溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“數據庫中怎么實現分布式延時消息”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
在實現分布式消息隊列的延時消息之前,我們想想我們平時是如何在自己的應用程序上實現一些延時功能的?在Java中可以通過下面的方式來完成我們延時功能:
ScheduledThreadPoolExecutor:ScheduledThreadPoolExecutor繼承了ThreadPoolExecutor,我們提交任務的時候,會將任務首先提交到DelayedWorkQueue一個優先級隊列中,按照過期時間進行排序,這個優先級隊列也就是我們堆結構,每次提交任務排序的復雜度是O(logN)。然后取任務的時候就會從堆頂取出我們的任務,也就是我們延遲時間最小的任務。ScheduledThreadPoolExecutor有個好處是執行延時任務可以支持多線程并行執行,因為他繼承的是ThreadPoolExecutor。
Timer:Timer也是利用優先級隊列結構做的,但是其沒有繼承線程池,相對來說比較獨立,不支持多線程,只能使用單獨的一個線程。
我們實現本地延時比較簡單,直接使用Java中現成的即可,那我們分布式消息隊列的實現有哪些難點呢?
有很多同學首先會想到我們實現分布式消息隊列的延時任務,可不可以直接使用本地的那一套,用ScheduledThreadPoolExecutor,Timer,當然這是可以的,前提是你的消息量很小,但是我們分布式消息隊列往往都是企業級別的中間件,數據量都是非常的大,那么我們純內存的方案肯定是行不通的。所以我們就有了下面這幾個方案來解決我們這個問題。
數據庫一般來說是我們很容易想到的一個辦法,我們通常可以建立下面這樣一個表:
CREATE TABLE `delay_message` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`excute_time` bigint(16) DEFAULT NULL COMMENT '執行時間,ms級別',
`body` varchar(4096) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '消息體',
PRIMARY KEY (`id`),
KEY `time_index` (`excute_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
這個表中我們使用excute_time代表我們真實的執行時間,并且對其建立索引,然后在我們的消息服務中,啟動一個定時任務,定時從數據庫中掃描已經可以執行的消息,然后開始執行,具體流程如下面所示:
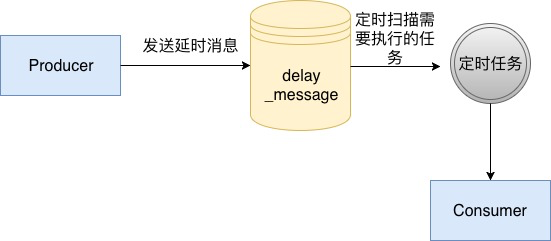
使用數據庫的方法是一個比較原始的方法,在沒有延時消息這個概念之前,要做一個訂單多少分鐘過期的這種功能,通常使用這個方法去完成。而這個方法通常也比較局限于我們單個業務,如果想擴展為我們企業級的一個中間件的話是不行的,因為mysql由于BTree的特性,會隨著維護二級索引的開銷越來越大,導致寫入會越來越慢,所以這個方案通常不會被考慮。
