溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
通過集算器編寫更為簡單高效的算法加速計算進程,提升查詢性能
采用集算器可控存儲和索引機制,為 BI(CUBE)提供高速的數據存儲
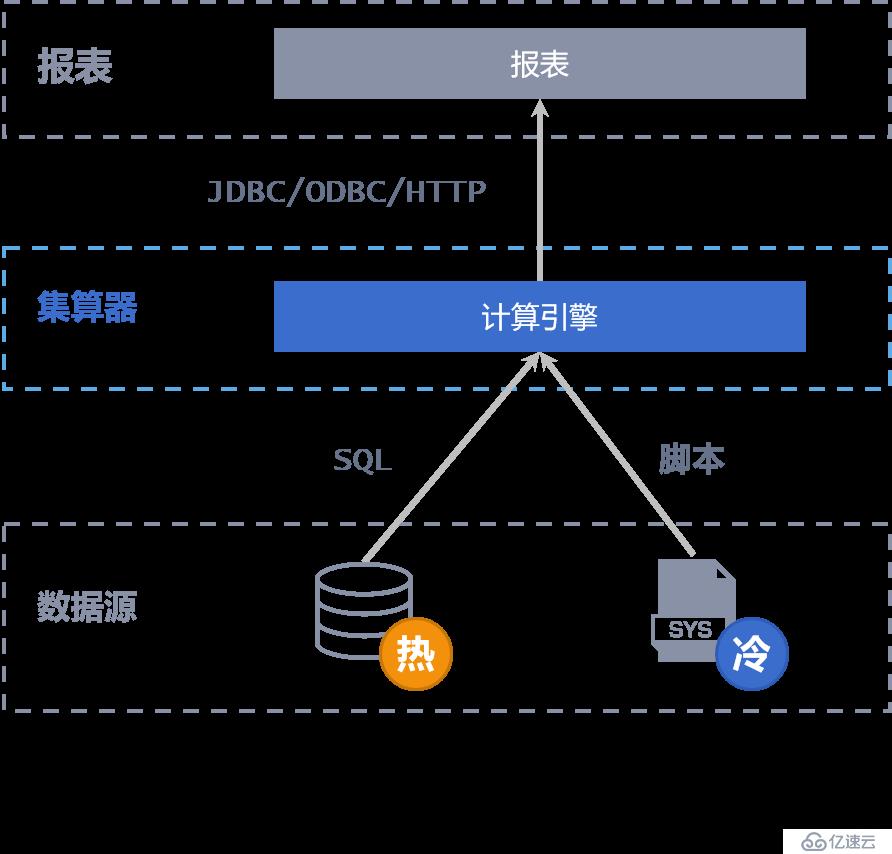
將冷熱數據分離,僅將當期熱數據存放在數據庫中,冷數據存儲在文件系統或數據庫中,通過集算器完成跨源(庫)計算,完成多源數據匯總、復雜計算,實現 T+0 全量數據實時查詢
集算器提供不同數據庫的基本 SQL 翻譯功能,數據分庫(同構異構均可)后,仍然可以使用通用 SQL 進行跨庫查詢
集算器重新定義關聯運算,可以根據計算特征選用不同且高效的關聯算法提升多表關聯性能
一對多的主外鍵表可采用指針式連接提高性能
一對一的同維表和多對一的主子表可采用有序歸并提升性能
集算器采用過程計算,分步實施計算簡化實現代碼,無需嵌套
過程中可以復用中間結果,性能更高
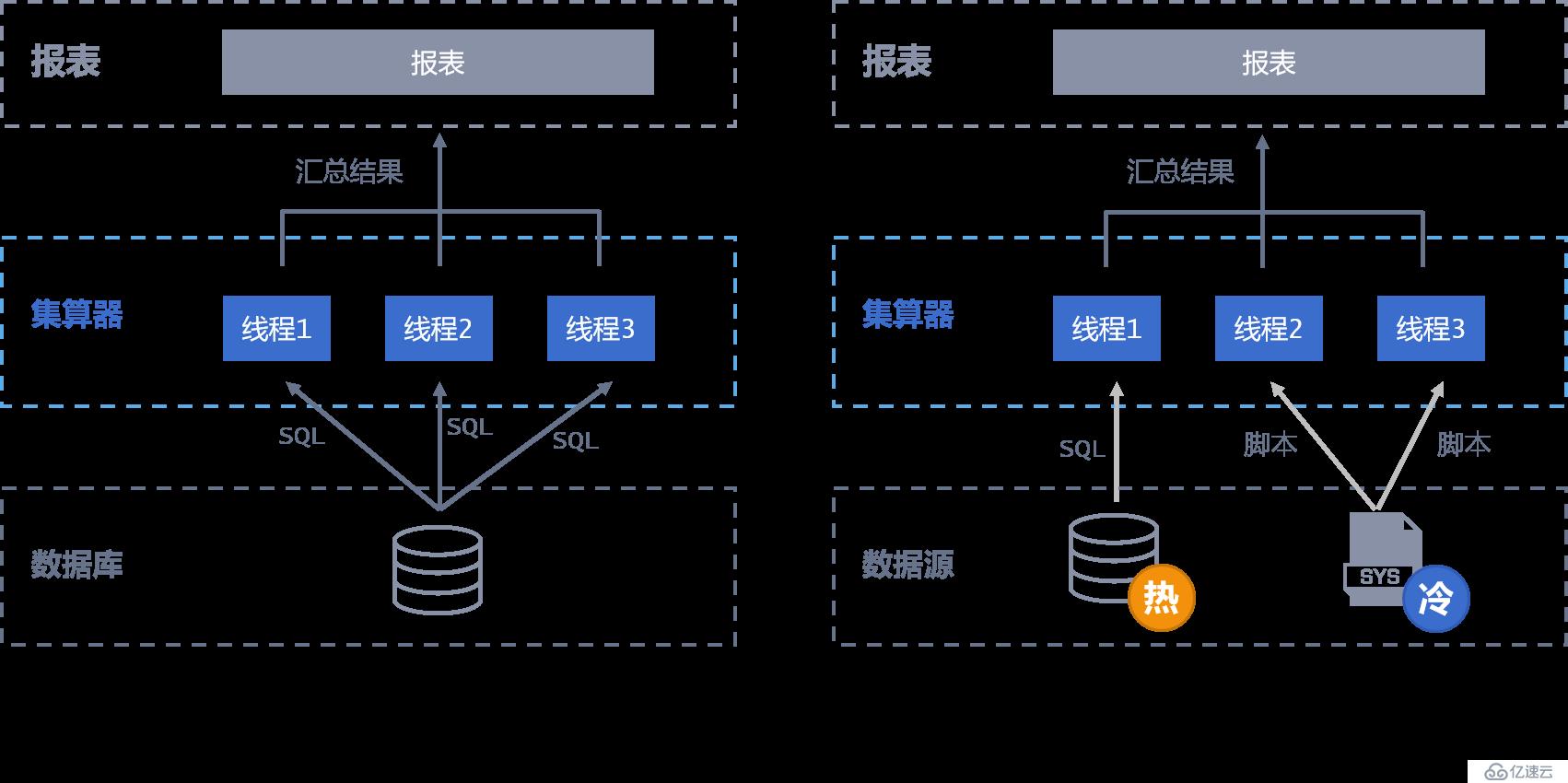
集算器通過(多線程)并行計算與數據庫建立多個連接并行取數提升取數性能
可將量大的冷數據事先存儲在庫外文件系統中,集算器基于文件直接查詢計算,避免通過 JDBC 取數
集算器將計算和呈現做成兩個異步線程,取數線程發出 SQL 將數據緩存到本地交給呈現線程快速展現報表,此外取數線程只涉及一個事務不會出現數據不一致,保證數據準確性
集算器幫助報表開發徹底工具化,不僅報表呈現層工具化,報表數據計算層也工具化,從而降低報表開發難度,報表實現更快更簡單
對人員要求更低,無需專業程序員
報表業務不穩定導致報表沒完沒了不可能消滅,集算器提供了最低成本的應對
集算器作為完備計算引擎,支持過程計算開發快捷
算法實現簡單,適合一般技術人員使用
提供可視化編程環境,即裝即用使用簡單
通過多源支持,基于 Excel/TxT/DB 直接計算無需入庫
集算器通過過程計算,分步編程簡化算法開發難度,算法短小、分步同時降低了維護難度,極大改善上千行 SQL 編寫調試和維護困難的情況
集算器作為庫外通用計算引擎,可以編寫不依賴數據庫的通用算法,數據庫發生變化時無需更改核心算法,易于移植
集算器提供了完備的結構化數據計算能力,解決了 JAVA 集合運算困難的問題,無需再用 JAVA 編寫
