溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、何為分布式文件文件系統
分布式文件系統(Distributed File System)是指文件系統管理的物理存儲資源不一定直接連接在本地節點上,而是通過計算機網絡與節點相連,它的設計是基于客戶端/服務器模式。
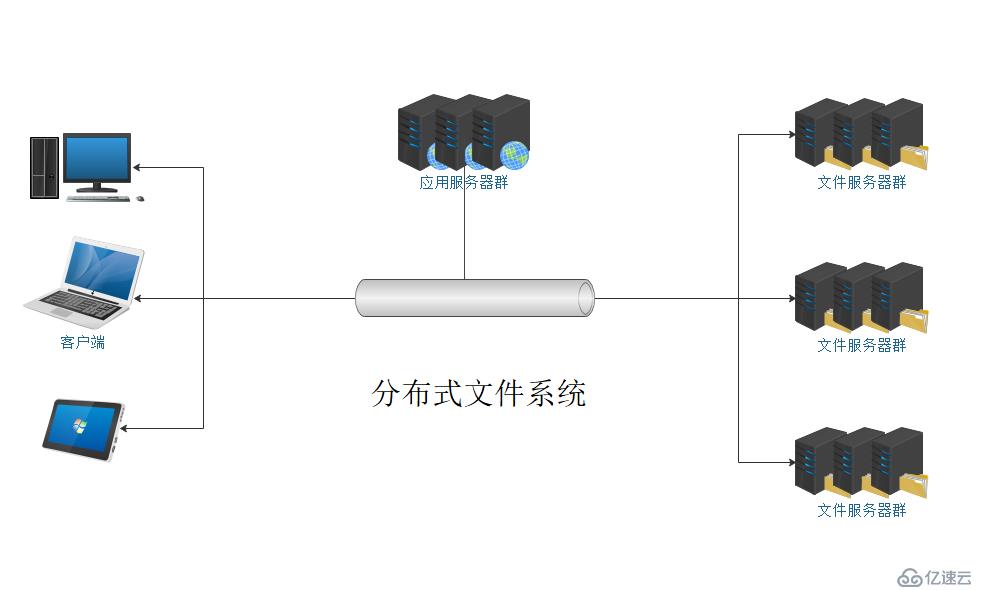
如上圖所示,應用服務器和文件服務器分別存在于網絡當中,而這里的網絡,可以是統一子網,也可以是不同子網。服務器對文件的存取,均在網絡進行,這樣就可以突破常用存儲設備的容量限制。
二、常用分布式文件系統的介紹
1、Lustre
lustre是一個大規模的、安全可靠的,具備高可用性的集群文件系統,它是由SUN公司開發和維護。該項目主要的目的就是開發下一代的集群文件系統,可以支持超過10000個節點,數以PB的數量存儲系統。
2、Hadoop
hadoop不僅僅是一個用于存儲的分布式文件系統,而其設計更是用來在由通用計算設備組成的大型集群上執行分布式應用的框架。目前主要應用于大數據、區塊鏈等領域。
3、FastDFS
FastDFS是一個開源的分布式文件系統,它對文件進行管理,功能包括:文件存儲、文件同步、文件訪問(文件上傳、文件下載)等,解決了大容量存儲和負載均衡的問題。特別適合以文件為載體的在線服務, 如相冊網站,視頻網站等等。
4、Ceph
Ceph是一個具有高擴展、高可用、高性能、可以提供對象存儲、塊存儲、文件存儲的分布式文件系統,它可以提供 PD 級別的存儲空間,理論上說,是無上限的。
三、Ceph 介紹
Ceph是一個具有高擴展、高可用、高性能的分布式存儲系統,根據場景劃分可以將Ceph分為對象存儲、塊設備存儲和文件系統服務。在虛擬化領域里,比較常用到的是Ceph的塊設備存儲,比如在OpenStack項目里,Ceph的塊設備存儲可以對接OpenStack的cinder后端存儲、Glance的鏡像存儲和虛擬機的數據存儲。比較直觀的是Ceph集群可以提供一個raw格式的塊存儲來作為虛擬機實例的硬盤。
Ceph相比其它存儲的優勢點在于它不單單是存儲,同時還充分利用了存儲節點上的計算能力,在存儲每一個數據時,都會通過計算得出該數據存儲的位置,盡量將數據分布均衡。同時由于Ceph本身的良好設計,采用了CRUSH算法、HASH環等方法,使得它不存在傳統的單點故障的問題,且隨著規模的擴大性能并不會受到影響。
四、Ceph 構成
Ceph的核心構成包括:Ceph OSD(對象存出設備)、Ceph Monitor(監視器) 、Ceph MSD(元數據服務器)、Object、PG、RADOS、Libradio、CRUSH、RDB、RGW、CephFS
OSD:全稱 Object Storage Device,真正存儲數據的組件,一般來說每塊參與存儲的磁盤都需要一個 OSD 進程,如果一臺服務器上又 10 塊硬盤,那么該服務器上就會有 10 個 OSD 進程。
MON:MON通過保存一系列集群狀態 map 來監視集群的組件,使用 map 保存集群的狀態,為了防止單點故障,因此 monitor 的服務器需要奇數臺(大于等于 3 臺),如果出現意見分歧,采用投票機制,少數服從多數。
MDS:全稱 Ceph Metadata Server,元數據服務器,只有 Ceph FS 需要它。
Object:Ceph 最底層的存儲單元是 Object 對象,每個 Object 包含元數據和原始數據。
PG:全稱 Placement Grouops,是一個邏輯的概念,一個PG包含多個OSD。引入PG這一層其實是為了更好的分配數據和定位數據。