我們之前介紹RocketMQ在開源版本中只實現了18個Level的延時消息,但是有很多公司基于RocketMQ做了自己的一套支持任意時間的延時消息,在美團內部封裝了RocketMQ使用LevelDB做了對延時消息的封裝,在滴滴開源的DDMQ中,使用了RocksDB對RocketMQ的延時消息部分進行了封裝。
其原理基本和Mysql類似,如下圖所示:
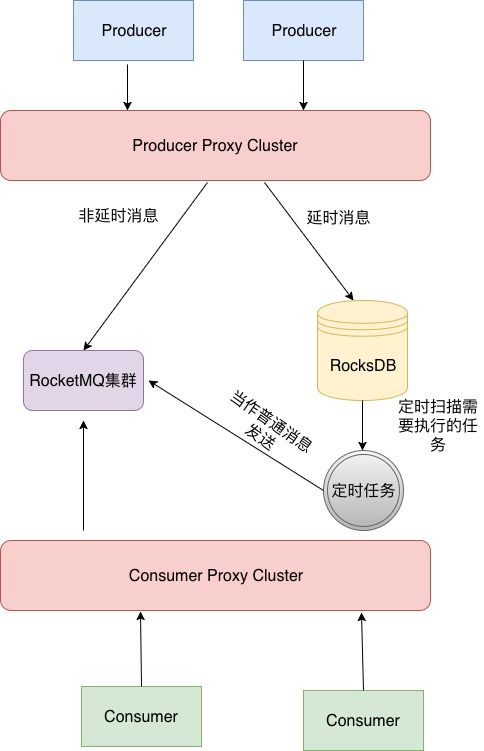
Step1: DDMQ發送消息的時候會有一個代理層,用于將消息做分發,因為其內部有多種消息隊列,kafka,rocketMQ等等,如果是延時消息會將消息發送到RockesDB的存儲。
Step2: 通過定時任務輪訓掃描將數據轉發投遞至RocketMQ集群。
Step3: 消費者進行消費。
為什么同樣是數據庫RocksDB會比Mysql更加合適呢?因為RocksDB的特性是LSM樹,其使用場景適用于大量寫入,和消息隊列的場景更加契合,所以這個也是滴滴和美團選擇其作為延時消息封裝的存儲介質。
再說時間輪之前,讓我們再次回到我們的實現本地延時的時候使用的ScheduledThreadPoolExecutor還有Timer,他們都是使用的優先級隊列完成的,優先級隊列本質上也就是堆結構,堆結構的插入的時間復雜度是O(LogN),如果未來我們的內存可以做到無限,我們使用使用優先級隊列去做延時消息的存儲,但是隨著消息的增多,我們的插入消息的效率也會越來越低,那么怎么才能讓我們的插入消息的效率不隨著消息的增多而變低呢?答案就是時間輪。
什么是時間輪呢?其實我們可以簡單的將其看做是一個多維數組。在很多框架中都使用了時間輪來做一些定時的任務,用來替代我們的Timer,比如我之前講過的有關本地緩存Caffeine一篇文章,在Caffeine中是一個二層時間輪,也就是二維數組,其一維的數據表示較大的時間維度比如,秒,分,時,天等,其二維的數據表示該時間維度較小的時間維度,比如秒內的某個區間段。當定位到一個TimeWhile[i][j]之后,其數據結構其實是一個鏈表,記錄著我們的Node。在Caffeine利用時間輪記錄我們在某個時間過期的數據,然后去處理。
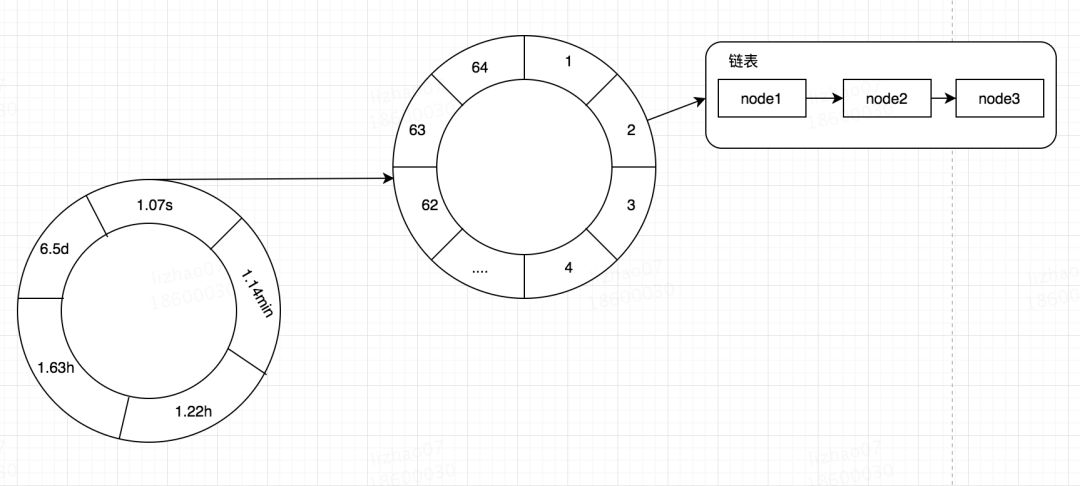
由于時間輪是一個數組的結構,那么其插入復雜度是O(1)。我們解決了效率之后,但是我們的內存依舊不是無限的,我們時間輪如何使用呢?答案當然就是磁盤,在去哪兒開源的QMQ中已經實現了時間輪+磁盤存儲,這里為了方便描述我將其轉化為RocketMQ中的結構來進行講解,實現圖如下:
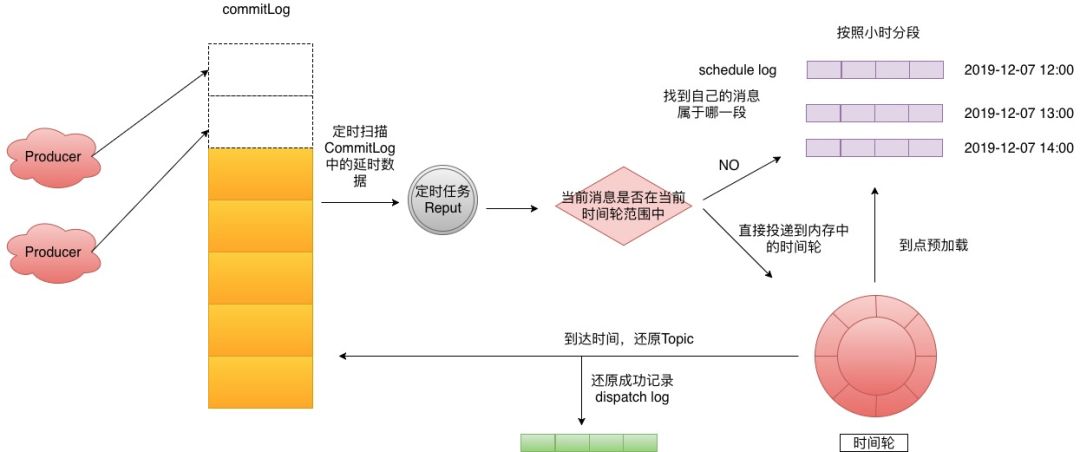
Step 1: 生產者投遞延時消息到CommitLog,這個時候使用了偷換Topic的那招,來達到后面的效果。
Step 2: 后臺有一個Reput的任務定時拉取,延時Topic相關的Message。
Step 3: 判斷這個Message是否在當前時間輪范圍中,如果不在則來到Step4,如果在的話就直接將消息投遞進入時間輪。
