溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何用R語言抓取網頁圖片,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
今天要爬取的是一個多圖的知乎網頁,是一個外拍的帖子,里面介紹了巨多各種外拍技巧,很實用的干貨。
library(rvest)
library(downloader)
library(stringr)
library(dplyr)
https://www.zhihu.com/question/19647535
打開網頁之后,在帖子內容里隨便定位一張圖片,然后單擊右鍵——檢查元素(Ctrl+Shift+I),頁面右側彈出的網頁結構會自動定位到該圖片的地址,你會看到該圖片在html結構中的名稱標簽:——(img);地址標簽——(src)。
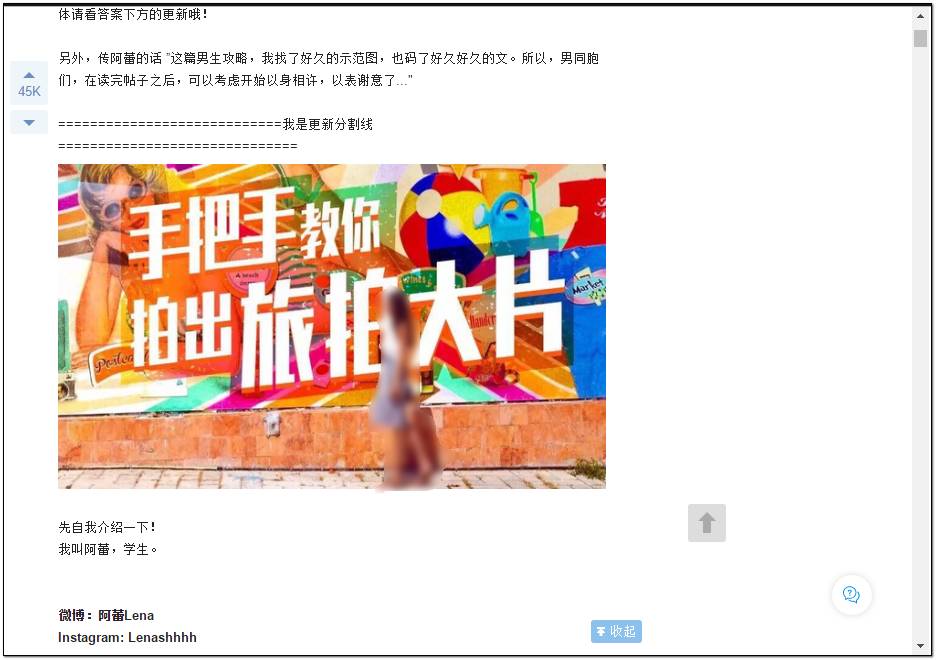
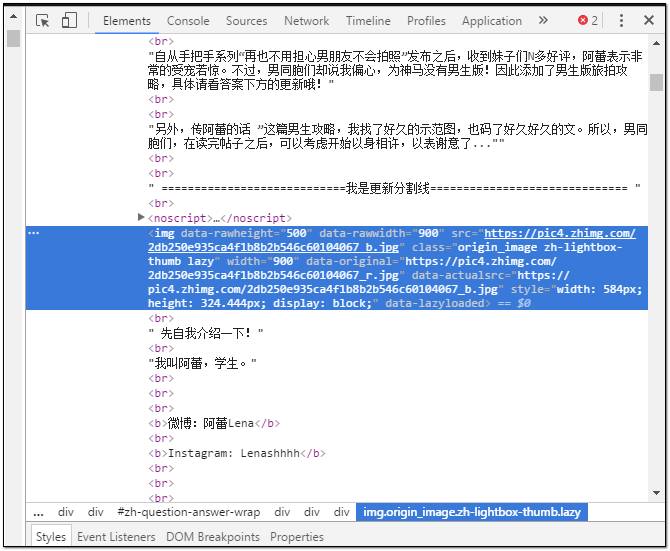
我們想要獲取的就是該圖片的地址信息,你可以嘗試著使用downlond函數下載單張圖片。
url<-"https://pic4.zhimg.com/2db250e935ca4f1b8b2b546c60104067_b.jpg"
download(url,"D:/R/Image/picturebbb.jpg", mode = "wb")
這樣就完成了自動下載過程,但是圖片地址仍然是肉眼觀察獲取的,顯然不夠智能,我們想要的效果是通過一個函數自動的批量獲取圖片地址并下載圖片。
那么下一步的目標就很明確了,如何通過函數批評獲取圖片地址,然后將包含圖片地址的字符串向量傳遞給下載函數。
以上就需要我們大致了解html的構建了,知道所有的圖片存放在html構建的那一部分里面,通過網址定位到圖片存放區間,通過獲取圖片存放的區間,批量獲取圖片地址,然后傳遞給下載函數執行。
太深入的我也不太了解,但是html的常用結構無非是head/body/,head中存放網頁標題和導航欄的信息(我是小白,不要吐槽以上每一句話的準確性哈~),而我們要抓取的目標圖片肯定是存放在body中啦。