RADOS:全稱Reliable Autonomic Distributed Object Store,是Ceph集群的精華,可靠自主分布式對象存儲,它是 Ceph 存儲的基礎,保證一切都以對象形式存儲。
Libradio:Librados是Rados提供庫,因為RADOS是協議很難直接訪問,因此上層的RBD、RGW和CephFS都是通過librados訪問的,目前僅提供PHP、Ruby、Java、Python、C和C++支持。
CRUSH:是Ceph使用的數據分布算法,類似一致性哈希,讓數據分配到預期的地方。
RBD:全稱 RADOS block device,它是 RADOS 塊設備,對外提供塊存儲服務。
RGW:全稱 RADOS gateway,RADOS網關,提供對象存儲,接口與 S3 和 Swift 兼容。
CephFS:提供文件系統級別的存儲。
五、Ceph 部署
1、Ceph拓撲結構
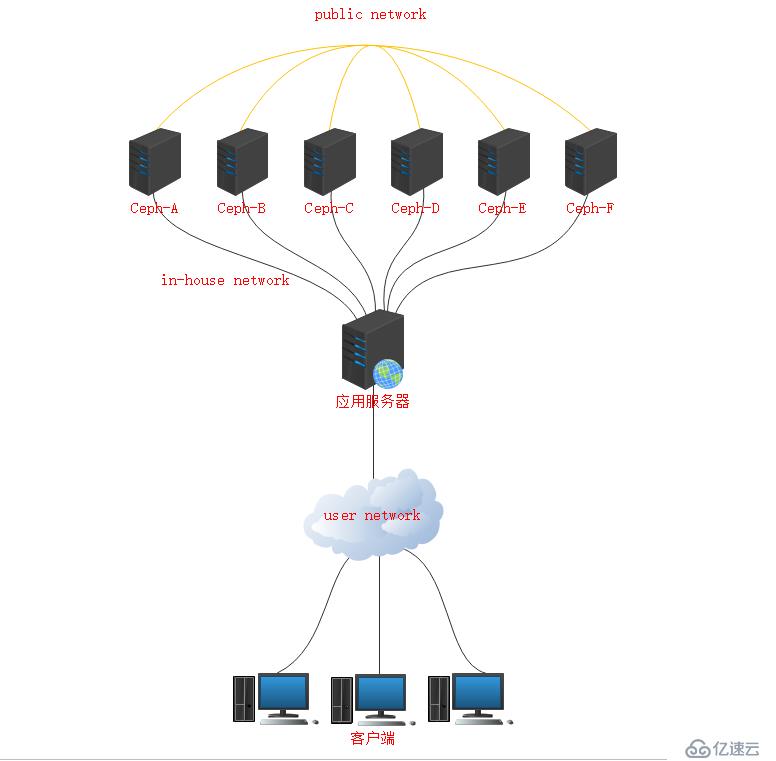
2、服務器規劃

3、服務器環境準備
a、配置主機名、IP地址解析,分別在 6 臺服務器中執行以下命令:
[root@ceph-a ~]# echo -e "192.168.20.144 ceph-a" >> /etc/hosts [root@ceph-a ~]# echo -e "192.168.20.145 ceph-b" >> /etc/hosts [root@ceph-a ~]# echo -e "192.168.20.146 ceph-c" >> /etc/hosts [root@ceph-a ~]# echo -e "192.168.20.147 ceph-d" >> /etc/hosts [root@ceph-a ~]# echo -e "192.168.20.148 ceph-e" >> /etc/hosts [root@ceph-a ~]# echo -e "192.168.20.149 ceph-f" >> /etc/hosts
b、配置免密登陸
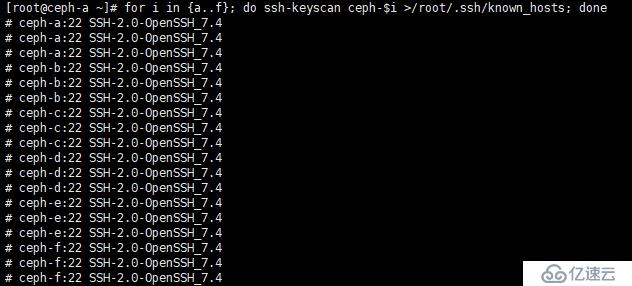
掃描服務器 A 到 F的密鑰,其目的主要是避免在進行 ssh 連接或者在后面執行 ceph 類命令出現 yes/no 的交互,在 Ceph-A 中執行以下命令:
[root@ceph-a ~]# for i in {a..f}; do ssh-keyscan ceph-$i >/root/.ssh/known_hosts; done如下圖:
在 Ceph-A 生成私鑰,在 Ceph-A 中執行以下命令:
[root@ceph-a ~]# ssh-keygen -f /root/.ssh/id_rsa -N ''
如圖:
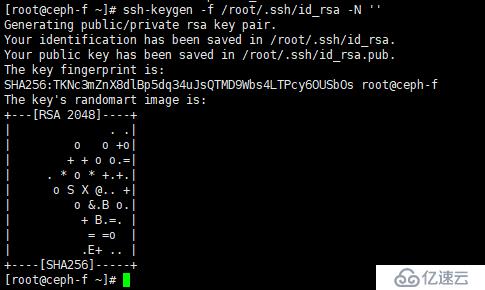
說明:-f 參數指定私鑰文件路徑, -N 參數聲明該過程為非交互式,也就是不用我們手動按回車鍵等
將私鑰文件拷貝到 Ceph-B 到 Ceph-F 服務器中,執行以下命令:
[root@ceph-a ~]# for i in {b..f}; do ssh-copy-id ceph-$i; donec、配置 NTP 網絡時間同步服務
在 6 臺服務器中安裝 chrony 軟件包,在服務器 A 執行以下命令即可:
[root@ceph-a ~]# for i in {a..f}; do ssh ceph-$i yum -y install chrony ; done配置 Ceph-A 為 NTP 服務器:
[root@ceph-a ~]# vim /etc/chrony.conf
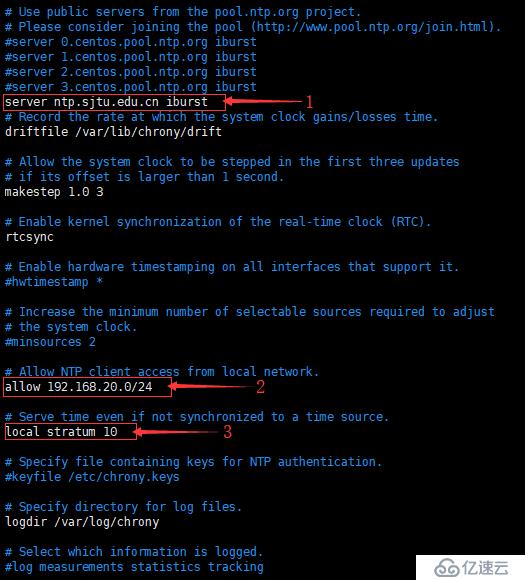
