溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Apache Kafka服務端設計理念是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
下面簡單介紹了Apache Kafka服務端的一些設計。
Kafka被設計出來的目標是作為海量實時數據傳輸的分布式數據流平臺,主要用來傳輸和聚合日志數據、追蹤網站活動、傳輸監控數據和作為消息隊列等。為了滿足這些功能,Kafka需要具有如下特性:
高吞吐
作為海量數據的傳輸平臺,Kafka需要極大的吞吐量來保證海量數據的傳輸。
低延遲
實時數據處理最重要的指標之一就是延遲,需要低延遲來保證它作為消息隊列時的性能。
高可用
為了避免服務器故障、JVM崩潰等問題帶來的數據丟失情況,需要具備較好的容錯性。
多次消費
據統計,在LinkedIn公司內Kafka中的每條消息平均要被消費5次以上。為了支持海量數據的可重復消費,Kafka需要很大的容量。
為了實現這些特性,Kafka使用了相當多的”黑科技“。下面讓我們一一解讀一下。
可以說,Kafka是重度依賴文件系統的,它會把所有的數據寫入到硬盤上。可是按照我們平時的理解,對硬盤的讀寫不是很慢么?其實還真不一定。要理解影響硬盤讀寫速度的因素,首先我們要了解硬盤的結構。
首先,我們來看一張硬盤的結構圖:

磁盤結構圖1,圖片來源于網絡
如上圖所示,磁盤主要由磁盤盤片、傳動手臂、讀寫磁頭和主軸組成。為了更好的利用盤片資源,每張盤片的兩面都可以記錄信息,所以每張盤片會對應上下兩個磁頭讀寫數據。由于單張盤片能存儲的數據量有限,所以一般磁盤都有多個盤片。盤面被分為許多扇形區域,稱為扇區。圍繞著盤面中心的不同半徑的同心圓被稱為磁道。不同盤片間相同半徑的磁道組成的圓柱體稱為柱面。如下圖所示:
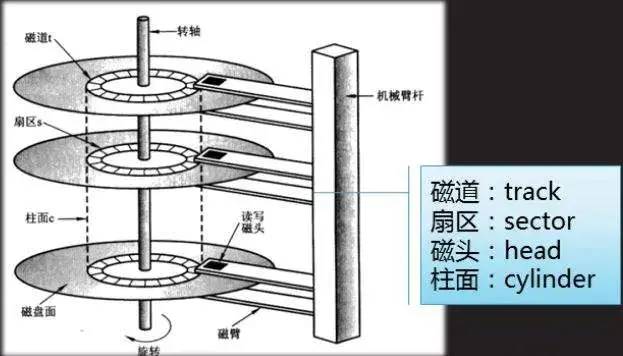
磁盤結構圖2,圖片來源于網絡
磁盤中的數據全部存儲在磁盤的盤片上面,讀取數據時轉動主軸到指定位置,轉動手臂進行伸展,最后由讀寫磁頭完成實際的讀寫操作。那么為什么大家會覺得硬盤的讀寫很慢呢?因為一次硬盤IO需要以下三個步驟:
尋道
磁盤要想讀寫數據,首先要找到正確的磁道。讀寫磁頭移動到需要被讀寫的磁道上的時間被稱為尋道時間。
旋轉
旋轉、跳躍,磁盤閉著眼。要想讀寫數據,光找到正確的磁道還不夠,硬盤要通過主軸的旋轉找到正確的扇區。磁盤通過旋轉找到正確扇區的時間被稱為旋轉延遲。我們平時經常聽到的這種磁盤7200轉,那種磁盤15000轉,指的就是磁盤的轉速(每分鐘能轉多少圈)。轉的越快,旋轉延遲越短,IO速度越快。
數據傳輸
到這里才是數據才能真正進行讀寫。數據傳輸的速度很快,好一些的磁盤通常能達到百兆甚至幾百兆每秒。
看到這里我們知道了,一次完整的磁盤IO時間實際上為:
尋道時間 + 旋轉延遲 + 數據傳輸時間
一般的磁盤操作,絕大部分的時間花在了前兩個步驟上。也就是說,對磁盤進行順序讀寫很快(因為基本不用進行前兩個步驟),而隨機讀寫就很慢了。根據Kafka官方給出的數據,在7200rpm/s的SATA RAID-5磁盤陣列上進行順序寫入速度達到600MB/sec,而隨機寫入大概只有100KB/sec,相差了6000倍!而Kafka正是使用了順序讀寫,才能獲得如此高的性能。
如果僅僅使用順序讀寫,那么Kafka也不會有現在這么好的性能。事實上,Kafka充分利用了現代操作系統中的文件緩存系統。