集算器還很方便集成到現有應用中,與應用完美結合
集算器可作為報表獨立的計算層,數據準備算法和報表模板一起存儲,共同管理,可與應用分開部署,降低應用的耦合度
解釋執行的集算器腳本可實現熱切換
集算器作為完備計算引擎,提供了豐富的結構化數據運算函數,改善 MySQL 無法使用窗口函數導致的編碼困難
集算器作為完備結構化數據計算引擎,可以充當通用庫外存儲過程,提供不依賴于數據庫的強計算能力和易移植特性
集算器提供直接針對文件使用 SQL 查詢的功能
還可以編寫腳本讀取 NoSQL、文本、Excel 數據,實施計算,實現復雜度與 SQL 相當或更低
集算器提供了對 JSON/XML 這類分層數據的支持,基于這類數據計算不僅編碼簡單,而且性能高實時性好
集算器具備強計算能力,非常擅長復雜計算,可以輔助或替代現有 ETL 工具實現復雜業務邏輯,實現復雜度遠遠低于硬編碼 ETL 計算腳本
集算器支持過程計算,提供可視化編程環境,每步的計算結果所見即所得,還提供設置斷點、單步執行、執行到光標等編輯調試功能,開發效率極高
相對存儲過程需要反復讀寫磁盤使用中間結果,集算器提供豐富的運算,大量減少中間結果落地,性能更高
集算器采用過程計算,提供豐富函數類庫,實現算法短小精悍易于維護
集算器腳本可以脫離數據庫編寫和運行,減少數據庫安全隱患
集算器提供通過 SQL 針對文件的查詢功能
還可以針對 NoSQL、文本和 Excel 直接進行多源混合計算,編碼效率遠高于硬編碼
集算器作為完備計算引擎可以實現真正的 ETL,基于多源混合計算能力先將多源數據進行清洗(E)傳輸(T),將整理好數據加載(L)到目標數據庫,避免匯總到單庫帶來的時間、空間和管理上的過多開銷
集算器采用過程計算,分步編寫代碼,提供豐富的類庫和方法,開發簡單易維護,大大降低編碼難度,提升實施效率
集算器可基于生產庫和分析庫進行混合計算,量小的實時熱數據從生產庫查,將對生產系統的影響降到最低,量大的歷史冷數據從分析庫查,兩部分數據混合計算實現全量數據實時計算
集算器允許將量大且不再變化的歷史數據從數據庫導出到文件系統存儲,借助集算器完備的數據計算能力,直接基于文件系統計算,同時支持與數據庫混合計算,從而降低數據庫擴容壓力,實施成本低
集算器易于應用集成,可將數據倉庫中的部分計算和數據移植到應用層借助集算器計算能力實施數據存儲和計算,分擔數據倉庫壓力