如圖,修改圖中的三個部分
①、注釋掉默認的 NTP 服務器,添加國內的 NTP 服務器,這里添加的是北京郵電大學的 NTP 服務器。
②、允許 192.168.20.0/24 網段進行時間同步。
③、本地時間服務器層級,取消注釋即可。
配置 Ceph-B 到 Ceph-F 服務器通過 Ceph-A 進行時間同步
[root@ceph-b ~]# vim /etc/chrony.conf
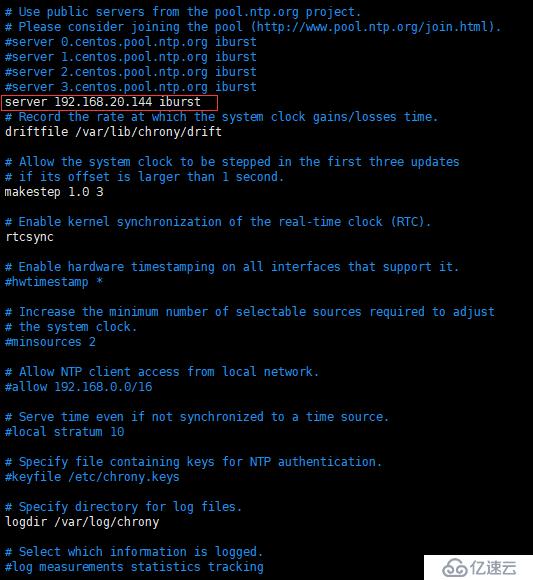
如圖,將圖中紅框內(也就是剛才配置的 Ceph-A)的 NTP 服務器添加進去即可,其他沒用的注釋。
保存并退出,并將改配置文件復制到 Ceph-C 到 Ceph-F 中:
[root@ceph-b ~]# for i in {c..f}; do scp /etc/chrony.conf ceph-$i:/etc/; done重啟 Ceph-A 到 Ceph-F 的 chrony 服務,在 Ceph-A 中執行以下命令:
[root@ceph-a ~]# for i in {a..f}; do ssh ceph-$i systemctl restart chronyd; done同步 Ceph-A 的時間
[root@ceph-a ~]# ntpdate ntp.sjtu.edu.cn

同步 Ceph-B 到 Ceph-F 的時間,在 Ceph-A 中執行即可:
[root@ceph-a ~]# for i in {b..f}; do ssh ceph-$i ntpdate 192.168.20.144; done 
4、配置 yum 源
之前我們有部署本地 yum 倉庫,這里,我們使用之前配置的 yum 倉庫。
移除系統自帶的 repo 文件,編輯 /etc/yum.repos.d/localhost.repo 文件,將下面內容添加到該文件中:
[Centos-Base] name=Centos-Base-Ceph baseurl=http://192.168.20.138 enable=1 gpgcheck=1 priority=2 type=rpm-md gpgkey=http://192.168.20.138/ceph-key/release.asc
清空元數據緩存并重建
[root@ceph-a ~]# yum clean all [root@ceph-a ~]# yum makecache
5、安裝 Ceph 服務,這里將 Ceph-A 做為 admin 管理端
a、在 Ceph-A 中安裝 ceph-deploy
[root@ceph-a ~]# yum -y install ceph-deploy
b、在 Ceph-A 中創建 ceph 的工作目錄并進入
[root@ceph-a ~]# mkdir /etc/ceph && cd /etc/ceph
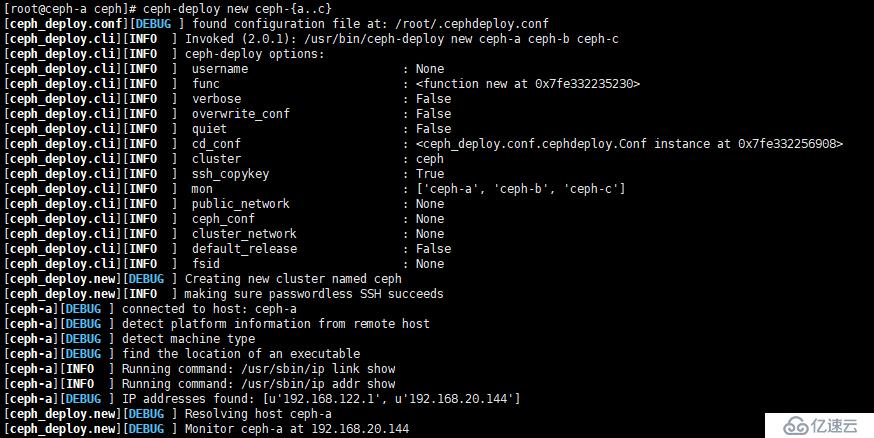
c、Ceph-A 到 Ceph-C 中創建集群節點配置文件,Ceph-D 到 Ceph-F 服務器暫有他用,以下操作,均不涉及在內。
[root@ceph-a ~]# ceph-deploy new ceph-{a..c}如圖:
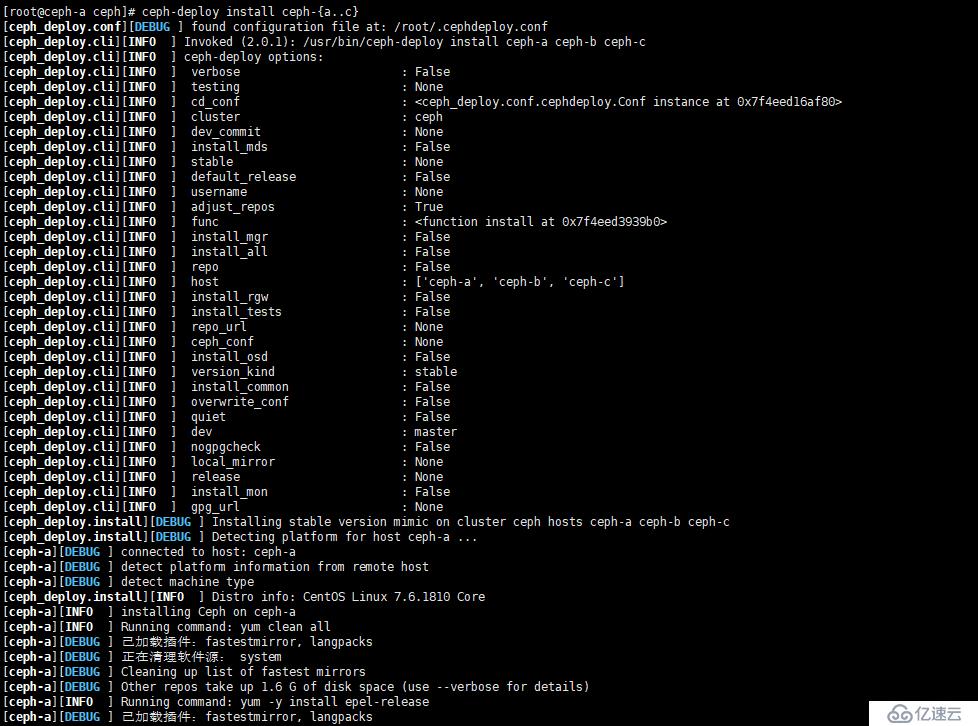
d、在 Ceph-A 到 Ceph-C 三個節點中安裝 ceph 軟件包
[root@ceph-a ceph]# ceph-deploy install ceph-{a..c}如圖:
e、初始化 mon 服務
[root@ceph-a ceph]# ceph-deploy mon create-initial