在現代操作系統中,為了彌補硬盤寫入的速度的不足,系統越來越激進的使用內存作為文件系統的緩存,甚至會使用所有空閑的內存作為磁盤緩存(即page cache)。Page cache提供了預讀和回寫功能。簡單來說,預讀就是當順序讀取文件內容時,page cache會提前將當前讀取頁面之后的幾個頁面也加載到page cache當中,這樣程序相當于直接讀取cache中的內容,而不必直接與磁盤交互。回寫就是當磁盤進行寫入時,會寫入到page cache當中,由操作系統在恰當的時候再寫入磁盤。很多人不知道的是,所有我們的常規IO操作全部都要經過page cache,這個特性是在操作系統層面決定的,很難取消掉。
有了page cache,一切看起來都很美好。可實際情況是,這里面仍然存在一些問題。首先,當我們使用常規方式讀取文件內容時,系統內核必須將page cache中的文件內容復制到user buffer中。這不僅浪費了CPU時間,而且還將導致系統的物理內存中出現兩份數據,浪費了物理內存空間。另外,由于Kafka是構建在JVM上的,對于JVM比較了解的同學都會知道這樣兩條規律:
JVM對象消耗的內存非常大,經常會達到實際數據的兩倍甚至更多。
隨著數據量的增長,JVM的垃圾回收將會越來越慢,甚至不可忍受。
所以基于以上考慮,Kafka并沒有使用常規的磁盤操作,而是使用了Memory-mapped files。當使用Memory-mapped files時,系統內核會將程序的virtual memory直接映射到page cache,使我們可以把文件數據當做內存數據一樣操作。這樣不僅避免了數據在內核空間和用戶空間之間復制,也避免了使用java對象帶來的一些問題,從而極大提高了Kafka讀寫效率。在java的NIO中提供了使用memory-mapped files的api,即MappedByteBuffer(繼承自ByteBuffer),感興趣的同學可以去深入研究。關于page cache和memory-mapped files,可以閱讀這篇博客:Page Cache, the Affair Between Memory and Files。
按照前兩節所講述的,我們使用順序讀寫最大化磁盤性能;使用page cache和高效的memory-mapped files,避免對磁盤進行直接操作。按道理來講,性能上應該非常出色了。但是盡管如此,還是有兩個問題影響著系統的性能:頻繁的小數據量網絡IO操作和過多的字節拷貝。
為了避免頻繁的網絡往返帶來的性能開銷,Kafka將消息組合在一起形成一個“消息集”。使用這種方式可以將消息分批發送,而不是單條發送,從而分攤了網絡往返的開銷。當數據量巨大的時候,這種方式可以極大的提升網絡IO的性能。Kafka的生產者和消費者都是采用這種方式向Kafka發送數據和從Kafka拉取數據的。
接下來我們來介紹一下zero-copy。Kafka使用了Linux的系統調用sendfile來發送系統中的消息,為了了解sendfile系統調用帶來的優勢,我們先來了解一下通過socket發送數據的傳統方式:
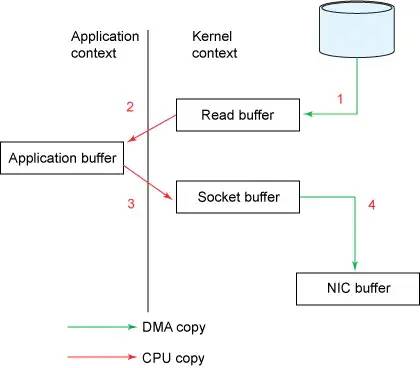
傳統數據發送方式,圖片來源于網絡
由上圖我們可以看到,如果要將磁盤上的數據發送出去,需要經過以下四個步驟:
操作系統從磁盤讀取數據,并寫入到內核空間的page cache中。
應用程序從內核空間讀取數據,并復制到用戶空間中。
應用程序將用戶空間中的數據寫回到內核空間的socket緩沖中去。
操作系統將socket緩沖中的數據復制到網卡緩沖中,并經過網卡發送出去。
可以看到這種傳統發送數據的方式經過了四次數據復制和兩次系統調用,效率很差。那么使用sendfile系統調用后是什么情況呢?
