請求的hash值按N取模,得到余數i,然后將請求分發到編號為i的機器。但這樣的算法方法存在致命問題,如果某一臺機器宕機,那么應該落在該機器的請求就無法得到正確的處理,這時需要將宕掉的服務器使用算法去除,此時候會有(N-1)/N的服務器的緩存數據需要重新進行計算;如果新增一臺機器,會有N /(N+1)的服務器的緩存數據需要進行重新計算。對于系統而言,這通常是不可接受的顛簸(因為這意味著大量緩存的失效或者數據需要轉移)。
傳統求余做負載均衡算法,緩存節點數由3個變成4個,緩存不命中率為75%。計算方法:窮舉hash值為1-12的12個數字分別對3和4取模,然后比較發現只有前3個緩存節點對應結果和之前相同,所以有75%的節點緩存會失效,可能會引起緩存雪崩。
首先,我們將hash算法的值域映射成一個具有232 次方個桶的空間中,即0~(232)-1的數字空間。現在我們可以將這些數字頭尾相連,組合成一個閉合的環形。
每一個緩存key都可以通過Hash算法轉化為一個32位的二進制數,也就對應著環形空間的某一個緩存區。我們把所有的緩存key映射到環形空間的不同位置。
我們的每一個緩存節點也遵循同樣的Hash算法,比如利用IP或者主機名做Hash,映射到環形空間當中,如下圖
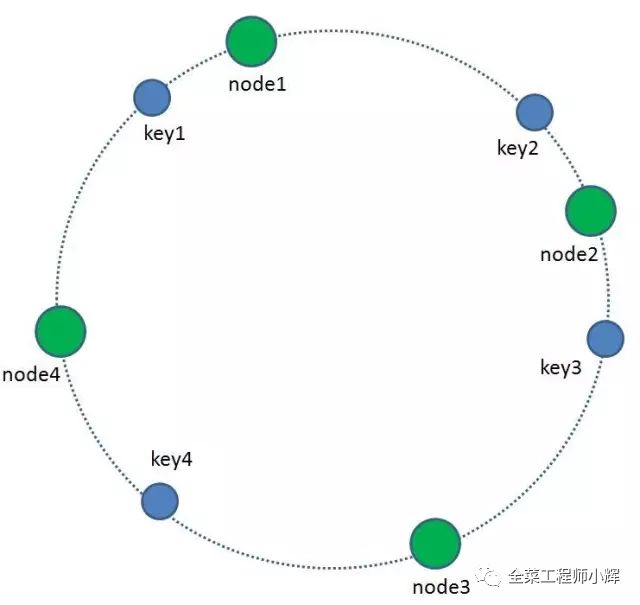
如何讓key和緩存節點對應起來呢?很簡單,每一個key的順時針方向最近節點,就是key所歸屬的緩存節點。所以圖中key1存儲于node1,key2,key3存儲于node2,key4存儲于node3。
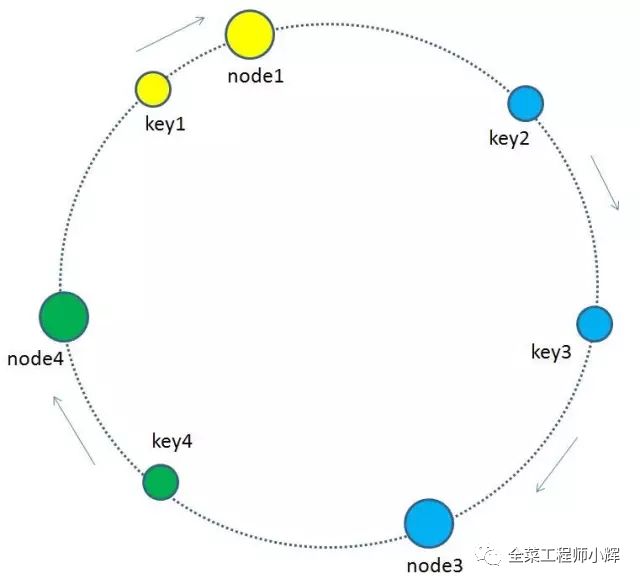
當緩存的節點有增加或刪除的時候,一致性哈希的優勢就顯現出來了。讓我們來看看實現的細節:
增加節點
當緩存集群的節點有所增加的時候,整個環形空間的映射仍然會保持一致性哈希的順時針規則,所以有一小部分key的歸屬會受到影響。
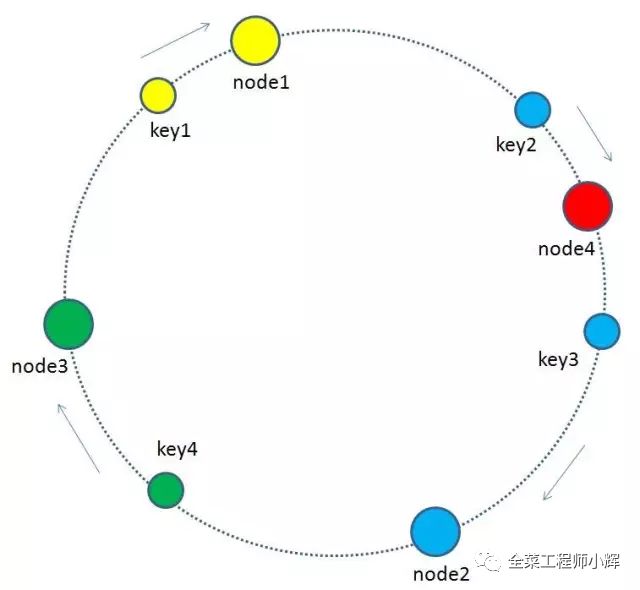
有哪些key會受到影響呢?圖中加入了新節點node4,處于node1和node2之間,按照順時針規則,從node1到node4之間的緩存不再歸屬于node2,而是歸屬于新節點node4。因此受影響的key只有key2。
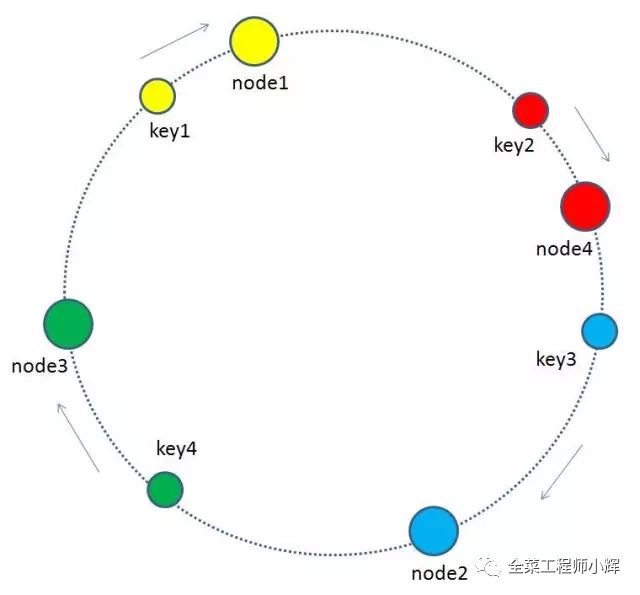
最終把key2的緩存數據從node2遷移到node4,就形成了新的符合一致性哈希規則的緩存結構。
刪除節點 當緩存集群的節點需要刪除的時候(比如節點掛掉),整個環形空間的映射同樣會保持一致性哈希的順時針規則,同樣有一小部分key的歸屬會受到影響。
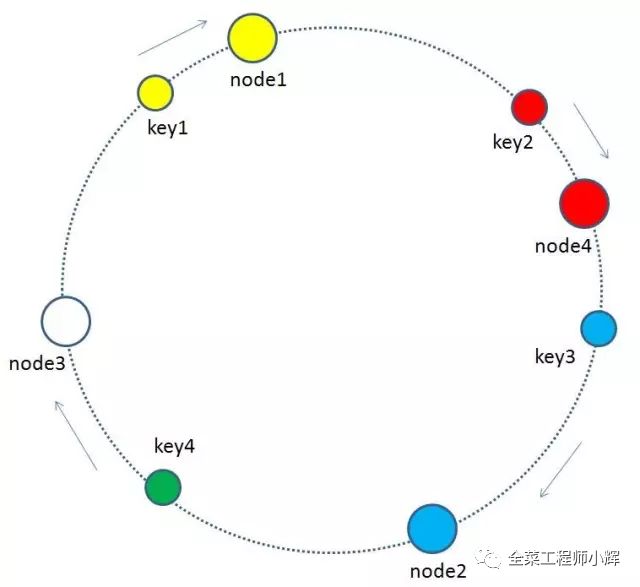
有哪些key會受到影響呢?圖中刪除了原節點node3,按照順時針規則,原本node3所擁有的緩存數據就需要“托付”給node3的順時針后繼節點node1。因此受影響的key只有key4。
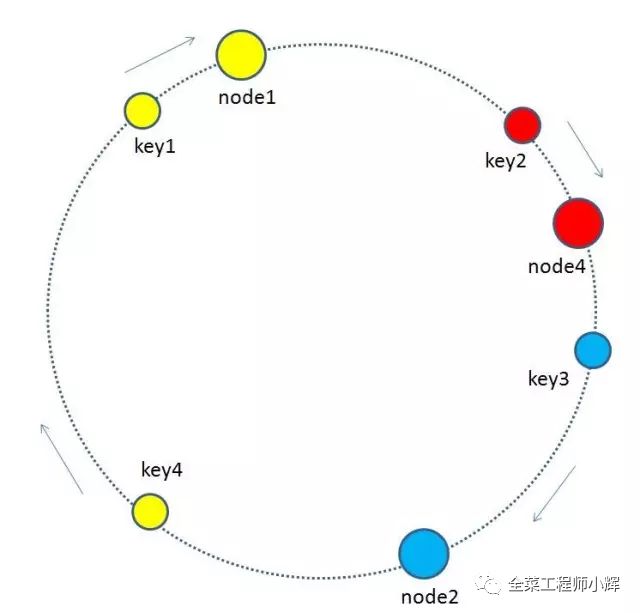
最終把key4的緩存數據從node3遷移到node1,就形成了新的符合一致性哈希規則的緩存結構。
說明:這里所說的遷移并不是直接的數據遷移,而是在查找時去找順時針的后繼節點,因緩存未命中而刷新緩存。
計算方法:假設節點hash散列均勻(由于hash是散列表,所以并不是很理想),采用一致性hash算法,緩存節點從3個增加到4個時,會有0-33%的緩存失效,此外新增節點不會環節所有原有節點的壓力。