如圖:
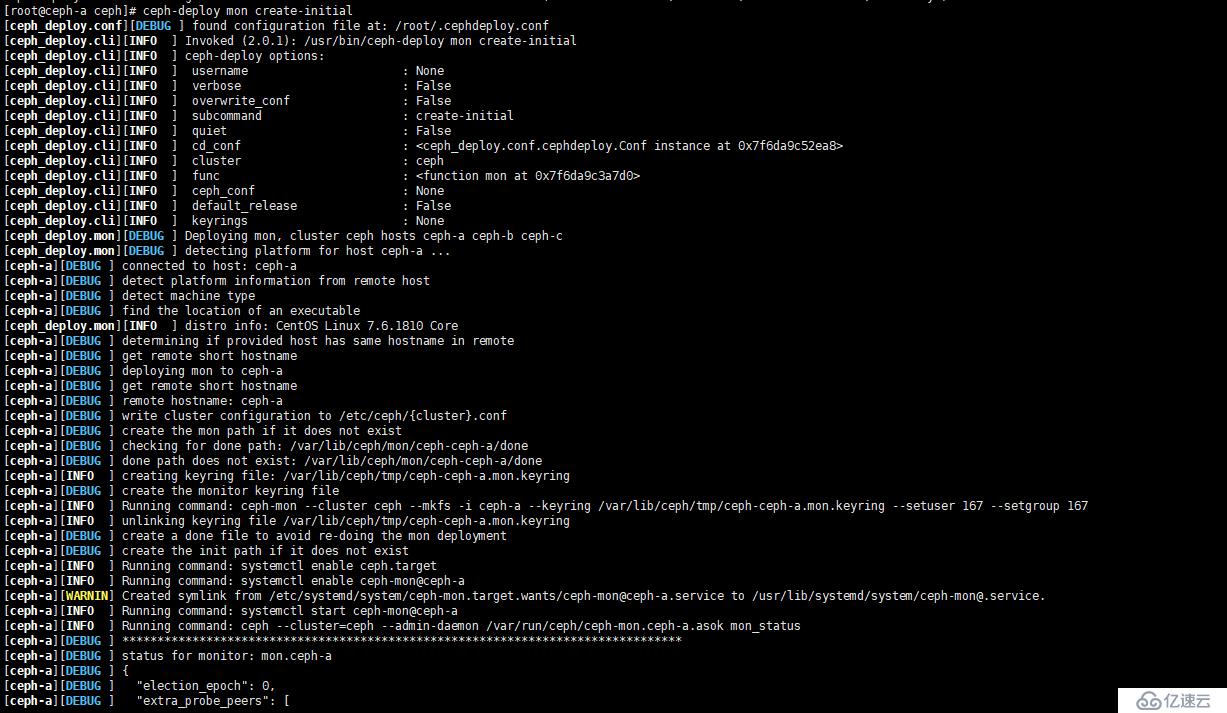
f、創建 OSD 設備
在服務器規劃中,我們一共規劃了 4 塊硬盤,其中 sda 用作系統盤,那么還剩下 sdb、sdc、sdd 三塊硬盤,這里,我們將 sdb 硬盤做為日志盤,而 sdc 和 sdd 做為數據盤。
①、將 Ceph-A 到 Ceph-C 的 sdb 硬盤格式化為gpt格式
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i parted /dev/sdb mklabel gpt; done說明:如果這里這條命令有報錯,則需要把此命令拆分成下面兩條命令,然后分別到 Ceph-A、Ceph-B、Ceph-C中單獨執行。
parted /dev/sdb mklabel gpt
②、給硬盤 sdb 創建分區
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i parted /dev/sdb mkpart primary 1M 50%; done
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i parted /dev/sdb mkpart primary 50% 100%; done分區成功與否,可以使用 lsblk 命令進行查看:
[root@ceph-a ~]# lsblk
如圖:

③、為分區 sdb1 和 sdb2 分配屬主屬組為 ceph
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i chown ceph.ceph /dev/sdb?; done注意:此處有可能會出現下面的錯誤
[ceph-a][ERROR ]admin_socket:exception getting command descriptions:[Errno 2]No such file or directory
解決方案如下:
編輯 ceph.conf ,在最下面加入如下行: public_network = 192.168.20.0/24 保存并退出,再執行以下命令,將配置文件覆蓋推送到三臺服務器節點: [root@ceph-a ceph]# ceph-deploy --overwrite-conf config push ceph-a ceph-b ceph-c
④、此時,我們可以查看一下 ceph 狀態,使用命令 ceph health 或者 ceph -s
[root@ceph-a ceph]# ceph health
正常情況下會輸出 HEALTH_OK ,如果不是,有可能會有以下情況
ceph:health_warn clock skew detected on mon
出現此錯誤,說明我們的服務器時間同步有問題,我們可以先進行時間同步
[root@ceph-a ~]# for i in {b..f}; do ssh ceph-$i ntpdate 192.168.20.144; done如果時間同步后,還是沒有解決,則使用以下解決辦法:
[root@ceph-a ceph]# vim ceph.conf
在global字段下添加:
mon clock drift allowed = 2
mon clock drift warn backoff = 30
2、向需要同步的 mon 節點推送配置文件:
[root@ceph-a ceph]# ceph-deploy --overwrite-conf config push ceph-a ceph-b ceph-c
