溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何設置php禁止抓取網站?針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
php禁止抓取的實現方法:首先通過“$_SERVER['HTTP_USER_AGENT'];”方法獲取UA信息;然后將惡意“USER_AGENT”存入數組;最后禁止空“USER_AGENT”等主流采集程序即可。
我們都知道網絡上的爬蟲非常多,有對網站收錄有益的,比如百度蜘蛛(Baiduspider),也有不但不遵守robots規則對服務器造成壓力,還不能為網站帶來流量的無用爬蟲,比如宜搜蜘蛛(YisouSpider)(最新補充:宜搜蜘蛛已被UC神馬搜索收購!所以本文已去掉宜搜蜘蛛的禁封!==>相關文章)。最近張戈發現nginx日志中出現了好多宜搜等垃圾的抓取記錄,于是整理收集了網絡上各種禁止垃圾蜘蛛爬站的方法,在給自己網做設置的同時,也給各位站長提供參考。
進入到nginx安裝目錄下的conf目錄,將如下代碼保存為 agent_deny.conf
cd /usr/local/nginx/conf
vim agent_deny.conf
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA及UA為空的訪問
if ($http_user_agent ~* "FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}然后,在網站相關配置中的 location / { 之后插入如下代碼:
include agent_deny.conf;
如張戈博客的配置:
[marsge@Mars_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
location / {
try_files $uri $uri/ /index.php?$args;
#這個位置新增1行:
include agent_deny.conf;
rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后,執行如下命令,平滑重啟nginx即可:
/usr/local/nginx/sbin/nginx -s reload將如下方法放到貼到網站入口文件index.php中的第一個 <?php 之后即可:
//獲取UA信息
$ua = $_SERVER['HTTP_USER_AGENT'];
//將惡意USER_AGENT存入數組
$now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
if(!$ua) {
header("Content-type: text/html; charset=utf-8");
die('請勿采集本站,因為采集的站長木有小JJ!');
}else{
foreach($now_ua as $value )
//判斷是否是數組中存在的UA
if(eregi($value,$ua)) {
header("Content-type: text/html; charset=utf-8");
die('請勿采集本站,因為采集的站長木有小JJ!');
}
}如果是vps,那非常簡單,使用curl -A 模擬抓取即可,比如:
模擬宜搜蜘蛛抓取:
curl -I -A 'YisouSpider' zhang.ge
模擬UA為空的抓取:
curl -I -A '' zhang.ge
模擬百度蜘蛛的抓取:
curl -I -A 'Baiduspider' zhang.ge
修改網站目錄下的.htaccess,添加如下代碼即可(2種代碼任選):三次抓取結果截圖如下:

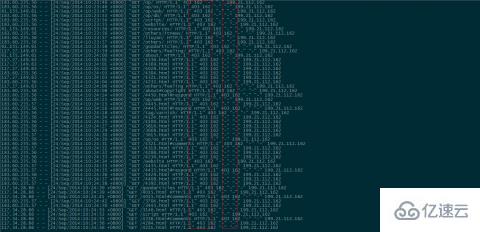
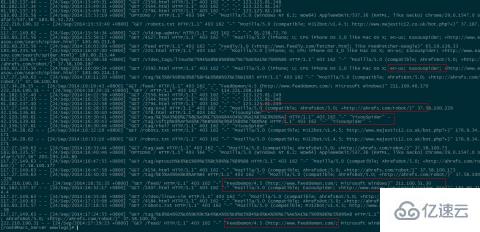
可以看出,宜搜蜘蛛和UA為空的返回是403禁止訪問標識,而百度蜘蛛則成功返回200,說明生效!
①、UA信息為空的垃圾采集被攔截:
②、被禁止的UA被攔截:
因此,對于垃圾蜘蛛的收集,我們可以通過分析網站的訪問日志,找出一些沒見過的的蜘蛛(spider)名稱,經過查詢無誤之后,可以將其加入到前文代碼的禁止列表當中,起到禁止抓取的作用。
下面是網絡上常見的垃圾UA列表,僅供參考,同時也歡迎你來補充。
FeedDemon 內容采集 BOT/0.1 (BOT for JCE) sql注入 CrawlDaddy sql注入 Java 內容采集 Jullo 內容采集 Feedly 內容采集 UniversalFeedParser 內容采集 ApacheBench cc攻擊器 Swiftbot 無用爬蟲 YandexBot 無用爬蟲 AhrefsBot 無用爬蟲 YisouSpider 無用爬蟲(已被UC神馬搜索收購,此蜘蛛可以放開!) MJ12bot 無用爬蟲 ZmEu phpmyadmin 漏洞掃描 WinHttp 采集cc攻擊 EasouSpider 無用爬蟲 HttpClient tcp攻擊 Microsoft URL Control 掃描 YYSpider 無用爬蟲 jaunty wordpress爆破掃描器 oBot 無用爬蟲 Python-urllib 內容采集 Indy Library 掃描 FlightDeckReports Bot 無用爬蟲 Linguee Bot 無用爬蟲
關于如何設置php禁止抓取網站問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





