溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關robots.txt快速抓取網站的小竅門是什么,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
在我抓取網站遇到瓶頸,想劍走偏鋒去解決時,常常會先去看下該網站的robots.txt文件,有時會給你打開另一扇抓取之門。
寫爬蟲有很多苦惱的事情,比如:
1.訪問頻次太高被限制;
2.如何大量發現該網站的URL;
3.如何抓取一個網站新產生的URL,等等;

這些問題都困擾著爬蟲選手,如果有大量離散IP和賬號,這些都不是問題,但是絕大部分公司都不具備這個條件的。
我們在工作中寫的爬蟲大多是一次性和臨時性的任務,需要你快速完成工作就好,當遇到上面情況,試著看下robots.txt文件。
舉個栗子:
老板給你布置一個任務,把豆瓣每天新產生的影評,書評,小組帖子,同城帖子,個人日志抓取下來。
初想一下,這任務得有多大,豆瓣有1.6億注冊用戶,光是抓取個人日志這一項任務,每個人的主頁你至少每天要訪問一次。
這每天就得訪問1.6億次,小組/同城帖子等那些還沒算在內。
設計一個常規爬蟲,靠著那幾十個IP是完不成任務的。
初窺robots.txt
當老板給你了上面的任務,靠著你這一兩桿槍,你怎么完成,別給老板講技術,他不懂,他只想要結果。
我們來看下豆瓣的robots.txt
https://www.douban.com/robots.txt
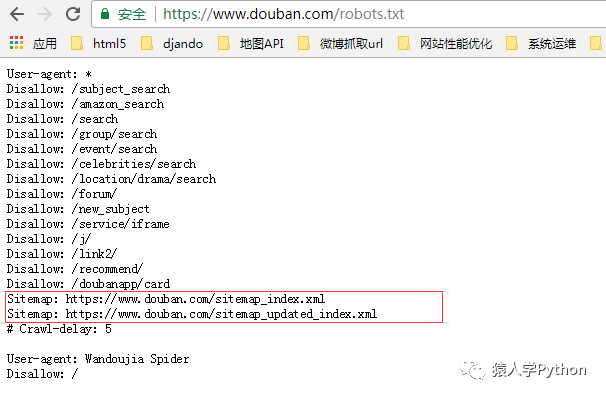
看圖片上面紅框處,是兩個sitemap文件
打開sitemap_updated_index文件看一下:
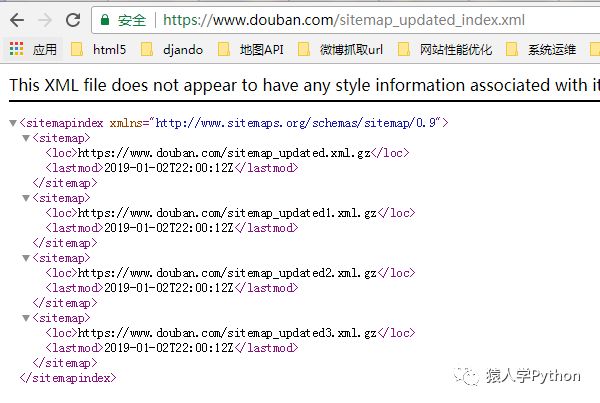
里面是一個個壓縮文件,文件里面是豆瓣頭一天新產生的影評,書評,帖子等等,感興趣的可以去打開壓縮文件看一下。
也就是說每天你只需要訪問這個robots.txt里的sitemap文件就可以知道有哪些新產生的URL。
不用去遍歷豆瓣網站上那幾億個鏈接,極大節約了你的抓取時間和爬蟲設計復雜度,也降低了豆瓣網站的帶寬消耗,這是雙贏啊,哈哈。
上面通過robots.txt的sitemap文件找到了抓取一個網站新產生URL的偏方。沿著該思路也能解決發現網站大量URL的問題。
再舉個栗子:
老板又給你一個任務,老板說上次抓豆瓣你說要大量IP才能搞定抓豆瓣每天新產生的帖子,這次給你1000個IP把天眼查上的幾千萬家企業工商信息抓取下來。
看著這么多IP你正留著口水,但是分析網站后發現這類網站的抓取入口很少(抓取入口是指頻道頁,聚合了很多鏈接的那種頁面)。
很容易就把儲備的URL抓完了,干看著這么多IP工作不飽滿。
如果一次性能找到這個網站幾萬乃至幾十萬個URL放進待抓隊列里,就可以讓這么多IP工作飽滿起來,不會偷懶了。
我們來看他的robots.txt文件:
https://www.tianyancha.com/robots.txt
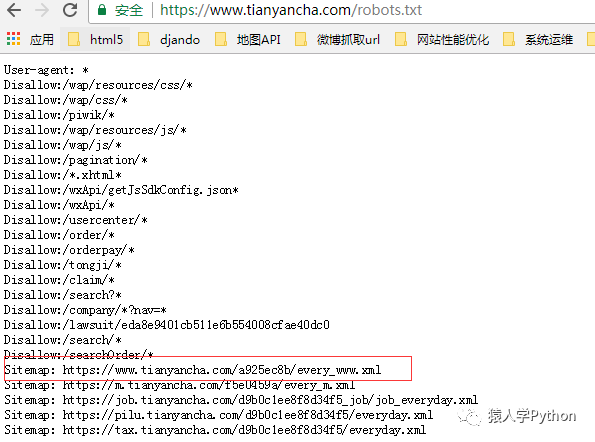
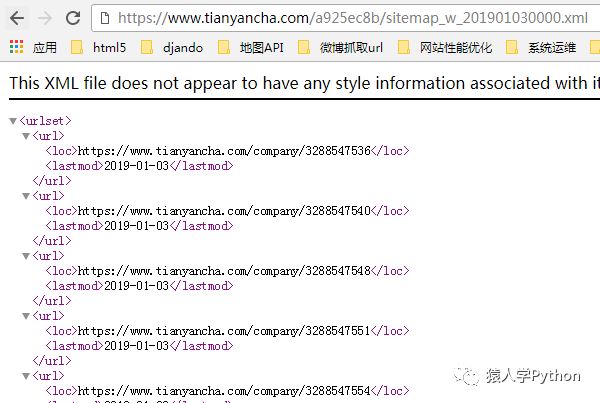
打開紅框處的sitemap,里面有3萬個公司的URL,上圖是1月3號生成的,那個URL是根據年月日生成的,你把URL改成1月2號,又能看到2號的sitemap里的幾萬個公司URL,這樣就能發現十幾萬個種子URL供你抓取了。
PS:上面的sitemap其實也能解決抓取天眼查最近更新的,新產生URL的問題。
小小的一個取巧,既降低了爬蟲設計的復雜度,又降低了對方的帶寬消耗。
看完上述內容,你們對robots.txt快速抓取網站的小竅門是什么有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





