溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何使用scrapy框架爬取美團網站的數據,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
最近入坑爬蟲,在摸索使用scrapy框架爬取美團網站的數據
第一步,準備從地區信息開始爬,打開美團官網,點擊切換地區,按F12,點擊XHR,XHR會過濾出來異步請求,這樣我們就看大了美團的地區信息的json數據,復制該鏈接http://www.meituan.com/ptapi/getprovincecityinfo/
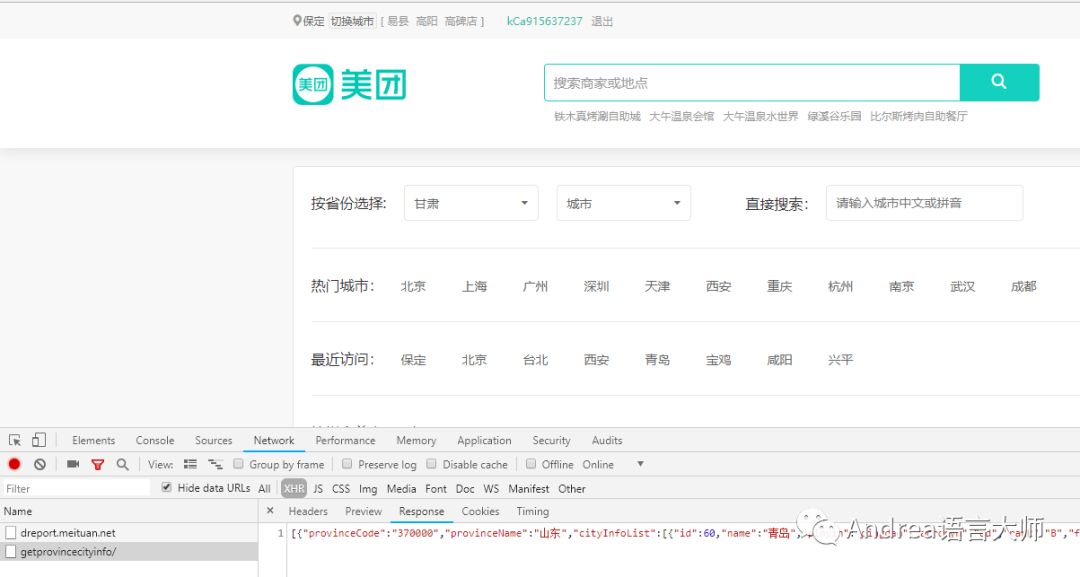

解析該json數據,會獲取到部分的地區以及區縣的信息,但這樣不利于后面的爬取,會重復爬取。我是通過過濾出來市一級的信息,然后利用頁面的中區域分類信息進行爬取。