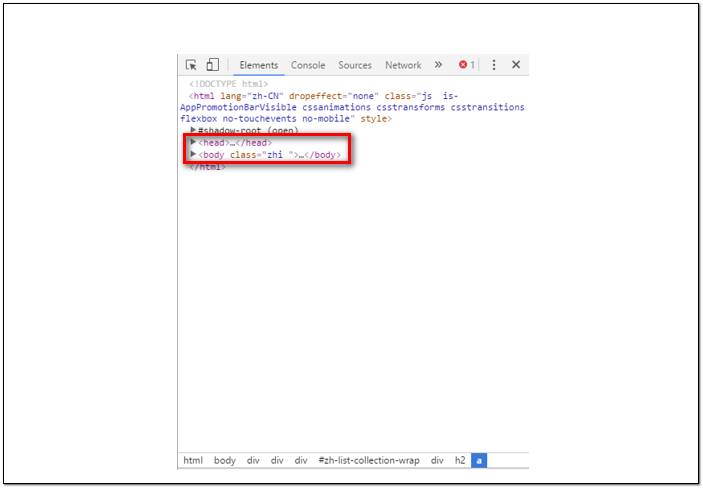
繼續打開body部分,你會被一大摞的<div> </div>結構晃瞎眼,不要擔心,我已經瞎了好幾回了~—~
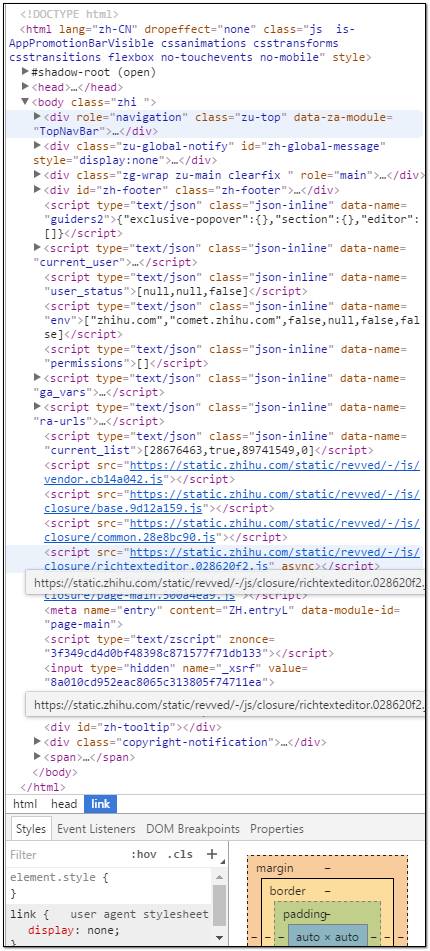
div是html里面的分區結構,每一個分區都是以<div>開頭,以</div>結尾。(html中幾乎所有結構都是這種方式,仔細觀察一下其他形式的結構就會發現)。
當然div分區有N多個,而且div結構本身可以層層嵌套。對于太復雜的網頁,在你發現圖片存放的div分區之前估計會先被div語句晃瞎眼。
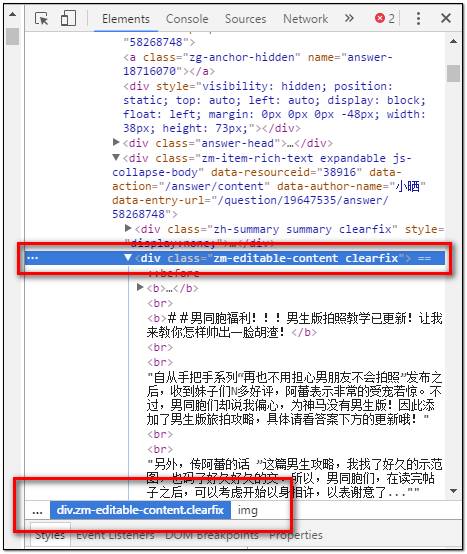
那怎么辦呢,還記得在本文開始部分,說的那個手動定位嗎,依靠瀏覽器的審查元素功能,我們可以先定位要下載的第一張圖片,右鍵——檢查,找到該圖片的div分支結構。
我們需要獲取的信息是該圖片的div分區名稱信息(就是div結構中的class屬性或者ID屬性)
class和ID獲取其中一個就行,如果是class屬性,則地址書寫規則是:div.class,如果是ID則規則是div#ID。
如果class和ID中字符較長,且單詞間存在空格,空格以英文.號替換。
以上圖片的div分支結構定位信息就可以寫作div.zm-editable-content.clearfix
其實這里有一個簡便方法,如果你不確定自己定位的區間是否正確的話,可以查看右下角的html路徑(可以自動根據你的鼠標所在的html位置定位父級路徑)。
接下來使用read_html函數獲取網頁并一步一步的定位圖片地址。
url <- 'https://www.zhihu.com/question/19647535'
link<- read_html(url)%>% html_nodes("div.zm-editable-content.clearfix")%>%html_nodes("img")%>%html_attr("src")