這里是向Ceph-A、Ceph-B、Ceph-C推送,也可以后跟其它不連續節點
3. 重啟 mon 服務(centos7環境下)
[root@ceph-a ceph]# for i in {a..c}; do ssh ceph-$i systemctl restart ceph-mon.target; done
4.驗證:
[root@ceph-a ceph]# ceph health
顯示 OK ,就說明正常了使用 ceph -s 查看狀態時,也有可能會出現下面情況:
如圖:
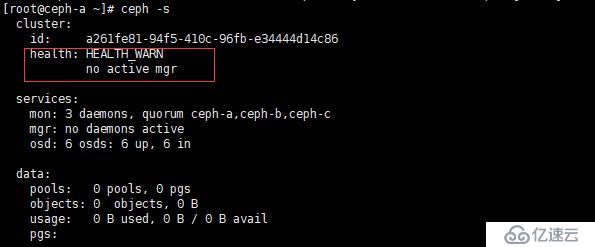
如圖紅框中所示,no active mgr,這種情況,需要我們手動創建管理進程,解決方案如下
[root@ceph-a ceph]# ceph-deploy mgr create ceph-{a..c}再次查看狀態,如下圖
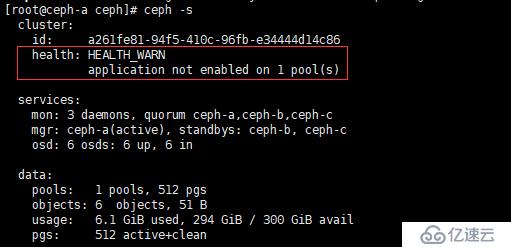
發現變成了application not enabled on 1 pool(s),這種情況,我們要執行
[root@ceph-a ceph]# ceph osd pool application enable cephrbd image
cephrbd:為我們手動創建的 pool
image:為我們手動創建的鏡像
再次查看狀態
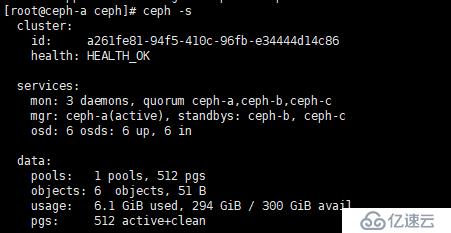
發現已經變成 OK ,表示正常
⑤、初始化 sdc、sdd 硬盤,清空硬盤數據
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy disk zap ceph-$i /dev/sdc; done
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy disk zap ceph-$i /dev/sdd; done如圖:
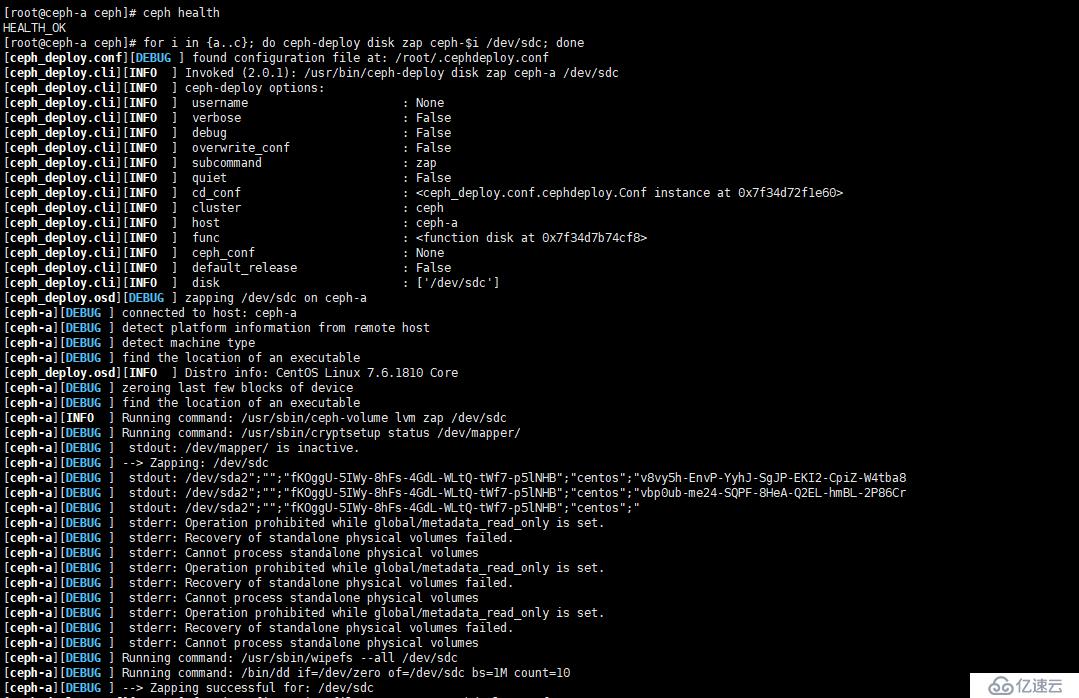
注意:在 13.2.0 之前的版本中,應使用以下命令:
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy disk zap ceph-$i:/dev/sdc ceph-$i:/dev/sdd; done 但是上面的命令在本例 13.2.2 版本不適合,否則,會有下面的報錯,這個坑,花了好長時間,才發現是命令格式錯誤(官方文檔也一樣,不是最新版的,很多地方并不適用于最新版)
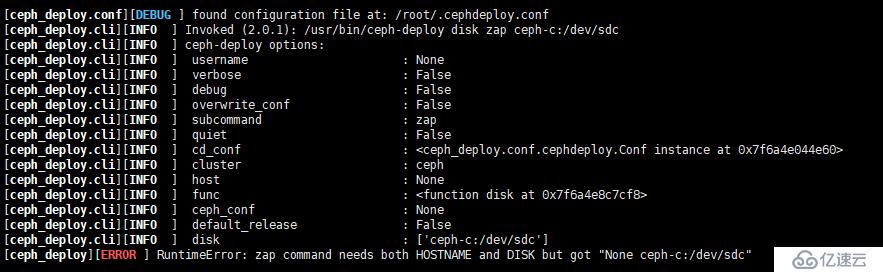
⑥、創建 OSD 存儲空間,這里把 sdb1 做為 sdc 的日志盤,把 sdb2 做為 sdd 的日志盤
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create --data /dev/sdc --journal /dev/sdb1 ceph-$i; done
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create --data /dev/sdd --journal /dev/sdb2 ceph-$i; done如圖:
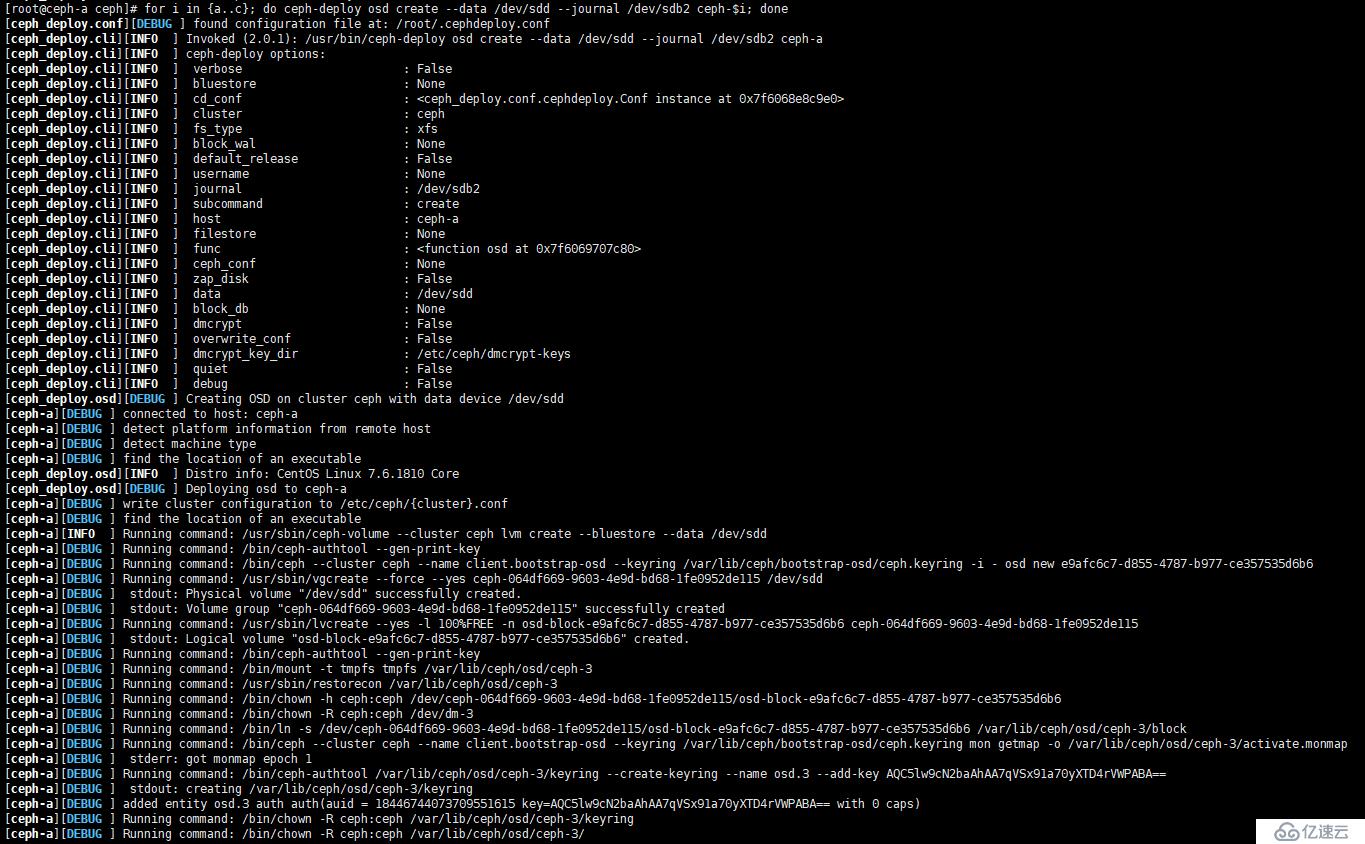
--data:指定數據盤
--journal:指定日志盤
此處也存在命令格式問題,如果是 13.2.0 之前的版本,則使用下面命令:
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create ceph-$i:sdc:/dev/sdb1; done