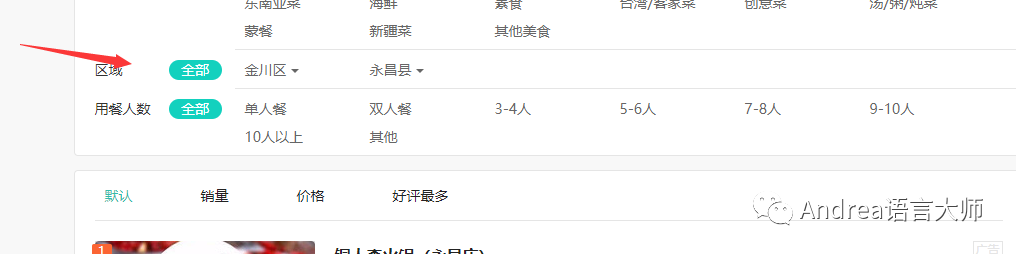
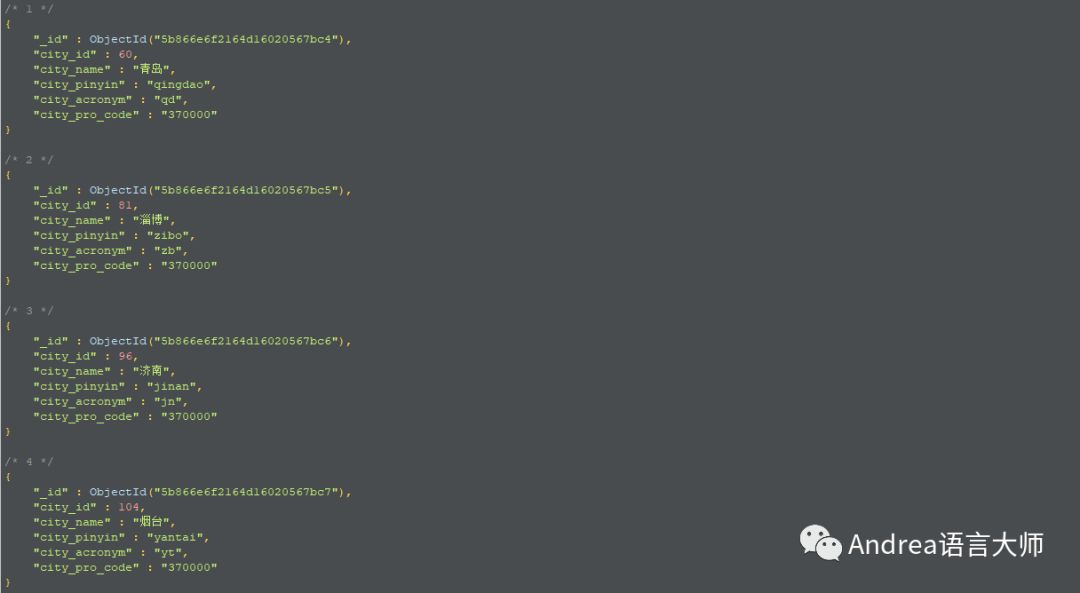
將獲取到的數據保存到MongoDB數據庫
先保存省然后是市然后區縣然后是街道,然后根據街道的url爬取數據
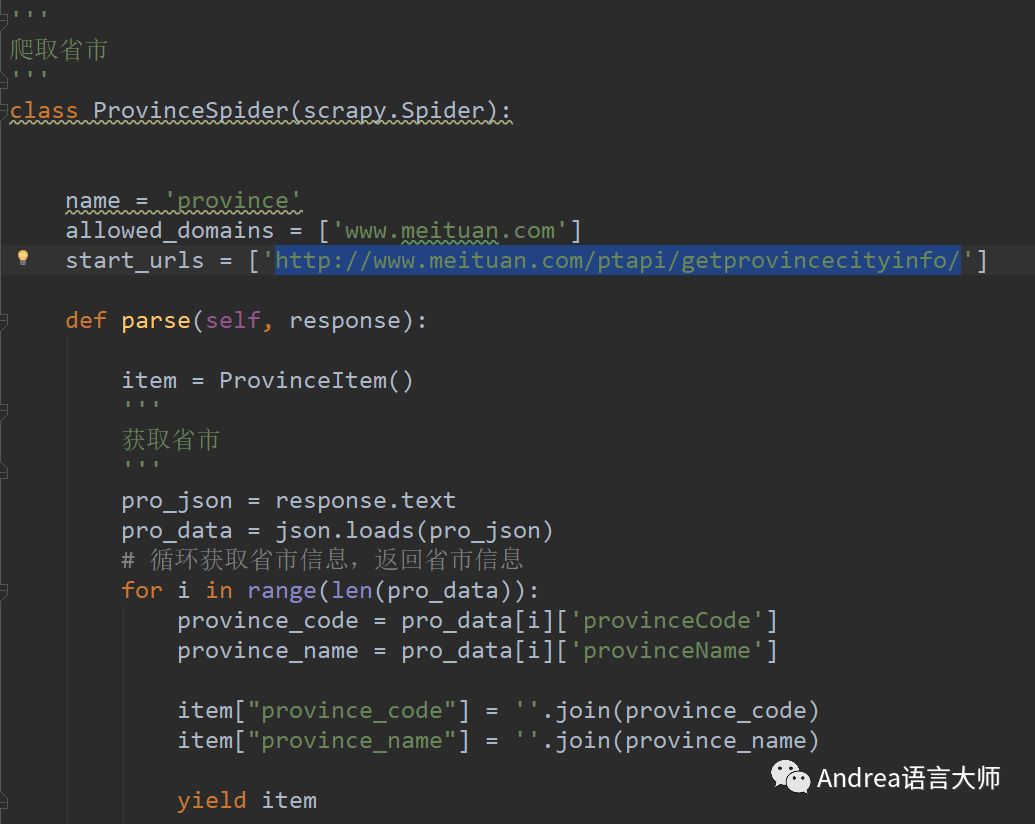
這是獲取省份以及市的代碼
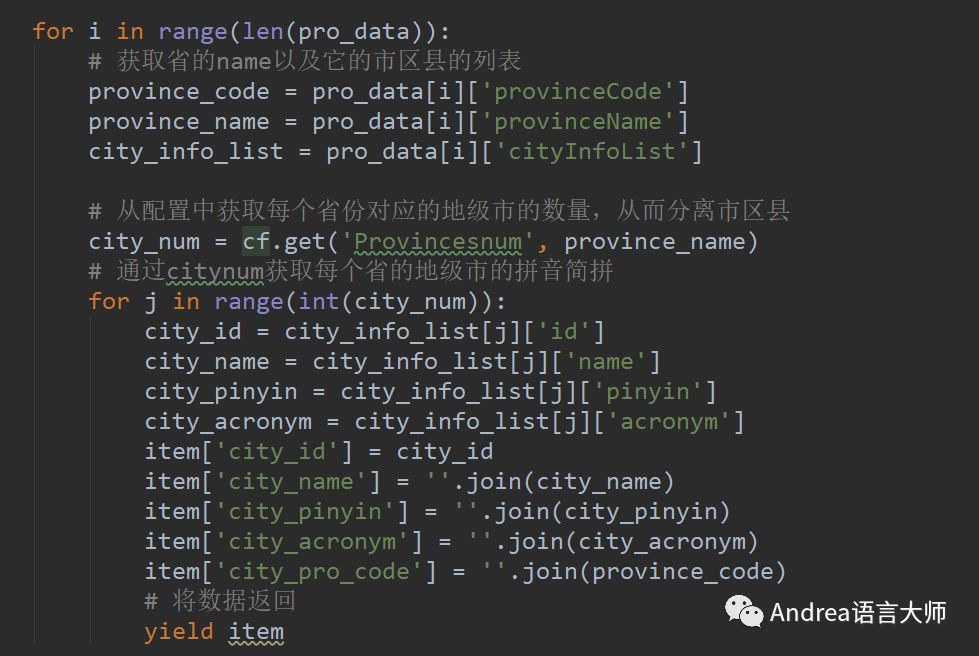
觀察獲取到的json數據后發現前面均為市一級的信息,所以通過每個省有多少個市來建立配置文件,通過配置文件來獲取。
在通過讀取配置文件的方式,過濾掉區縣,留下市一級的所有信息
讀取配置使用configparser模塊。保存到數據庫
scrapy框架遵守robot.txt規則,所以會被拒絕訪問,在setting中設置
ROBOTSTXT_OBEY = False
同事為了避免出現請求403錯誤,繼續設置setting
'''
偽造一個用戶信息,防止403
'''
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
ITEM_PIPELINES = {
'Tencent.pipelines.TencentPipeline': 300,
}
'''
防止403崩潰。
'''
HTTPERROR_ALLOWED_CODES = [403]
以上是“如何使用scrapy框架爬取美團網站的數據”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