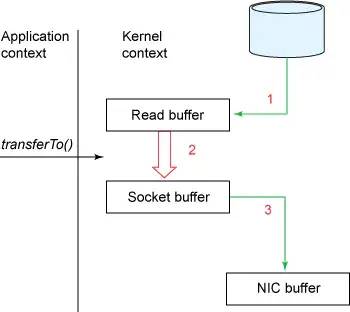
sendfile數據發送方式,圖片來源于網絡
從圖中我們可以看到,使用sendfile可以直接從page cache復制數據到網卡緩沖,避免了不必要的系統調用和數據復制,非常高效。
由于Kafka的一個topic往往有多個消費者組在消費,所以采用zero-copy的方式,讓數據只從磁盤讀取到page cache一次,就可以服務所有的消費了。通過使用page cache和sendfile,在消費者消費Kafka中數據的時候,磁盤幾乎沒有任何讀取活動,全部的數據都來自于page cache中。
在java中,java.nio.channels.FileChannel類提供了transferTo()方法來實現zero copy(當然還取決于操作系統,在Unix和多數Linux上transferTo()方法會進行sendfile系統調用)。
很多時候,數據傳輸的性能瓶頸不在于CPU或硬盤,而在于網絡帶寬。這種情況在遠距離的公網傳輸中最為常見。為了解決這個問題,Kafka提供了端到端的批量壓縮功能。雖然用戶也可以對每條消息自行壓縮,但是一些數據格式可能導致單條壓縮的壓縮比較低。舉例來說,在一批JSON數據中,字段名稱其實是重復的,單條壓縮會造成很多冗余。
而Kafka把一批消息抽象為“消息集”(上節講到過),producer對數據集進行壓縮,這些數據將會以被壓縮的格式傳輸到服務器并寫入到數據日志中,只有當消費者讀取這些數據后它們才會被解壓縮。Kafka目前支持GZIP,Snappy和LZ4壓縮方式。
Kafka使用ISR機制來保證系統的高可用。在創建topic時,我們可以通過設置replication-factor參數來控制topic的復制因子(之后通過Kafka提供的工具也可以動態改變這個參數)。比如在下面創建topic的語句中:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 5 --topic test
我們設置了 replication-factor 為3,即有三個副本。副本的作用就是當集群中的某個服務器發生故障時,系統可以自動使用其他服務器上的副本提供服務,不會影響到消息的生產和消費。
副本的單位是partition。每個partition會有一個leader,零或多個follower。所有leader和follower的數量加在一起就是replication-factor參數的值。比如上面設置了replication-factor為3,那么這個topic中的每個partition就有1個leader和2個follower。在對topic的partition進行讀寫時,所有的讀寫操作都會去直接請求leader,follower只是被動的去同步leader中的消息。而follower中的消息,不論是消息的順序還是offset全部與leader相同。當然,由于消息先被寫入leader,follower再去拉取數據,所以同步上會存在很小一段時間的延遲。
與一般的分布式系統不同,Kafka沒有使用“alive”或者“failed”來標志副本的存活情況,而是使用了一個新的概念:“in-sync”。所有在“in-sync”狀態的replication(副本)構成了這個partition的“同步副本隊列”,即ISR。那么Kafka如何判斷一個replication是否在“in-sync”狀態下呢?
副本所在的節點必須持有 Zookeeper的session。
副本復制leader上寫入消息的位置不能“落后太多”。
如果違反了其中任意一條,那么這個副本會被暫時移出ISR隊列,當它重新滿足這兩條要求時,又會被加入進來。當然,如果leader掛掉,那么會有一個follower被選舉成為新的leader,為partition的讀寫提供服務。使用命令:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-topic
可以看到此topic下每個partition的replicas和ISR情況。
上述就是小編為大家分享的Apache Kafka服務端設計理念是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