我們需要獲取的是圖片所在div分支結構中的img標簽下的src內容(也就是圖片地址),那么如果不想抓取一大堆不相干的圖片的話,就必須明確目標圖片的存放位置,以上代碼過程從url(該知乎帖子頁面網址)定位到目標圖片所在的div分支結構,然后定位到分支結構中的img(圖片標簽)中的src信息(也就是目標圖片網址)。
運行以上兩句代碼并以head函數預覽link向量的前幾行,查看獲取的圖片地址是否正確。
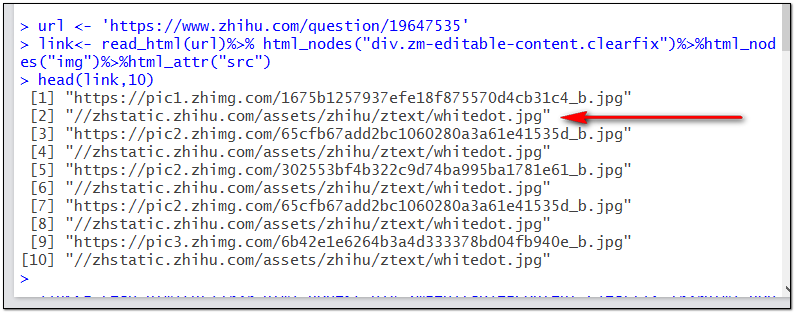
很遺憾,我們獲取的存放圖片地址信息的字符串向量中,每隔一行都有一個無效網址,如果不清除掉這些無效網址或者篩選出那些完整的網址的時候,download函數執行到無效網址會終端,下載過程就會失敗。
這里需要使用stringr包來進行條件篩選。
pat = "https"
link<-grep(pat, link,value=TRUE)
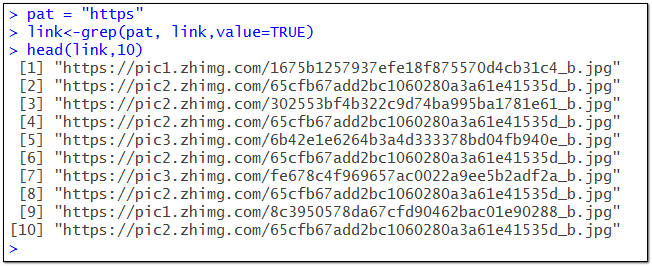
匹配之后,只保留了完整的圖片網址,這就是我們最終要的結果。現在可以使用一個for循環來自動執行圖片批量下載任務。
dir.create("D:R/Case/") #新建文件夾
for(i in 1:length(link))
{
download(link[i],paste("D:/R/Case/picture",i,".jpg",sep = ""), mode = "wb")
} #一個循環批處理所有下載任務
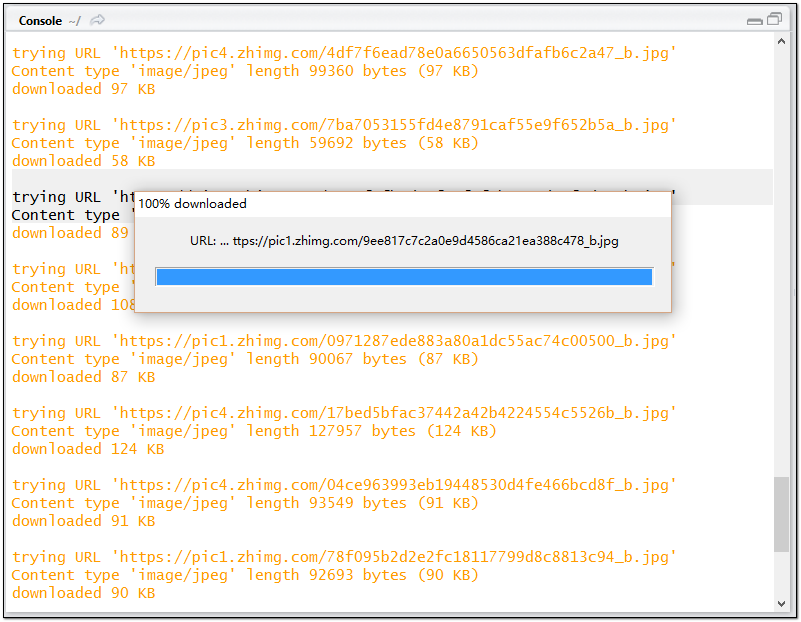
至此,爬蟲的代碼部分完成,剩余的時間……嘿嘿,泡一杯咖啡,看會兒美劇,靜靜地等待軟件完成自動下載過程吧(速度視圖片原始大小和寬帶速度而定)。
結束之后,到D盤的Case文件夾下瀏覽下剛才下載的成果:
394張圖片全部順序標號,乖乖的躺在文件夾里了(當然里面還包含各種表情包圖片,這個,我真的不太會分辨,暫時木辦法)。
下面就今天分享內容總結以下幾點:
用R抓取圖片的核心要點是獲取html結構中存放圖片的div分區中的img標簽內的src內容(也就是圖片地址,有時候可能需要使用read_src內的地址)。
