溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“python模型優化實例分析”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“python模型優化實例分析”吧!
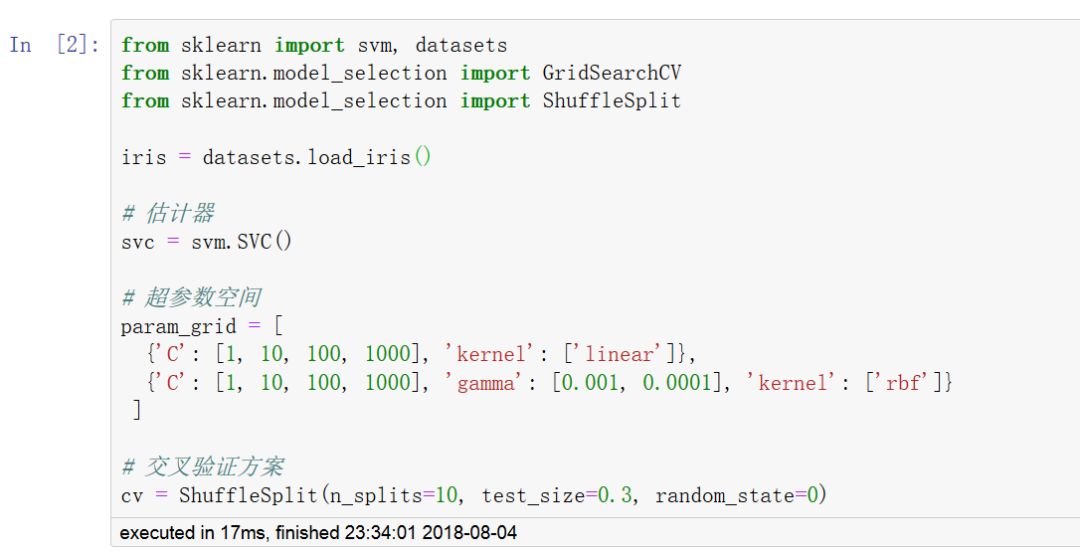
超參數是不直接在估計器內學習的參數。在 scikit-learn 包中,它們作為估計器類中構造函數的參數進行傳遞。典型的例子有:用于支持向量分類器的 C 、kernel 和 gamma ,用于Lasso的 alpha 等。
搜索超參數空間以便獲得最好 交叉驗證 分數的方法是可能的而且是值得提倡的。
搜索超參數空間以優化超參數需要明確以下方面:
估計器
超參數空間
交叉驗證方案
打分函數
搜尋或采樣方法(網格搜索法或隨機搜索法)
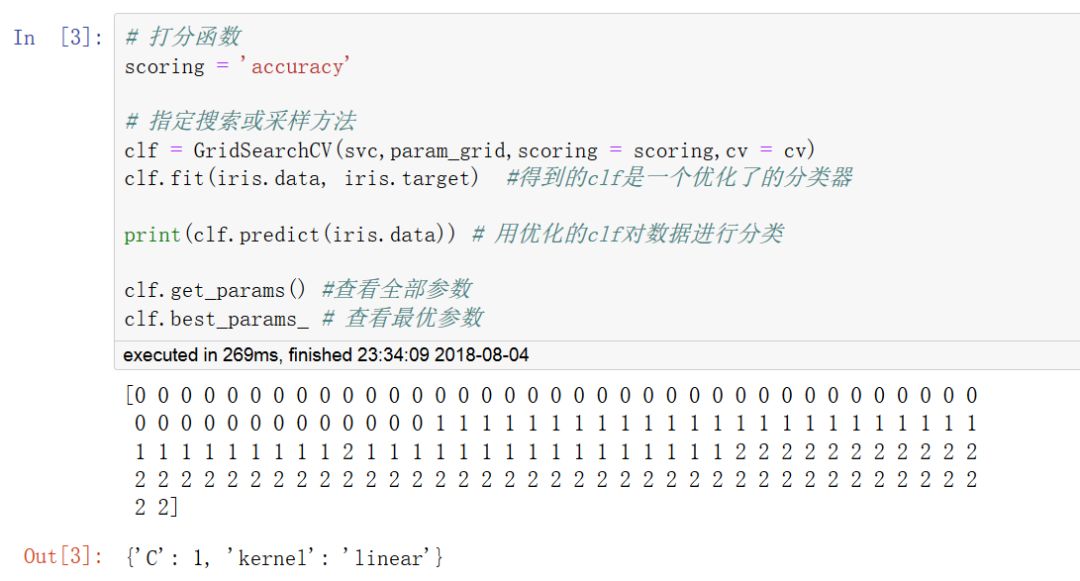
優化模型的常見方法包括 網格搜索法,隨機搜索法,模型特定交叉驗證,信息準則優化。
網格搜索法在指定的超參數空間中對每一種可能的情況進行交叉驗證評分并選出最好的超參數組合。
