溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關寫python爬蟲的方法,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
如今很多有編程能力的小伙伴已經不滿足手動搜索內容了,都希望通過編寫爬蟲軟件來快速獲取需要的內容,那么如何使用python制作爬蟲呢?下面小編給大家講解一下思路
寫python爬蟲的方法/步驟
首先我們需要確定要爬取的目標頁面內容,如下圖所示比如要獲取溫度值

然后我們需要打開瀏覽器的F12,查找所要獲取內容的特征,比如他有哪些樣式標簽或者ID屬性

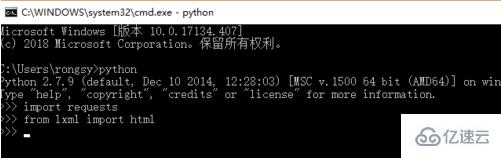
接下來我們打開cmd命令行界面,導入requests庫和html庫,如下圖所示,這個lxml需要大家自行下載安裝
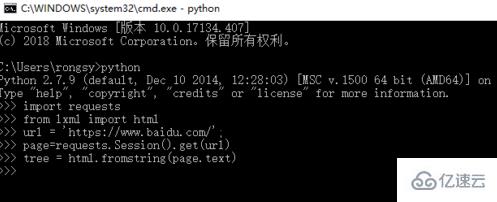
接著就是通過requests庫將頁面內容獲取過來,然后用lxml下的html將其轉化為文本,如下圖所示
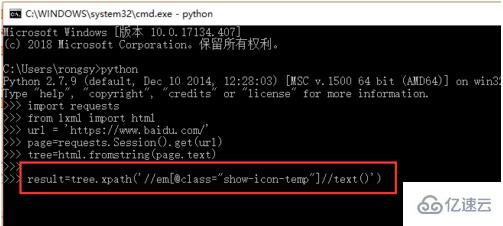
接下來就是通過xpath語法進行特定元素內容的查找,這里一般會用到class或者id的名稱,如下圖所示
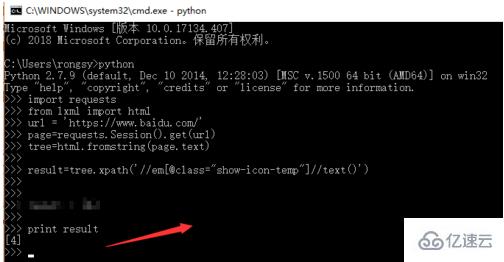
最后運行程序就可以獲取到需要的內容了,如下圖所示
綜上所述,運用python制作爬蟲主要是運用requests獲取內容,然后根據內容進行特定元素查找,這只是最簡單的流程,不過即使在復雜的爬蟲也是這幾步。
關于寫python爬蟲的方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





