溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“R語言數據重塑和導出的方法”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
今天跟大家簡單介紹下幾個常用的R數據操縱技巧——導入(xlsx)、導出及長寬轉換!
數據導入(xlsx)
之前寫過一篇關于R導入不同類型數據的方式,但是其中只涉及到.csv、.txt以及直接從剪切板復制。
之所以當時沒有介紹xlsx是因為,excel數據文件屬于富文本類型,結構相對復雜,需要解除特殊包的支持以及java環境,當時電腦上還沒有配置合適的java環境。
后來倒騰一個上午,才算弄完(主要是因為R語言系統版本與Java環境版本需嚴格一致,否則R語言無法自動探測到Java路徑,R語言中的Rjava包便無法加載,而導入xlsx數據需要xlsx包的支持,xlsx包則需要Rjava包的支持)。
所以在導入數據之前,最好先配置好你系統內的java環境,確保其與你的R語言版本一致。
導入xlsx數據所需用到的包:
library("rJava")
library("xlsx")
library("xlsxjars")
以下是導入代碼:
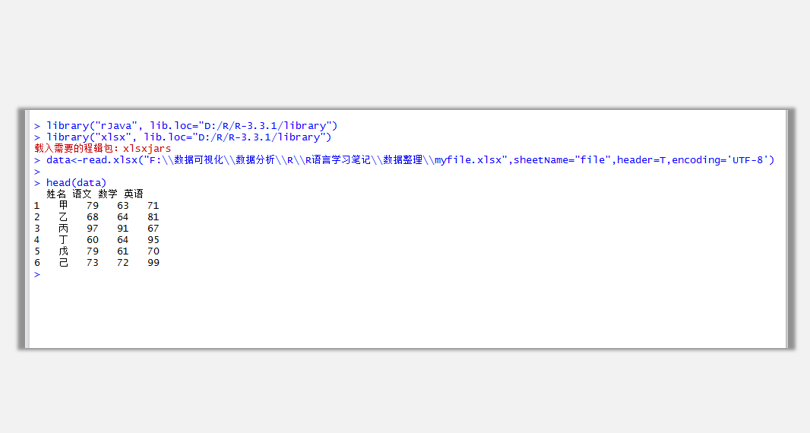
data<-read.xlsx("F:\\數據可視化\\數據分析\\R\\R語言學習筆記\\數據整理\\myfile.xlsx",sheetName="file",header=T,encoding='UTF-8')
以上語法中,括號內第一個參數是路徑及文件名,sheetName="file"是指定要導入的excel工作薄內的工作表對象,如果你對工作表有命名,一定要指定名稱,如果沒有,指定為默認的工作表名稱(Sheet1、2、3),第三個參數指定導入數據文件的編碼方式(UTF-8)。
可以通過head(data)查看數據集的前6條記錄。
數據重塑(寬轉長):
本例就按照導入的成績寬數據作為演示案例:
我們想要將以上導入的數據轉成長數據,也就是一維表(姓名、科目、分數)
加載數據重塑包:
library("reshape2")
mydata <- melt(data, id.vars = "姓名",variable.name = "科目", value.name = "成績")
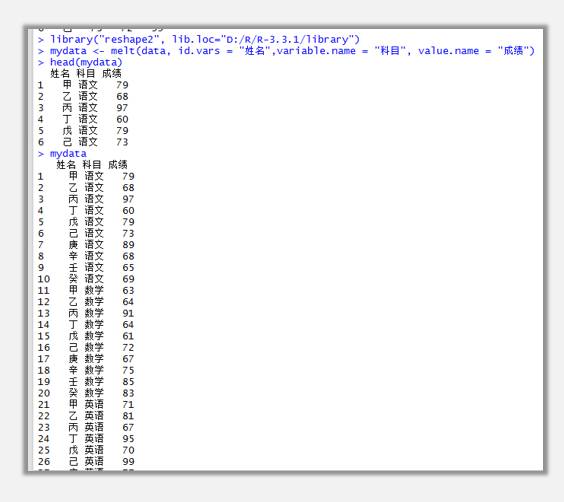
