溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么進行RabbitMQ鏡像隊列分析,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
鏡像隊列的主要作用是用來解決隊列的單點故障。
鏡像隊列主要有兩種類型:master和slave。master和slave節點位于同一個集群中。master只要一個節點,slave可以有多個節點。
生產者發送到主節點消息會同時被發往各個slave節點,除了發送消息,其他動作只會發給master,然后通過master廣播給其他slave。
master掛掉以后,根據slave加入的時間順序排列,時間長的提升為master。
鏡像隊列的backing_queue不再使用rabbit_variable_queue。master節點的queue使用rabbit_mirror_queue_master,它內部包裹了普通backing_queue進行本地消息消息持久化處理,在此基礎上增加了將消息和ack復制到所有鏡像的功能,slave節點的queue使用rabbit_mirror_queue_slave。
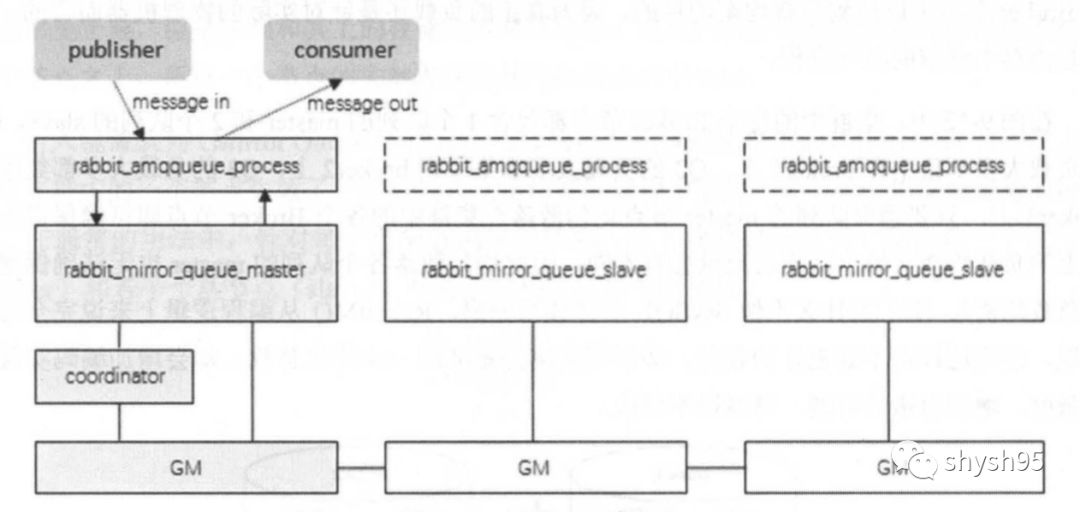
rabbit_mirror_queue_master的操作都會通過組播GM的方式同步到各個slave中。GM負責消息的廣播,rabbitmirrorqueueslave負責回調處理,而master上的回調處理是由coordinator負責完成的。如前所述,除了Basic.Publish,所有的操作都是通過master來完成的,master對消息進行處理的同時將消息的處理通過GM廣播給所有的slave,slave的GM收到消息后,通過回調交由rabbit_mirror_queue_slave進行實際的處理。
GM模塊實現的是一種可靠的組播通信協議,該協議能夠保證組播消息的原子性,即保證組中活著的節點要么都收到消息要么都收不到,它的實現大致為:將所有的節點形成一個循環鏈表,每個節點都會監控位于自己左右兩邊的節點,當有節點新增時,相鄰的節點保證當前廣播的消息會復制到新的節點上;當有節點失效時,相鄰的節點會接管以保證本次廣播的消息會復制到所有的節點。
在master和slave上的這些GM形成一個組(gm_group),這個組的信息會記錄在Mnesia中。不同的鏡像隊列形成不同的組。操作命令從master對應的GM發出后,順著鏈表傳送到所有的節點。由于所有節點組成了一個循環鏈表, master對應的GM最終會收到自己發送的操作命令,這個時候master就知道該操作命令都同步到了所有的slave上。
當master掛掉之后,會有以下連鎖反應:
與master連接的客戶端連接全部斷開。
選舉最老的slave作為新的master,因為最老的slave與舊的master之間的同步狀態應該是最好的。如果此時所有slave處于未同步狀態,則未同步的消息會丟失。
新的master重新入隊所有unack的消息,因為新的slave無法區分這些unack的消息是否己經到達客戶端,或者是ack信息丟失在老的master鏈路上,再或者是丟失在老的master 組播ack消息到所有slave的鏈路上,所以出于消息可靠性的考慮,重新入隊所有unack的消息,不過此時客戶端可能會有重復消息。
如果客戶端連接著slave,并且Basic.Consume消費時指定了x-cancel-on-ha-failover參數,那么斷開之時客戶端會收到一個Consumer Cancellation Notification的通知,消費者客戶端中會回調Consumer接口的handleCancel方法。如果未指定x-cancel-on-ha-failover參數,那么消費者將無法感知master宕機。
rabbitmqctl set_policy [-p vhost] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition}definition中需要包含3個部分:
ha-mode:指明鏡像隊列的模式,有效值為all、exactly、nodes,默認為all。all表示在集群中所有的節點上進行鏡像;exactly表示在指定個數的節點上進行鏡像,節點個數由ha-params指定;nodes表示在指定節點上進行鏡像,節點名稱過ha-params指定,節點的名稱通常類似于rabbit@hostname。
ha-params:不同的ha-mode配置中需要用到的參數。
ha-sync-mode:隊列中消息的同步方式,有效值為automatic和manual。
ha-promote-on-shutdown:加后面的講述
將新節點加入己存在的鏡像隊列時,默認情況下ha-sync-mode取值為manual。鏡像隊列中的消息不會主動同步到新的slave中,除非顯式調用同步命令。當調用同步命令后,隊列開始阻塞,無法對其進行其他操作,直到同步完成。當ha-sync-mode設置為automatic時, 新加入的slave會默認同步己知的鏡像隊列
當所有slave都出現未同步狀態,并且ha-promote-on-shutdown設置為when-synced(默認)時,如果master因為主動原因停掉,比如通過rabbitmqctl stop命令或者優雅關閉操作系統,那么slave不會接管master,也就是此時鏡像隊列不可用;但是如果master因為被動原因停掉,比如Erlang虛擬機或者操作系統崩潰,那么slave會接管master。這個配置項隱含的價值取向是保證消息可靠不丟失,同時放棄了可用性。如果ha-promote-on-shutdown設置為always,那么不論master因為何種原因停止,slave都會接管master,優先保證可用性,不過消息可能會丟失。
# 命令可以查看哪些slaves已經完成同步rabbitmqctl list_queues name slave_pids synchronised_slave_pids
# 手動同步隊列rabbitmqctl sync_queue {name}
# 取消隊列的同步操作rabbitmqctl cancel_sync_queue {name}看完上述內容,你們掌握怎么進行RabbitMQ鏡像隊列分析的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