Step 4: 找到當前消息所屬的scheduleLog,然后寫入進去,去哪兒默認劃分是一個小時為一段,這里可以根據業務自行調整。
Step 5:時間輪會定時預加載下個時間段的scheduleLog到內存。
Step 6: 到點的消息會還原topic再次投遞到CommitLog,如果投遞成功這里會記錄dispatchLog。記錄的原因是因為時間輪是內存的,你不知道已經執行到哪個位置了,如果執行到最后最后1s鐘的時候掛了,這段時間輪之前的所有數據又得重新加載,這里是用來過濾已經投遞過的消息。
時間輪+磁盤存儲我個人覺得比上面的RocksDB要更加正統一點,不依賴其他的中間件就可以完成,可用性自然也就更高,當然阿里云的RocketMQ具體怎么實現的這個兩種方案都有可能。
在社區中也有很多公司使用的Redis做的延時消息,在Redis中有一個數據結構是Zest,也就是有序集合,他可以實現類似我們的優先級隊列的功能,同樣的他也是堆結構,所以插入算法復雜度依然是O(logN),但是由于Redis足夠快,所以這一塊可以忽略。(這塊沒有做對比的基準測試,只是猜測)。有同學會問,redis不是純內存的k,v嗎,同樣的應該也會受到內存限制啊,為什么還會選擇他呢?
其實在這個場景中,Redis是很容易水平擴展的當一個Redis內存不夠,這里可以使用兩個甚至更多,來滿足我們的需要,redis延時消息的原理圖(原圖出自:https://www.cnblogs.com/lylife/p/7881950.html)如下:
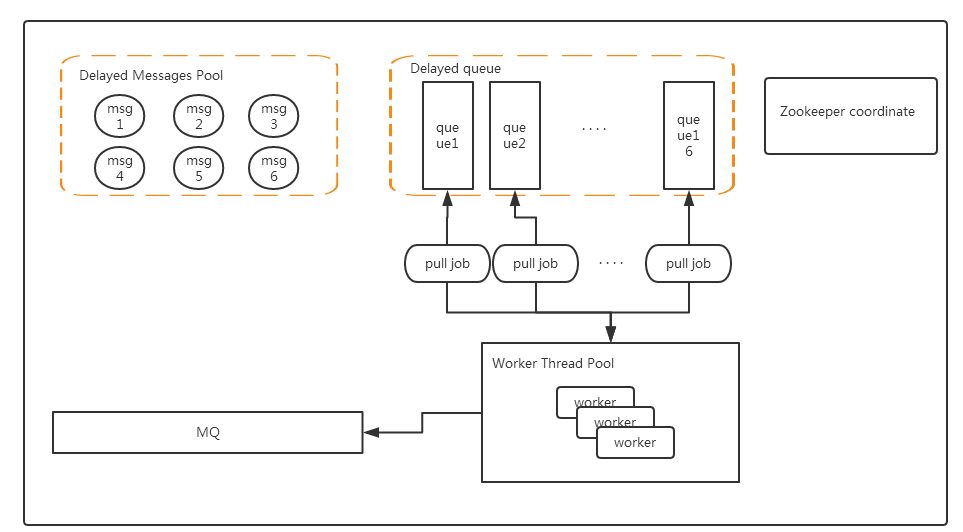
Delayed Messages Pool: Redis Hash結構,key為消息ID,value為具體的message,當然這里也可以用磁盤或者數據庫代替。這里主要存儲我們所有消息的內容。
Delayed Queue: ZSET數據結構,value為消息ID,score為執行時間,這里Delayed Queue可以水平擴展從而增加我們可以支持的數據量。
Worker Thread Pool: 其中有多個Worker,可以部署在多個機器上形成一個集群,集群中的所有Worker通過ZK進行協調,分配Delayed Queue。
我們怎么才能知道Delayed Queue中的消息到期了呢?這里有兩種方法:
每個Worker定時掃描,ZSET的最小執行時間,如果到了就取出,這個方法在消息少的時候特別浪費資源,在消息量多的時候,由于輪訓不及時導致延時的時間不準確。
因為第一個方法問題比較多,所以這里借鑒了Timer中的一些思想,通過wait-notify可以達到一個比較好的延時效果,并且資源也不會浪費,第一次的時候還是獲取ZSET中最小的時間,然后wait(執行時間-當前時間),這樣就不需要浪費資源到達時間時會自動響應,如果當前ZSET有新的消息進入,并且比我們等待的消息還要小,那么直接notify喚醒,重新獲取這個更小的消息,然后又wait,如此循環。
“數據庫中怎么實現分布式延時消息”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