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create ceph-$i:sdc:/dev/sdb1; done如果在本例中使用上面命令,則會報以下錯誤,如圖
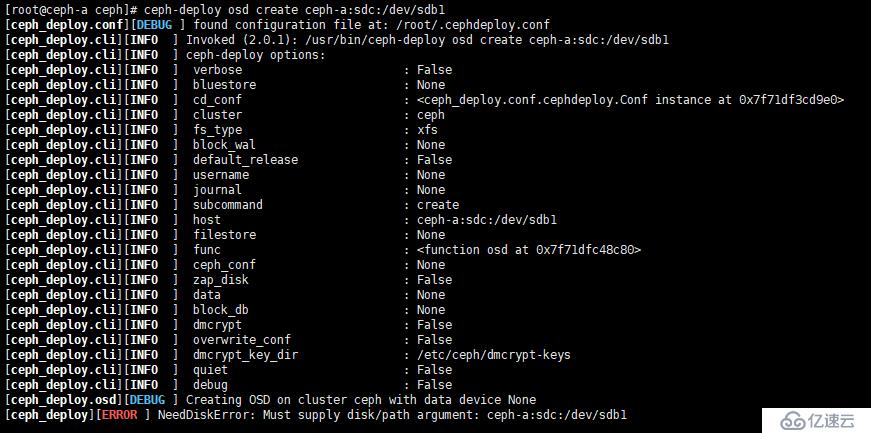
經過上述步驟,我們的 Ceph 算是安裝完成,下面,我們簡單的說下 Ceph 應用,更詳細的應用后期章節再進行解析。
六、使用 RBD(RADOS 塊設備)
1、首先,我們了解一下 Ceph 的存儲方式,Ceph 共支持三種存儲方式:
a、塊存儲,這也是使用最多的存儲方式。
b、CephFS:這種存儲方式了解就行,不建議在生產環境中使用,因為還不夠成熟。
c、對象存儲:該存儲方式也是了解就行,現階段還不夠成熟穩定。僅支持 OpenStack Swift 和 Amazon S3 兩種接口,后期有需要,我們再講解。
2、其次,我們了解一下什么是 ceph 塊存儲:
a、Ceph 塊設備也叫做 RADOS 設備,即:RADOS block device(RBD)。
b、RBD 驅動已經很好的集成在 Linux 內核中。
c、RBD 提供了企業功能,如快照、COW克隆等等。
d、RBD 還支持內存緩存,從而能夠大大提高性能。
e、Linux 內核可以直接房訪問 Ceph 塊存儲。
f、KVM 可用借助于 librdb 訪問。
3、使用 RBD
①、查看存儲池
[root@ceph-a ceph]# ceph osd lspools
一般來說,都會有一個默認的 0 號存儲池,但是呢,在小弟在這里查看的時候,卻沒有默認的 0 號存儲池,不知道是不是官方已將其移除,還需后續繼續觀察。
②、創建 ceph OSD 存儲池
[root@ceph-a ~]# ceph osd pool create cephrbd 512
如圖:

這里,cephrbd 是存儲池的名稱。
● 通常在創建pool之前,需要覆蓋默認的 pg_num,官方推薦:
● 若少于5個OSD, 設置 pg_num 為128。
● 5~10個OSD,設置 pg_num 為512。
● 10~50個OSD,設置 pg_num 為4096。
● 超過50個OSD,可以參考 pgcalc 計算。
③、創建名為 image 的鏡像,大小為10G
[root@ceph-a ~]# rbd create cephrbd/image --image-feature layering --size 10G
cephrbd/image:表示在存儲池 cephrbd 中創建 image 的鏡像
--image-feature:該選項指定使用特性,不用全部開啟。我們的需求僅需要使用快照、分層存儲等特性,開啟layering即可
④、查看 cephrbd 存儲池中是否有鏡像存在
[root@ceph-a ~]# rbd ls cephrbd
如圖:

⑤、查看鏡像信息
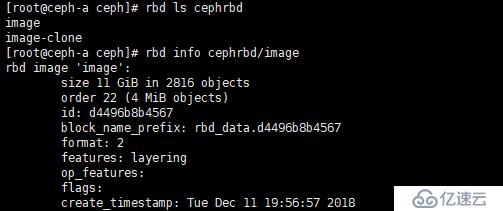
[root@ceph-a ~]# rbd info cephrbd/image
如圖:
⑥、編寫 UDEV 規則,使得 sdb1和 sdb2 重啟后,屬組屬主任然是 ceph
[root@ceph-a ~]# vim /etc/udev/rules.d/87-cephdisk.rules ACTION=="add",KERNEL=="sdb?",OWNER="ceph",GROUP="ceph"
將規則拷貝到 Ceph-B 和 Ceph-C
