溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行HashMap的部分源碼剖析,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
HashMap基于哈希表的 Map 接口的實現。此實現提供所有可選的映射操作,并允許使用 null 值和 null 鍵。(除了不同步和允許使用 null 之外,HashMap 類與 Hashtable 大致相同。)此類不保證映射的順序,特別是它不保證該順序恒久不變。HashMap的結構如下:
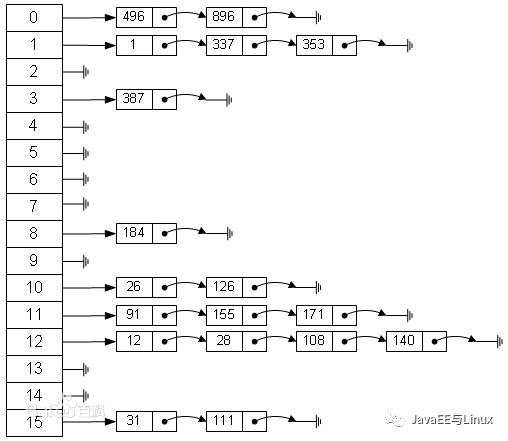
我們可以看到HashMap的結構主要分為兩大部分:左側的table和右側的鏈表,下面重點分析HashMap的源碼。


(1)、final int hash(Object k),此方法用來計算key的哈希值,由方法最后的幾行可以看到,為了保證key的均勻散列,并沒有使用hashCode%length的方法,因為移位運算符不僅可以更均勻的散列而且勻速速度也比hashCode%length更快。
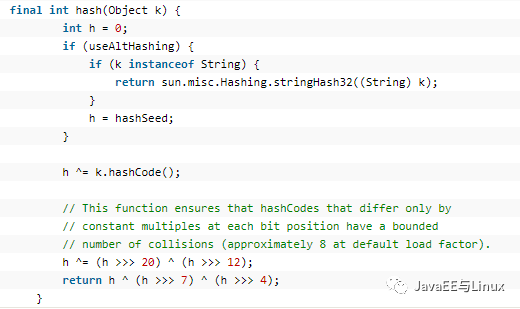
(2)、public V get(Object key)
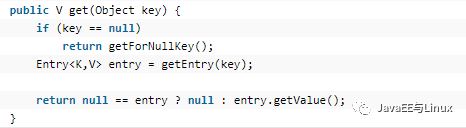
我們看到,get方法首先判斷key是否為null,如果為null,則調用getForNullKey(),否則調用getEntry(key)方法獲取value,讓我們來繼續分析getForNullKey的源碼:
private V getForNullKey()
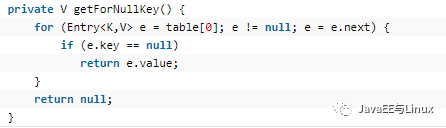
可見:循環遍歷table[0]的那個鏈表,直到找到key==null的Entry,否則返回null;為什么是table[0]呢?因為在put的時候如果key==null,直接將entry存儲在table[0]的位置,我們在后面分析put方法。接下來再分析getEntry(key)方法:
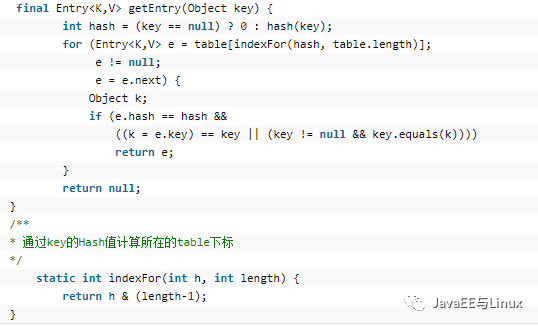
通過key的Hash值計算Entry所在table的小標,請注意計算下標的方法通過indexFor()方法得到,然后遍歷Entry,直到找到hash和equals都相等的Entry后返回,否則返回null;
好了,get方法基本就是這樣,接下來我們一起來分析put方法。
(3)、 public V put(K key, V value)

put方法的大致流程是:
①、首先判斷key是否為null,如果為null,調用putForNullKey(value)方法,請大家注意,putForNullKey和上面的getForNullKey的邏輯是一一對應的哦。
②、計算key的Hash值,通過indexFor()方法定位到元素存儲在table的位置table[i]。
③、循環遍歷table[i],如果新值和舊值相等,覆蓋舊值后返回舊值
④、modCount++,操作次數+1,調用addEntry將新值插入到鏈表。
讓我們來分析putForNullKey(value)方法源碼:

請看,這里又是table[0],和getForNullKey中的table[0]對稱,遍歷-->新值覆蓋舊值-->返回舊值-->操作數+1-->插入新元素,很容易理解。
接下來重點來了,讓我們來分析addEntry方法中的一系列邏輯:

首先,threshold=capacity * load factor,也就是臨界值=容量*加載因子=16*0.75f, map中使用量超過threshold,會擴容為原來的2倍。resize是一個非常復雜的過程,涉及到rehash等,后面我在介紹,現在咱們重點看addEntry()。bucketIndex是元素存儲在table的下標,也就是將元素存儲在table[bucketIndex]。最后調用createEntry將新元素存儲在HashMap中,createEntry的源碼如下:

通過new Entry(hash,key,value,e),將新元素插到table[bucketIndex]中,我們來看Entry的構造方法:

重點在next = n這行,看到到插入元素到鏈表中使用的頭插法,不用尾插的目的估計是為了節省遍歷鏈表的開銷吧。
好了,put方法就是這樣,其實也特別好理解,接下來我們來分析Entry這類。
HashMap有一個變量:transient Entry<K,V>[] table,可以看到table是一個Entry的數組,并且Entry本身是一個鏈表的一個元素。Entry<K,V> implements Map.Entry<K,V>,而Map.Entry是一個接口。Entry包含四個元素,final K key; V value; Entry<K,V> next;int hash;hash是這個元素的hash值,其余的三個元素就不解釋了。Entry類的方法基本上都很簡單,大家可以通過閱讀源碼來理解,我重點解釋一下equals和hashCode這兩個方法,源碼如下:
 比較連個Entry是否相等就是通過if中的條件,比較容易理解,hashCode源碼:
比較連個Entry是否相等就是通過if中的條件,比較容易理解,hashCode源碼:

最后,重點分析rehash方法,在分析rehash時,我先解釋一下什么是rehash:當我們的HashMap的使用量超過了threshold=capacity * load factor,也就是臨界值=容量*加載因子=16*0.75f,就會發生rehash,將容量擴大為原來的兩倍,然后所有的元素根據新的hash規則重新散列到不同的table[i]中。但是rehash有很大的性能消耗,所以如果我們在使用HashMap時能預測到元素的個數,最好在構造時就指定HashMap的大小。rehash的源碼如下:
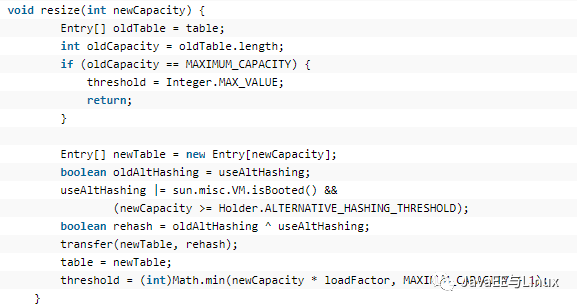
Entry[] newTable = new Entry[newCapacity],常見一個新的table,很消耗內存的!!!前面容易理解,重點看transfer方法,這個方法才是將元素重新散列的方法,源碼如下:
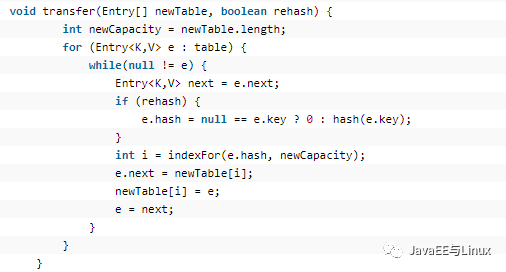
循環遍歷table(舊數組),計算出newTable的下標,將舊元素e存儲到newTable中,這里有一個細節要注意,在我講put方法時提到過,插入元素的方法時頭插法,就是新的元素被添加到鏈表的頭部,但我們通過transfer方法可分析出:在rehash的時候,之前在頭部的元素會先進行rehash,在尾部的元素會最后rehash,所以當rehash結束后,之前在頭部的元素會沉到尾部,之前在尾部的元素會上升到頭部。
關于如何進行HashMap的部分源碼剖析問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