一致性hash算法的結果相比傳統hash求余算法已經進步很多,但可不可以改進一下呢?或者如果出現分布不均勻的情況怎么辦?比如下圖這樣,按順時針規則,所有的key都歸屬于統一個節點。
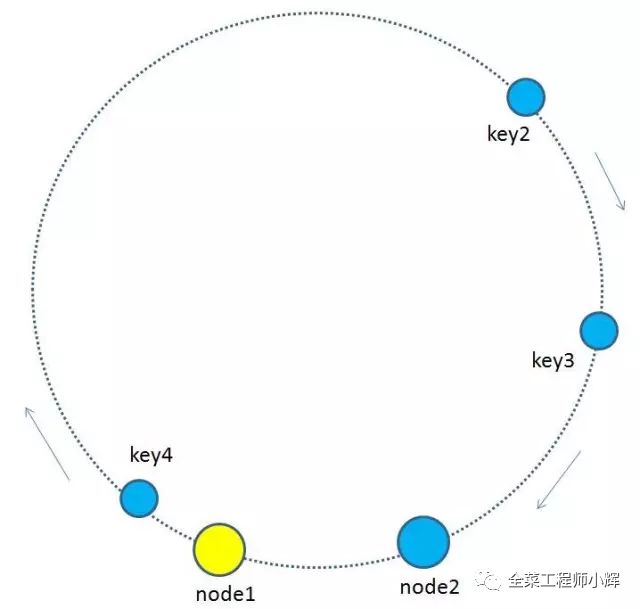
為了優化這種節點太少而產生的不均衡情況。一致性哈希算法引入了虛擬節點的概念。
所謂虛擬節點,就是基于原來的物理節點映射出N個子節點,最后把所有的子節點映射到環形空間上。
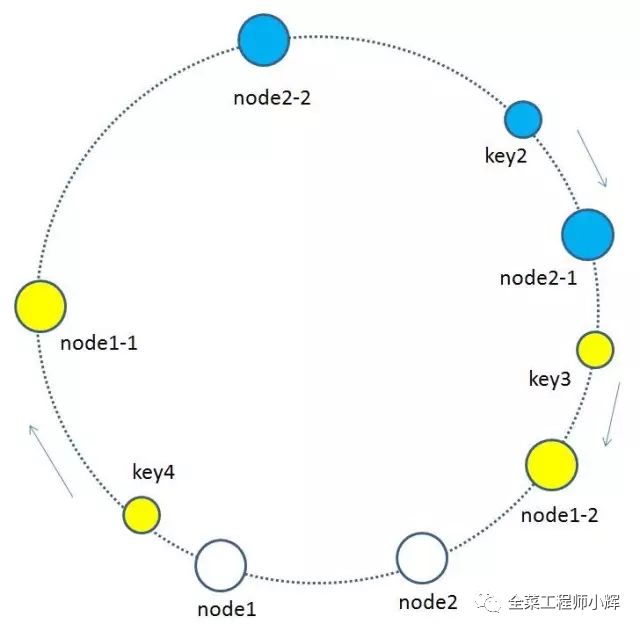
虛擬節點越多,分布越均勻。使用一致性hash算法+虛擬節點這種情況下,緩存節點從3個變成4個,緩存失效率為25%,而且每個節點都平均的承擔了壓力。
原理理解了,實現并不難,主要是一些細節:
hash算法的選擇。Java代碼不要使用hashcode函數,這個函數結果不夠散列,而且會有負值需要處理。 這種計算Hash值的算法有很多,比如CRC32_HASH、FNV1_32_HASH、KETAMA_HASH等,其中KETAMA_HASH是默認的MemCache推薦的一致性Hash算法,用別的Hash算法也可以,比如FNV1_32_HASH算法的計算效率就會高一些。
數據結構的選擇。根據算法原理,我們的算法有幾個要求:
要能根據hash值排序存儲
排序存儲要被快速查找 (List不行)
排序查找還要能方便變更 (Array不行)
另外,由于二叉樹可能極度不平衡。所以采用紅黑樹是最穩妥的實現方法。Java中直接使用TreeMap即可。
以上就是如何理解一致性hash算法和實現,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