集算器支持將數據庫的中間表移植到 I/O 性能更高的文件系統,降低數據庫冗余,集算器直接基于文件計算,性能更高,還方便實施并行計算,進一步提升效率
中間表在庫外采用文件系統的樹狀結構進行分類管理,優于數據庫的線性結構,管理方便
集算器的強計算能力 + 數據緩存 + 數據網關 + 多源混算可以替代單獨數據集市或前置數據庫,成本低廉
集算器作為輕量級大數據解決非常適合幾個到幾十個節點的集群規模,相對 hadoop 集算器資源利用率更高,節約資源,同樣的計算指標需要硬件更少,同樣的硬件計算效率更高
集算器可將 hadoop 作為數據源,實現 hadoop 難以完成的計算
同時支持實時查詢,避免部署 RDB 帶來的 ETL 時間成本高,數據實時性差,商用 RDB 價格成本高等問題
集算器計算引擎具備復雜計算實現簡單、效率高的特點,適合使用 hadoop 或 spark 卻還經常需要編寫 UDF 的場景,極大提升開發效率
集算器提供靈活的數據分布和計算分布,可以根據數據特征、計算特征和硬件特征實施個性化大數據計算從而獲得最高性能,解決了 hadoop/spark 過于透明導致無法實施高性能計算的難題
集算器提供內存和外存兩種計算方式,由于采用高效計算模型,內存計算時效率更高、內存利用率更低,從而降低成本
當內存容量不夠或無需全內存計算時,集算器采用外存計算從而減輕對內存容量的依賴,硬件成本更低
集算器借助高性能計算和高性能數據存儲特征,優化所以體系,很好解決了 Hbase 等 KV 數據庫批量查詢效率低下的難題
集算器專為結構化數據計算設計,支持過程化計算,提供了豐富的結構化數據集算函數,提供即裝即用的可視化編輯調試環境,非常適合進行桌面數據分析,隨裝隨用,隨用隨走
集算器具備完備的數據計算能力,作為商業軟件,提供了豐富的接口處理 Excel/JSON 等非庫數據,即裝即用,避免了 Python 等開源技術版本混亂、使用困難
集算器提供了多線程并行計算和分布式計算能力,通過簡單的腳本即可實現并行計算,可充分利用多 CPU 核能力實施高性能計算
集算器可作為計算中間件無縫嵌入應用系統,桌面數據分析編寫的腳本可直接移植到生產系統中,無需重寫
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