使用網格搜索法或隨機搜索法可以對Pipeline進行參數優化,也可以指定多個評估指標。
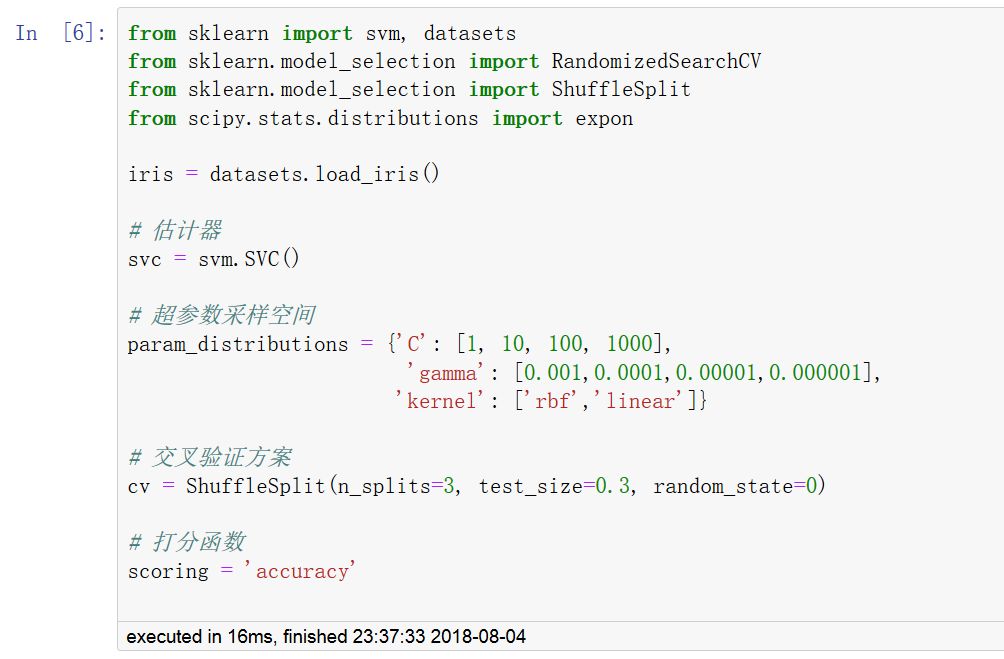
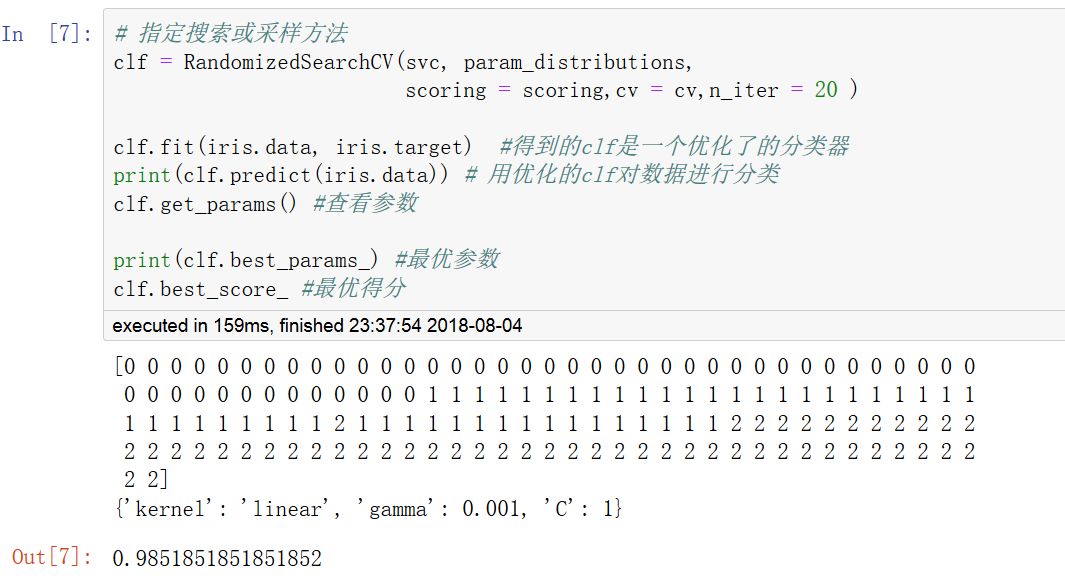
二,隨機搜索法
RandomizedSearchCV
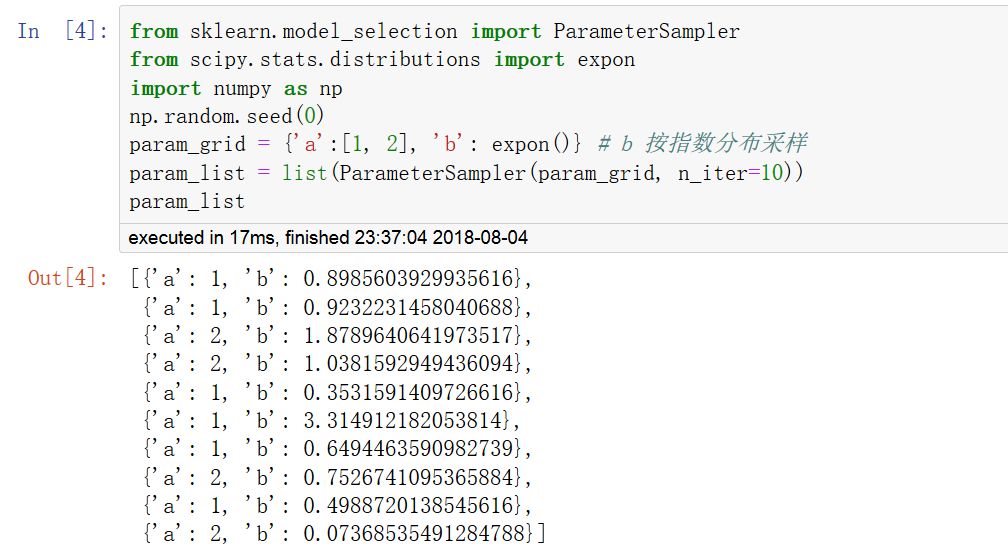
隨機搜索法和網格搜索法作用類似,但是只在超參數空間中進行指定次數的不同采樣。采樣次數通過n_iter參數指定,通過調整其大小可以在效率和性能方面取得平衡。其采樣方法調用ParameterSampler函數,采樣空間必須用字典進行指定。
網格搜索法只能在有限的超參數空間進行暴力搜索, 但隨機搜索法可以在無限的超參數空間進行隨機搜索。
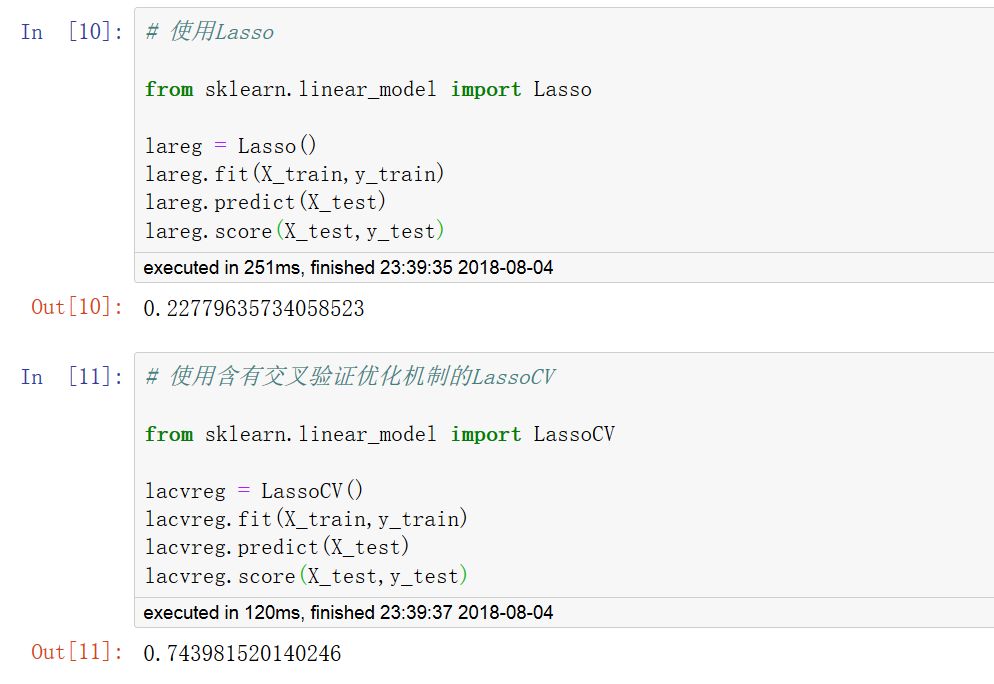
一些特定的模型,sklearn構建了一些內部含有交叉驗證優化機制的估計器。
它們主要是在linear_model模塊。
例如:
linear_model.ElasticNetCV
linear_model.LogisticRegressionCV
linear_model.RidgeCV
等等

四, 信息準則優化
模型選擇主要由兩個思路。
解釋性框架:好的模型應該是最能解釋現有數據的模型。可以用似然函數來度量模型對數據集描述能力。
預測性框架:好的模型應該是最能預測結果的模型。通常模型參數越多越復雜,越容易出現過擬合。
所以,模型選擇問題在模型復雜度與模型對數據集描述能力(即似然函數)之間尋求最佳平衡。
AIC(赤池信息準則)和BIC(貝葉斯信息準則)對模型的選擇提供了一種判據。
AIC信息準則選擇AIC最大的模型。
BIC信息準則選擇BIC最大的模型。當樣本數量較大時,BIC對參數個數的懲罰大于AIC。
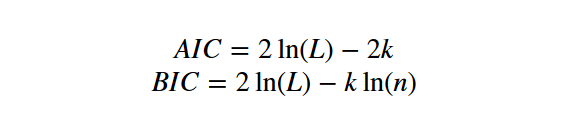
其中L為似然函數,k為模型參數個數,n為樣本數量。
linear_model.LassoLarsIC 采用了信息準則進行優化。
到此,相信大家對“python模型優化實例分析”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





