溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
大數據這個詞也許幾年前你聽著還會覺得陌生,但我相信你現在聽到hadoop這個詞的時候你應該都會覺得“熟悉”!越來越發現身邊從事hadoop開發或者是正在學習hadoop的人變多了。作為一個hadoop入門級的新手,你會覺得哪些地方很難呢?運行環境的搭建恐怕就已經足夠讓新手頭疼。如果每一個發行版hadoop都可以做到像大快DKHadoop那樣把各種環境搭建集成到一起,一次安裝搞定所有,那對于新手來說將是件多么美妙的事情!
閑話扯得稍微多了點,回歸整體。這篇準備給大家hadoop新入門的朋友分享一些hadoop的基礎知識——hadoop家族產品。通過對hadoop家族產品的認識,進一步幫助大家學習好hadoop!同時,也歡迎大家提出寶貴意見!
一、Hadoop定義
Hadoop是一個大家族,是一個開源的生態系統,是一個分布式運行系統,是基于Java編程語言的架構。不過它最高明的技術還是HDFS和MapReduce,使得它可以分布式處理海量數據。
二、Hadoop產品
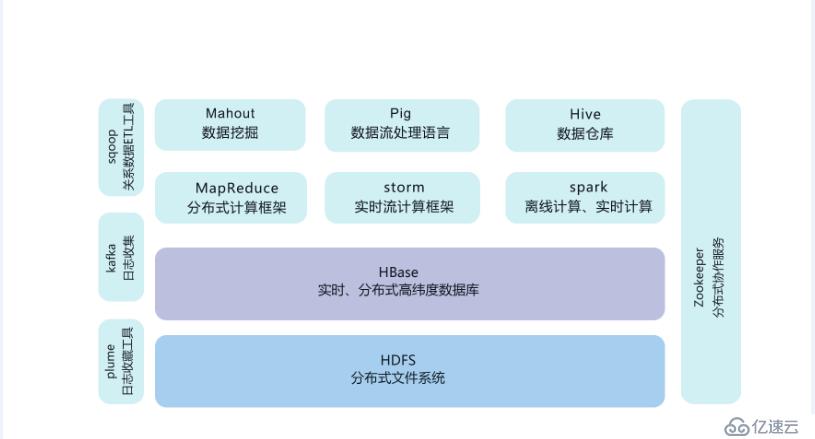
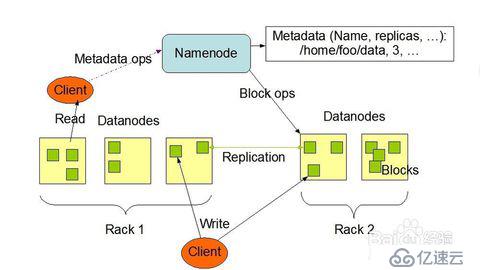
HDFS(分布式文件系統):
它與現存的文件系統不同的特性有很多,比如高度容錯(即使中途出錯,也能繼續運行),支持多媒體數據和流媒體數據訪問,高效率訪問大型數據集合,數據保持嚴謹一致,部署成本降低,部署效率提高等,如圖是HDFS的基礎架構。
MapReduce/Spark/Storm(并行計算架構):
1、數據處理方式來說分離線計算和在線計算:
角色 | 描述 |
MapReduce | MapReduce常用于離線的復雜的大數據計算 |
Storm | Storm用于在線的實時的大數據計算,Storm的實時主要是一條一條數據處理; |
Spark | 可以用于離線的也可用于在線的實時的大數據計算,Spark的實時主要是處理一個個時間區域的數據,所以說Spark比較靈活。 |
2、數據存儲位置來說分磁盤計算和內存計算:
角色 | 描述 |
MapReduce | 數據存在磁盤中 |
Spark和Strom | 數據存在內存中 |
Pig/Hive(Hadoop編程):
角色 | 描述 |
Pig | 是一種高級編程語言,在處理半結構化數據上擁有非常高的性能,可以幫助我們縮短開發周期。 |
Hive | 是數據分析查詢工具,尤其在使用類SQL查詢分析時顯示出極高的性能。可以在分分鐘完成ETL要一晚上才能完成的事情,這就是優勢,占了先機! |
HBase/Sqoop/Flume(數據導入與導出):
角色 | 描述 |
HBase | 是運行在HDFS架構上的列存儲數據庫,并且已經與Pig/Hive很好地集成。通過Java API可以近無縫地使用HBase。 |
Sqoop | 設計的目的是方便從傳統數據庫導入數據到Hadoop數據集合(HDFS/Hive)。 |
Flume | 設計的目的是便捷地從日志文件系統直接把數據導入到Hadoop數據集合(HDFS)中。 |
以上這些數據轉移工具都極大地方便了使用的人,提高了工作效率,把精力專注在業務分析上。
ZooKeeper/Oozie(系統管理架構):
角色 | 描述 |
ZooKeeper | 是一個系統管理協調架構,用于管理分布式架構的基本配置。它提供了很多接口,使得配置管理任務簡單化。 |
Oozie | Oozie服務是用于管理工作流。用于調度不同工作流,使得每個工作都有始有終。這些架構幫助我們輕量化地管理大數據分布式計算架構。 |
Ambari/Whirr(系統部署管理):
角色 | 描述 |
Ambari | 幫助相關人員快捷地部署搭建整個大數據分析架構,并且實時監控系統的運行狀況。 |
Whirr | Whirr的主要作用是幫助快速地進行云計算開發。 |
Mahout(機器學習):
Mahout旨在幫助我們快速地完成高智商的系統。其中已經實現了部分機器學習的邏輯。這個架構可以讓我們快速地集成更多機器學習的智能。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





