溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了HUE中如何配置Notebook提交spark,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
為執行Spark Job,Hue提供了執行服務器Livy,加強了Hue notebook對spark的支持。它類似于Oozie hadoop工作流服務器,對外提供了Rest Api,客戶端將spark jar以及配置參數傳遞給livy,livy依據配置文件以及參數執行jar。
hue配置文件*.ini中配置如下:
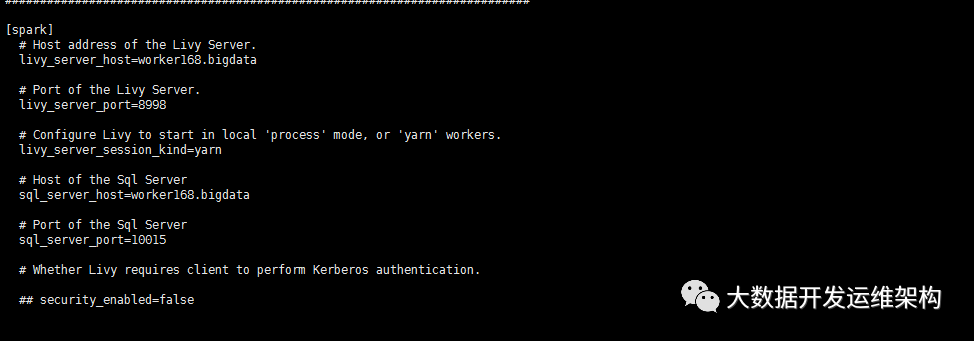
1.測試scalahue登錄點擊“數據分析”-scala ,粘貼 點擊運行
val data = Array(1, 2, 3, 4 ,5)
val distData = sc.parallelize(data)
distData.map(s=>s+1).collect()
點擊 運行,如圖所示:
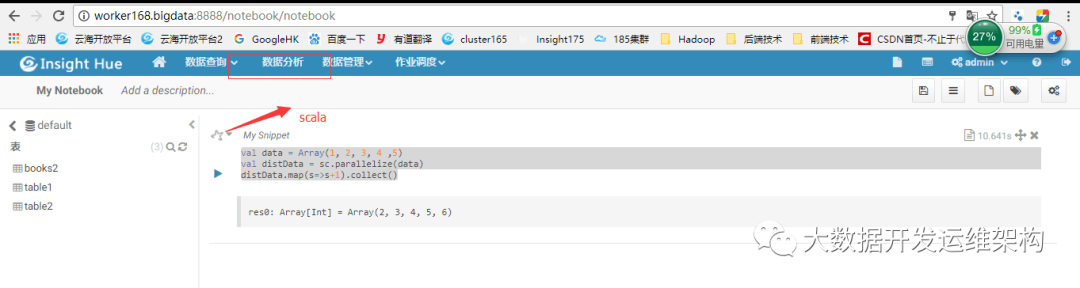
2.測試Spark Submit Jar 點擊“數據分析”-Spark Submit Jar,粘貼 點擊運行
會報錯:"java.lang.NullPointerException"(500)
需修改Hue中文件:
desktop/libs/notebook/src/notebook/connectors/spark_batch.py,文件已放入附件中,刪除35行-80行原來的代碼,替換為附件中的代碼,之后執行spark自帶的example可執行成功。+表示增加行,-表示刪除行
def execute(self, notebook, snippet):
api = get_spark_api(self.user)
- properties = {
- 'file': snippet['properties'].get('app_jar'),
- 'className': snippet['properties'].get('class'),
- 'args': snippet['properties'].get('arguments'),
- 'pyFiles': snippet['properties'].get('py_file'),
- 'files': snippet['properties'].get('files'),
- # driverMemory
- # driverCores
- # executorMemory
- # executorCores
- # archives
- }
+ if snippet['type'] == 'jar':
+ properties = {
+ 'file': snippet['properties'].get('app_jar'),
+ 'className': snippet['properties'].get('class'),
+ 'args': snippet['properties'].get('arguments'),
+ }
+ elif snippet['type'] == 'py':
+ properties = {
+ 'file': snippet['properties'].get('py_file'),
+ 'args': snippet['properties'].get('arguments'),
+ }
+ else:
+ properties = {
+ 'file': snippet['properties'].get('app_jar'),
+ 'className': snippet['properties'].get('class'),
+ 'args': snippet['properties'].get('arguments'),
+ 'pyFiles': snippet['properties'].get('py_file'),
+ 'files': snippet['properties'].get('files'),
+ # driverMemory
+ # driverCores
+ # executorMemory
+ # executorCores
+ # archives
+ }
response = api.submit_batch(properties)
return {
上述內容就是HUE中如何配置Notebook提交spark,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