長數據立馬就可以呈現出來。
可是以上情況太過理想,通常我們要面對的寬數據會很復雜:
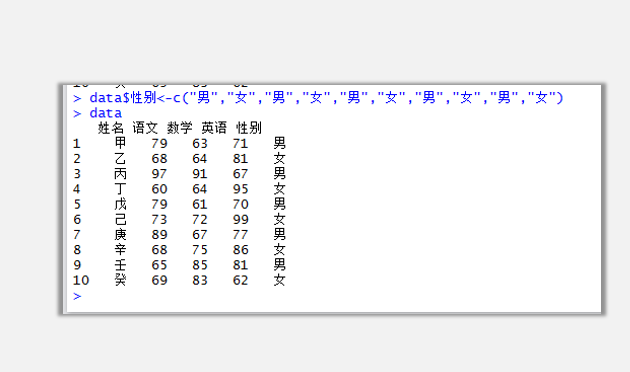
倘若我們面臨的輸入如上所示,想要得到的結果是,姓名、姓名是兩列單獨的字段,不同科目合并成單獨的一個字段。這種結果就稍顯復雜。
不過reshape2包仍然可以輕松應對這種情況:
mydata2 <- melt(data, id.vars = c("姓名","性別"),variable.name = "科目", value.name = "成績")
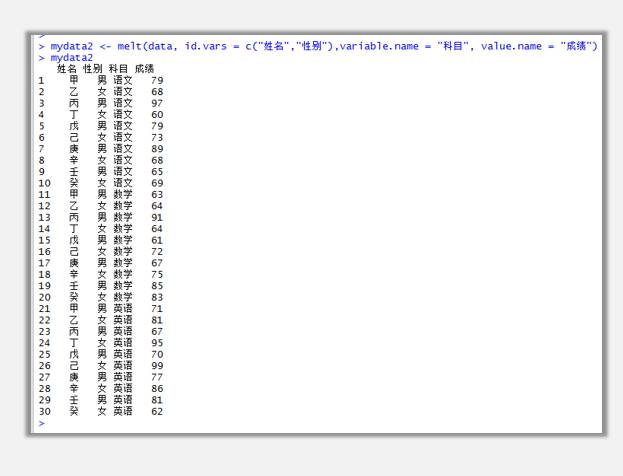
只需在指定主字段時,給id.vars = c("姓名","性別")定義多組主字段就可以了,多組字段要使用逗號區隔。
數據讀出:
好了,以上數據轉換完成,現在我們要將數據導出了,以下暫且介紹兩種類型(xlsx暫不介紹,還是同樣的原因,富文本需要設定的參數太多,需要很多工具支持,目前還沒太搞明白)
導出CSV文件:
write.table (mydata2, file ="F:\\數據可視化\\數據分析\\R\\R語言學習筆記\\數據整理\\newdata.csv", sep =",", row.names =FALSE)
運行以上代碼,你的對應路徑中瞬間就多出一個名為newdata.csv的數據文件:
導出TXT文件:
write.table(mydata2,file="F:\\數據可視化\\數據分析\\R\\R語言學習筆記\\數據整理\\newdata.txt" , sep =" ", row.names =FALSE,col.names =TRUE, quote =FALSE)
sep指定變量間分隔符,默認為空格,row.names指定是否輸出行號,col.names指定是否輸出列名,quote指定是否用引號將變量包括。
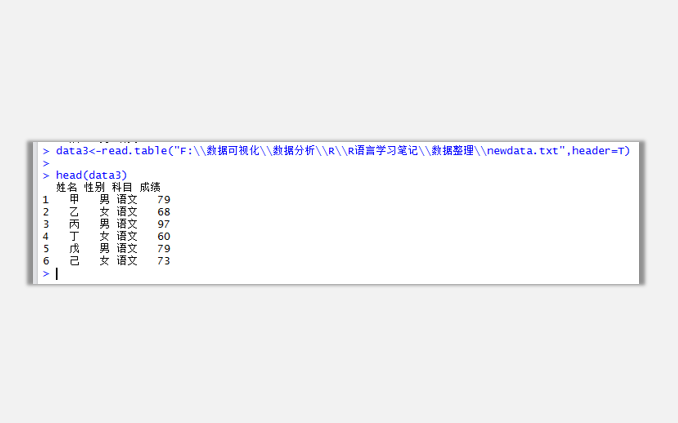
跑完代碼之后,你對應的文件夾目錄下就多對出一個名為newdata的TXT格式數據文件,你可以通過導入并查看數據導入格式是否正確:

data3<-read.table("F:\\數據可視化\\數據分析\\R\\R語言學習筆記\\數據整理\\newdata.txt",header=T)
“R語言數據重塑和導出的方法”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