[root@ceph-a ~]# for i in {b..c}; do scp /etc/udev/rules.d/87-cephdisk.rules ceph-$i:/etc/udev/rules.d/; done4、鏡像操作
①、擴容容量
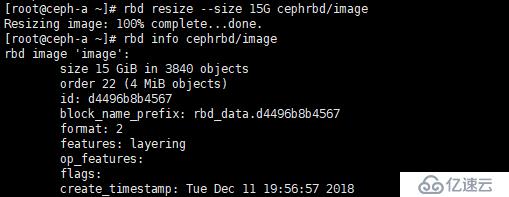
[root@ceph-a ~]# rbd resize --size 15G cephrbd/image
將 image 鏡像擴容到15G
②、縮小容量
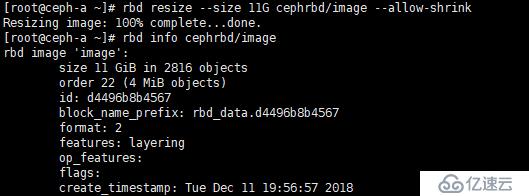
[root@ceph-a ~]# rbd resize --size 11G cephrbd/image --allow-shrink
將image 鏡像容量縮小至11G
③、刪除鏡像
[root@ceph-f ceph]# rbd rm cephrbd/demo-img
5、使用 Ceph 客戶端
在這里,我們將 Ceph-F 服務器做為 Ceph 客戶端,并將之前創建的鏡像 image 映射到 Ceph-F 做為磁盤使用。
a、在 Ceph-F 安裝 Ceph 客戶端軟件
[root@ceph-f ~]# yum -y install ceph-common
b、將 Ceph-A 的 ceph.conf 和 ceph.client.admin.keyring 拷貝到 Ceph-F
[root@ceph-a ceph]# scp ceph.c* ceph-f:/etc/ceph

ceph.client.admin.keyring 是 client.admin 用戶的密鑰文件
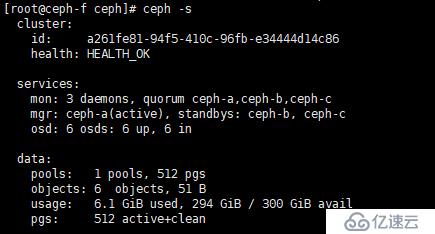
c、查看狀態
[root@ceph-f ~]# ceph -s

d、映射鏡像到本地
[root@ceph-f ceph]# rbd map cephrbd/image
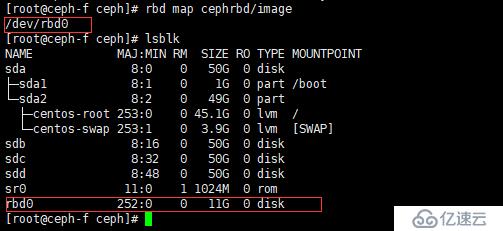

e、查看映射磁盤的信息
[root@ceph-f ceph]# rbd showmapped


f、格式化、掛載 /dev/rbd0
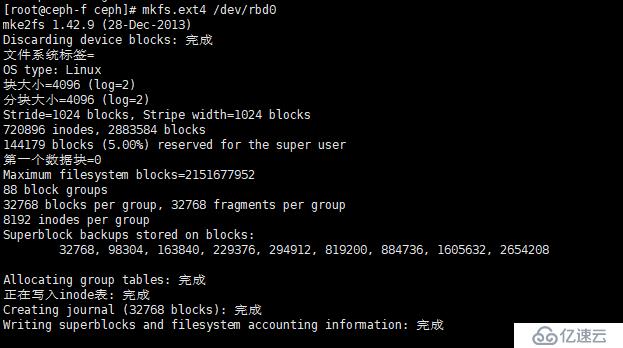
①、格式化 /dev/rbd0
[root@ceph-f ceph]# mkfs.ext4 /dev/rbd0
②、將 /dev/rbd0 掛載到 /image,并添加開機自動掛載
[root@ceph-f ceph]# mkdir /image [root@ceph-f ceph]# mount /dev/rbd0 /image [root@ceph-f ceph]# echo -e "/dev/rbd0 /image ext4 defaults 0 0" >> /etc/fstab
g、往 /image 中寫入數據,并查看數據是否寫入成功
[root@ceph-f ceph]# echo "hello world" >/image/log.txt [root@ceph-f ceph]# cat /image/log.txt
h、創建鏡像快照,為 image 鏡像創建 image-sn1 的快照
[root@ceph-f ceph]# rbd snap create cephrbd/image --snap image-sn1
i、查看 image 快照
[root@ceph-f ceph]# rbd snap ls cephrbd/image


j、刪除鏡像快照
[root@ceph-f ceph]# rbd snap remove cephrbd/image@image-sn1