圖片的目標div分區結構的選取至關重要(如果你不指定div分區地址、只使用img標簽下的src定位的話,很有可能抓取了全網頁的圖片網址,各種特殊符號和表情包、菜單欄和logo圖表都會被抓取)
如果不太確定自己定位的div結構是否正確,可以借助鼠標選取+html路徑信息來定位;
有時候有些網頁的圖片不是集中存放在單個div分區結構中,而是每張圖片都是單獨的div結構,這時候如果還是定位的最底層div分區位置的話,那么你可能只能獲取單張圖片地址。這時候適當的定位父級div分支結構名稱(酌情觀察,看那個父級結構范圍可以涵蓋所有目標圖片的子div分支結構)
還有一種情況,就是有些公開的圖片網站圖片存儲結構非常規則,分頁存儲,單頁中單個div結構下的一組圖片名稱是按照數字順序編號的:
比如:
http://################.1.jpg
http://################.2.jpg
http://################.3.jpg
http://################.4.jpg
………………………………………
http://################.n.jpg
如果你碰到這種存儲方式的圖片網頁,那你真的太幸運了,不用再傻乎乎的去從網頁地址的html結構中一步一步的去定位圖片地址了,直接使用for循環遍歷完所有的圖片網址,然后直接傳遞給download函數批量下載就OK了。
for(n in 1:50)
#自己定位到網頁最后一個子頁面,查看下最大的圖片編號是多少。
{
link<- c(paste("http://################/",n,".jpg",sep=""),link)
}
for(i in 1:length(link))
{
download(link[i],paste("D:/R/Case/picture",i,".jpg",sep = ""), mode = "wb")
}
這樣完全避免了從網址中曾曾定位獲取圖片地址的麻煩,直接就可以獲取全網頁所有目標圖片的地址,效率就更高了。
上述內容就是如何用R語言抓取網頁圖片,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





