溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了BERT中怎么實現嵌入層,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Token嵌入
如前一節所述,token嵌入層的作用是將單詞轉換為固定維的向量表示形式。在BERT的例子中,每個單詞都表示為一個768維的向量。
假設輸入文本是“I like strawberries”。下圖描述了token嵌入層的作用:
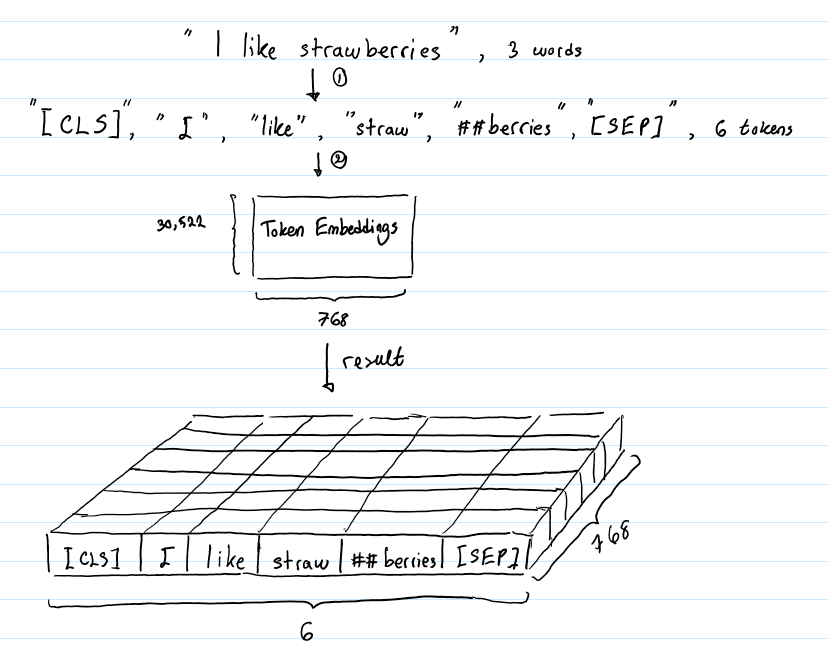
在將輸入文本傳遞到token嵌入層之前,首先對其進行token化。另外,在tokens的開始([CLS])和結束([SEP])處添加額外的tokens。這些tokens的目的是作為分類任務的輸入表示,并分別分隔一對輸入文本(更多細節將在下一節中介紹)。
tokens化是使用一種叫做WordPiece token化的方法來完成的。這是一種數據驅動的token化方法,旨在實現詞匯量和非詞匯量之間的平衡。這就是“strawberries”被分成“straw”和“berries”的方式。對這種方法的詳細描述超出了本文的范圍。感興趣的讀者可以參考Wu et al. (2016)和Schuster & Nakajima (2012)中的第4.1節。單詞token化的使用使得BERT只能在其詞匯表中存儲30522個“詞”,而且在對英語文本進行token化時,很少會遇到詞匯表以外的單詞。
token嵌入層將每個wordpiece token轉換為768維向量表示形式。這將使得我們的6個輸入token被轉換成一個形狀為(6,768)的矩陣,或者一個形狀為(1,6,768)的張量,如果我們包括批處理維度的話。
BERT能夠解決包含文本分類的NLP任務。這類問題的一個例子是對兩個文本在語義上是否相似進行分類。這對輸入文本被簡單地連接并輸入到模型中。那么BERT是如何區分輸入的呢?答案是Segment嵌入。
假設我們的輸入文本對是(“I like cats”, “I like dogs”)。下面是Segment嵌入如何幫助BERT區分這個輸入對中的tokens :
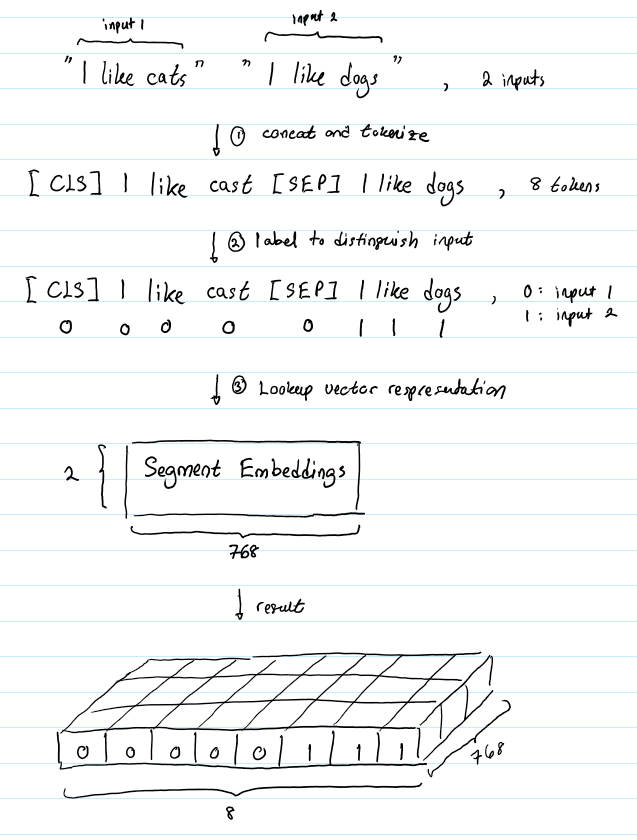
Segment嵌入層只有兩個向量表示。第一個向量(索引0)分配給屬于輸入1的所有tokens,而最后一個向量(索引1)分配給屬于輸入2的所有tokens。如果一個輸入只有一個輸入語句,那么它的Segment嵌入就是對應于Segment嵌入表的索引為0的向量。
BERT由一堆Transformers 組成的,廣義地說,Transformers不編碼其輸入的順序特征。在這個博客文章:https://medium.com/@init/how-self-attention-with-relatedposition-representations-works-28173b8c245a的動機部分更詳細地解釋了我的意思。總之,有Position嵌入將允許BERT理解給定的輸入文本,比如:
I think, therefore I am
第一個“I”不應該與第二個“I”具有相同的向量表示。
BERT被設計用來處理長度為512的輸入序列。作者通過讓BERT學習每個位置的向量表示來包含輸入序列的順序特征。這意味著Position嵌入層是一個大小為(512,768)的查找表,其中第一行是第一個位置上的任意單詞的向量表示,第二行是第二個位置上的任意單詞的向量表示,等等。因此,如果我們輸入“Hello world”和“Hi there”,“Hello”和“Hi”將具有相同的Position嵌入,因為它們是輸入序列中的第一個單詞。同樣,“world”和“there”的Position嵌入是相同的。
我們已經看到,長度為n的token化輸入序列將有三種不同的表示,即:
對這些表示進行元素求和,生成一個形狀為(1,n, 768)的單一表示。這是傳遞給BERT的編碼器層的輸入表示。
上述內容就是BERT中怎么實現嵌入層,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