k、鏡像快照操作
①、通過快照進行數據恢復
刪除 /iamge/log.txt 文件
[root@ceph-f ceph]# rm -rf /image/log.txt
卸載掛載點
[root@ceph-f ceph]# umount /dev/rbd0
使用 image-sn1 還原快照
[root@ceph-f ceph]# rbd snap rollback cephrbd/image --snap image-sn1
再掛載 /dev/rbd0,查看文件是否存在
[root@ceph-f ceph]# mount /dev/rbd0 /image [root@ceph-f ceph]# ll /image/
②、快照克隆
如果你想從快照恢復出一個新的鏡像,則可以使用快照克隆
注意:克隆前,需要對快照進行<保護>(protect)操作,被保護的快照無法刪除,取消保護(unprotect)
[root@ceph-f ceph]# rbd snap protect cephrbd/image --snap image-sn1
嘗試刪除剛才保護的快照
[root@ceph-f ceph]# rbd snap remove cephrbd/image@image-sn1

如上圖,快照無法刪除
克隆 image-sn1 快照,克隆的名稱為 image-clone
[root@ceph-f ceph]# rbd clone cephrbd/image --snap image-sn1 cephrbd/image-clone --image-feature layering
查看克隆快照的狀態
[root@ceph-f ceph]# rbd info cephrbd/image-clone
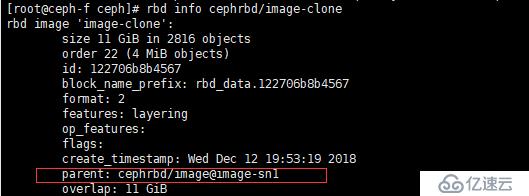
紅框中內容說明是:池 cephrbd 的鏡像 image 的快照 image-sn1 的克隆
③、合并克隆文件
[root@ceph-f ceph]# rbd flatten cephrbd/image-clone

查看合并后的信息
[root@ceph-f ceph]# rbd info cephrbd/image-clone
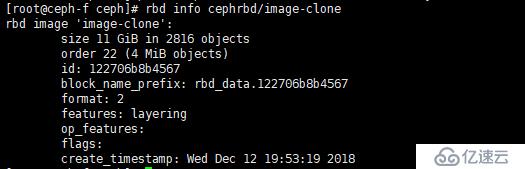
由上圖,我們發現它已經變為一個獨立的鏡像了
查看 cephrbd 池中的鏡像
[root@ceph-f ceph]# rbd ls cephrbd

④、取消映射
[root@ceph-f ceph]# rbd unmap /dev/rbd/cephrbd/image
關于 Ceph 更多的應用,小弟會在后期文章中進行細述,今天,我們就到此結束。
關于 Ceph 塊設備的應用,請參閱小弟的另外一篇博文:https://blog.51cto.com/4746316/2330070
關于 CephFS 文件系統的應用,請參閱小弟的另外一篇博文:https://blog.51cto.com/4746316/2330186
關于 Ceph 對象存儲,請參閱小弟的另外一篇博文:https://blog.51cto.com/4746316/2330455
七、Ceph 部署總結
Ceph 的部署,總體來說還是比較簡單,雖然說,看似簡單,但是越簡單的東西,我們更加需要重視,因為我們認為越簡單的地方,才是我們在日常運維中越容易踩坑的地方。就比如,上面部署過程中,遇到的幾個問題,就連官方文檔中都沒有體現出來,導致小弟在填坑時花了不少心思,但好歹還是找出問題所在了。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





