溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Hadoop 與 MPPDB 的區別是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Hadoop 與 MPPDB 的區別是什么”吧!
1、 什么是MPP?
MPP (Massively Parallel Processing),即大規模并行處理,在數據庫非共享集群中,每個節點都有獨立的磁盤存儲系統和內存系統,業務數據根據數據庫模型和應用特點劃分到各個節點上,每臺數據節點通過專用網絡或者商業通用網絡互相連接,彼此協同計算,作為整體提供數據庫服務。非共享數據庫集群有完全的可伸縮性、高可用、高性能、優秀的性價比、資源共享等優勢。
簡單來說,MPP是將任務并行的分散到多個服務器和節點上,在每個節點上計算完成后,將各自部分的結果匯總在一起得到最終的結果(與Hadoop相似)。
2、MPP(大規模并行處理)架構
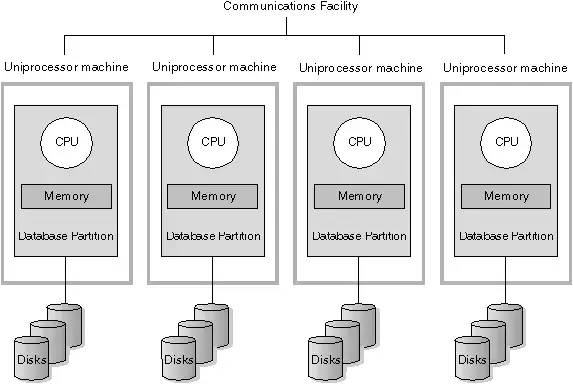
(MPP架構)
3、 MPP架構特征
● 任務并行執行;
● 數據分布式存儲(本地化);
● 分布式計算;
● 私有資源;
● 橫向擴展;
● Shared Nothing架構。
4、 MPP服務器架構
它由多個SMP服務器通過一定的節點互聯網絡進行連接,協同工作,完成相同的任務,從用戶的角度來看是一個服務器系統。其基本特征是由多個SMP服務器(每個SMP服務器稱節點)通過節點互聯網絡連接而成,每個節點只訪問自己的本地資源(內存、存儲等),是一種完全無共享(Share Nothing)結構,因而擴展能力最好,理論上其擴展無限制。
5、MPPDB
MPPDB是一款 Shared Nothing 架構的分布式并行結構化數據庫集群,具備高性能、高可用、高擴展特性,可以為超大規模數據管理提供高性價比的通用計算平臺,并廣泛地用于支撐各類數據倉庫系統、BI 系統和決策支持系統
6、MPPDB架構
MPP 采用完全并行的MPP + Shared Nothing 的分布式扁平架構,這種架構中的每一個節點(node)都是獨立的、自給的、節點之間對等,而且整個系統中不存在單點瓶頸,具有非常強的擴展性。
7、 MPPDB特征
MPP 具備以下技術特征:
1) 低硬件成本:完全使用 x86 架構的 PC Server,不需要昂貴的 Unix 服務器和磁盤陣列;
2) 集群架構與部署:完全并行的 MPP + Shared Nothing 的分布式架構,采用 Non-Master 部署,節點對等的扁平結構;
3) 海量數據分布壓縮存儲:可處理 PB 級別以上的結構化數據,采用 hash分布、random 存儲策略進行數據存儲;同時采用先進的壓縮算法,減少存儲數據所需的空間,可以將所用空間減少 1~20 倍,并相應地提高 I/O 性能;
4) 數據加載高效性:基于策略的數據加載模式,集群整體加載速度可達2TB/h;
5) 高擴展、高可靠:支持集群節點的擴容和縮容,支持全量、增量的備份/恢復;
6) 高可用、易維護:數據通過副本提供冗余保護,自動故障探測和管理,自動同步元數據和業務數據。提供圖形化工具,以簡化管理員對數據庫的管理工作;
7) 高并發:讀寫不互斥,支持數據的邊加載邊查詢,單個節點并發能力大于 300 用戶;
8) 行列混合存儲:提供行列混合存儲方案,從而提高了列存數據庫特殊查詢場景的查詢響應耗時;
9) 標準化:支持SQL92 標準,支持 C API、ODBC、JDBC、ADO.NET 等接口規范。
8、 常見MPPDB
● GREENPLUM(EMC)
● Asterdata(Teradata)
● Nettezza(IBM)
● Vertica(HP)
● GBase 8a MPP cluster(南大通用)
9、 MPPDB、Hadoop與傳統數據庫技術對比與適用場景
MPPDB與Hadoop都是將運算分布到節點中獨立運算后進行結果合并(分布式計算),但由于依據的理論和采用的技術路線不同而有各自的優缺點和適用范圍。兩種技術以及傳統數據庫技術的對比如下:

綜合而言,Hadoop和MPP兩種技術的特定和適用場景為:
● Hadoop在處理非結構化和半結構化數據上具備優勢,尤其適合海量數據批處理等應用要求。
● MPP適合替代現有關系數據機構下的大數據處理,具有較高的效率。
MPP適合多維度數據自助分析、數據集市等;Hadoop適合海量數據存儲查詢、批量數據ETL、非機構化數據分析(日志分析、文本分析)等。
由上述對比可預見未來大數據存儲與處理趨勢:MPPDB+Hadoop混搭使用,用MPP處理PB級別的、高質量的結構化數據,同時為應用提供豐富的SQL和事物支持能力;用Hadoop實現半結構化、非結構化數據處理。這樣可以同時滿足結構化、半結構化和非結構化數據的高效處理需求。
到此,相信大家對“Hadoop 與 MPPDB 的區別是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





