溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“perl怎么分析相關性網絡節點度”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“perl怎么分析相關性網絡節點度”文章能幫助大家解決問題。
#計算節點度diag(rcorr)=0degree=numeric(ncol(rcorr))for (i in 1:ncol(rcorr)) { degree[i]=length(which(rcorr[i,]!=0))}#計算度中心性centdeg=degree/(ncol(rcorr)-1)nodedata=data.frame(degree, centdeg, row.names=rownames(rcorr))nodedata=nodedata[order(nodedata[,2],decreasing=TRUE),]#節點度分布圖library(ggplot2)ggplot(nodedata, aes(x=degree)) + geom_histogram(position='identity', alpha=0.5, fill="cyan", binwidth=1, aes(y=..density..)) + stat_density(geom='line', position='identity', col="cyan4") + xlab("Node Degree") + ylab("Density")此外,可以直接使用函數計算節點度等指標:
degree(g)#計算節點度
closeness(g)#計算接近度中心性
betweenness(g)#中介系數中心性
evcent(g)#計算特征向量中心性
節點度分布圖是不同節點度范圍內的節點數目統計情況,可以反映網絡的異質性,也即節點之間的連接狀況是否均勻,理論上高關聯度節點越多網絡結構越復雜,做圖結果如下所示:
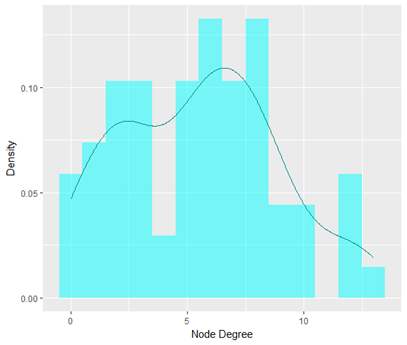
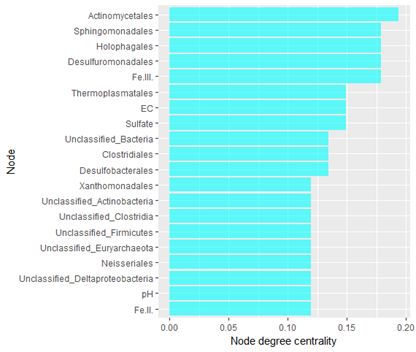
接下來我們可以篩選出度中心性高的節點,來看那些物種或者環境因子在相關性網絡中的影響較大:
#節點度中心性條形圖nodedata=nodedata[1:20, ]ggplot(nodedata, aes(x=factor(rownames(nodedata), levels=rev(rownames(nodedata))), y=centdeg)) + geom_bar(stat="identity", fill="cyan", alpha=0.6) + xlab("Node") + ylab("Node degree centrality") + coord_flip()做圖結果如下所示:
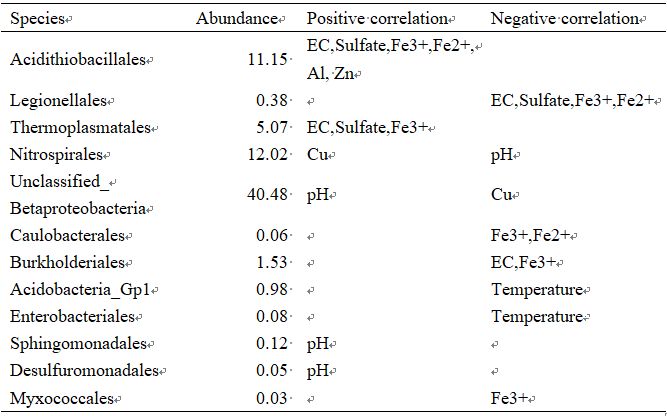
接下來,我們可以篩選受環境因子直接影響(相關系數之和不為0)的物種,并提取其相對豐度信息以便進行比較分析:
#提取篩選環境因子與物種相關性envcor=rcorr[1:m, (m+1):(m+n)]sumcor=numeric(m)for (i in 1:m) { sumcor[i]=sum(abs(envcor[i,]))}ecocor=data.frame(cbind(envcor, sumcor))ecocor=ecocor[order(abs(ecocor$sumcor), decreasing=TRUE),]abund=numeric(m)for (i in 1:m) { abund[i]=100*mean(com[, i])}names(abund)=colnames(com)abundance=abund[rownames(ecocor)]cordata=data.frame(ecocor, abundance)cordata=cordata[cordata$sumcor!=0,]write.csv(cordata, file="cordata.csv", row.names=TRUE, quote=FALSE)
經整理結果如下所示:
關于“perl怎么分析相關性網絡節點度”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





