溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python中Pandas庫有什么用,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
要很好地理解pandas,關鍵之一是要理解pandas是一系列其他python庫的包裝器。主要的有Numpy、SQL alchemy、Matplot lib和openpyxl。
data frame的核心內部模型是一系列NumPy數組和pandas函數。
pandas利用其他庫來從data frame中獲取數據。例如,SQL alchemy通過read_sql和to_sql函數使用;openpyxl和xlsx writer用于read_excel和to_excel函數。而Matplotlib和Seaborn則用于提供一個簡單的接口,使用諸如df.plot()這樣的命令來繪制data frame中可用的信息。
您經常聽到的抱怨之一是Python很慢,或者難以處理大量數據。通常情況下,這是由于編寫的代碼的效率很低造成的。原生Python代碼確實比編譯后的代碼要慢。不過,像Pandas這樣的庫提供了一個用于編譯代碼的python接口,并且知道如何正確使用這個接口。
向量化操作
與底層庫Numpy一樣,pandas執行向量化操作的效率比執行循環更高。這些效率是由于向量化操作是通過C編譯代碼執行的,而不是通過本機python代碼執行的。另一個因素是向量化操作的能力,它可以對整個數據集進行操作,而不只是對一個子數據集進行操作。
應用接口允許通過使用CPython接口進行循環來獲得一些效率:
df.apply(lambda x: x['col_a'] * x['col_b'], axis=1)
但是,大部分性能收益可以通過使用向量化操作本身獲得,可以直接在pandas中使用,也可以直接調用它的內部Numpy數組。
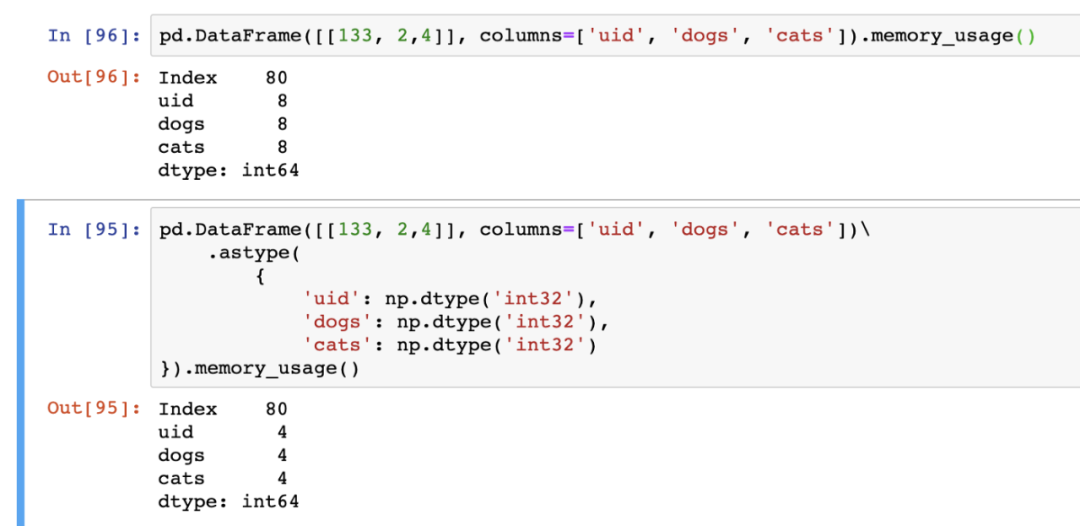
當通過read_csv、read_excel或其他數據幀讀取函數將數據幀加載到內存中時,pandas會進行類型推斷,這可能是低效的。這些api允許您明確地利用dtypes指定每個列的類型。指定dtypes允許在內存中更有效地存儲數據。
df.astype({'testColumn': str, 'testCountCol': float})
Dtypes是來自Numpy的本機對象,它允許您定義用于存儲特定信息的確切類型和位數。
例如,Numpy的類型np.dtype(' int32 ')表示一個32位長的整數。pandas默認為64位整數,我們可以節省一半的空間使用32位:
pandas允許按塊(chunk)加載數據幀中的數據。因此,可以將數據幀作為迭代器處理,并且能夠處理大于可用內存的數據幀。
在讀取數據源時定義塊大小和get_chunk方法的組合允許panda以迭代器的方式處理數據,如上面的示例所示,其中數據幀一次讀取兩行。然后我們可以遍歷這些塊:
i = 0for a in df_iter: # do some processing chunk = df_iter.get_chunk() i += 1 new_chunk = chunk.apply(lambda x: do_something(x), axis=1) new_chunk.to_csv("chunk_output_%i.csv" % i )它的輸出可以被提供到一個CSV文件,pickle,導出到數據庫,等等…
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Python中Pandas庫有什么用”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





