溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“JAVA集合框架中的常用集合及其特點和實現原理簡介”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Java提供的眾多集合類由兩大接口衍生而來:Collection接口和Map接口
Collection接口
Collection接口定義了一個包含一批對象的集合。接口的主要方法包括:
size() - 集合內的對象數量
add(E)/addAll(Collection) - 向集合內添加單個/批量對象
remove(Object)/removeAll(Collection) - 從集合內刪除單個/批量對象
contains(Object)/containsAll(Collection) - 判斷集合中是否存在某個/某些對象
toArray() - 返回包含集合內所有對象的數組
等
Map接口
Map接口在Collection的基礎上,為其中的每個對象指定了一個key,并使用Entry保存每個key-value對,以實現通過key快速定位到對象(value)。Map接口的主要方法包括:
size() - 集合內的對象數量
put(K,V)/putAll(Map) - 向Map內添加單個/批量對象
get(K) - 返回Key對應的對象
remove(K) - 刪除Key對應的對象
keySet() - 返回包含Map中所有key的Set
values() - 返回包含Map中所有value的Collection
entrySet() - 返回包含Map中所有key-value對的EntrySet
containsKey(K)/containsValue(V) - 判斷Map中是否存在指定key/value
等
在了解了Collection和Map兩大接口之后,我們再來看一下這兩個接口衍生出來的常用集合類:
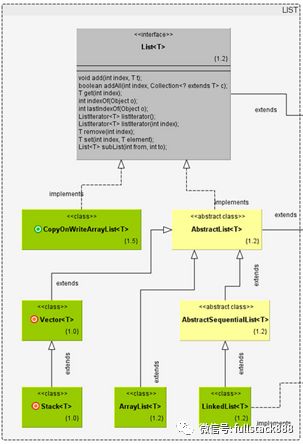
圖片.png
List接口繼承自Collection,用于定義以列表形式存儲的集合,List接口為集合中的每個對象分配了一個索引(index),標記該對象在List中的位置,并可以通過index定位到指定位置的對象。
List在Collection基礎上增加的主要方法包括:
get(int) - 返回指定index位置上的對象
add(E)/add(int, E) - 在List末尾/指定index位置上插入一個對象
set(int, E) - 替換置于List指定index位置上的對象
indexOf(Object) - 返回指定對象在List中的index位置
subList(int,int) - 返回指定起始index到終止index的子List對象
等
List接口的常用實現類:
ArrayList基于數組來實現集合的功能,其內部維護了一個可變長的對象數組,集合內所有對象存儲于這個數組中,并實現該數組長度的動態伸縮
ArrayList使用數組拷貝來實現指定位置的插入和刪除:
插入:

圖片.png
刪除:
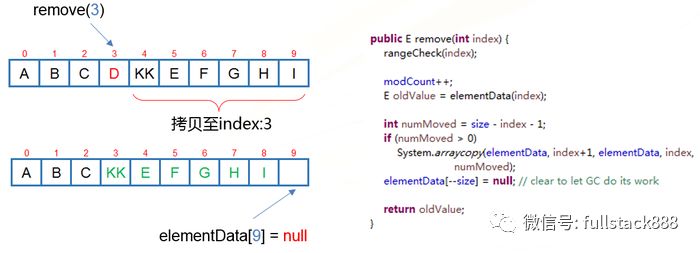
圖片.png
LinkedList基于鏈表來實現集合的功能,其實現了靜態類Node,集合中的每個對象都由一個Node保存,每個Node都擁有到自己的前一個和后一個Node的引用
LinkedList追加元素的過程示例:
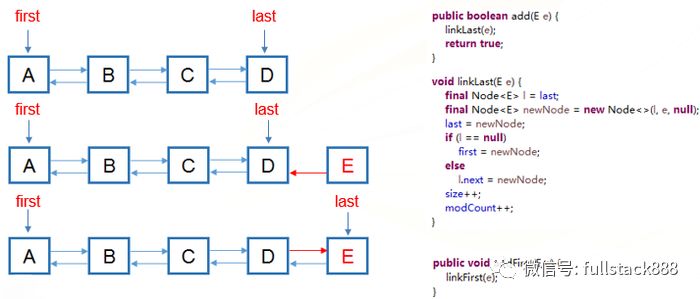
圖片.png
ArrayList vs LinkedList
ArrayList的隨機訪問更高,基于數組實現的ArrayList可直接定位到目標對象,而LinkedList需要從頭Node或尾Node開始向后/向前遍歷若干次才能定位到目標對象
LinkedList在頭/尾節點執行插入/刪除操作的效率比ArrayList要高
由于ArrayList每次擴容的容量是當前的1.5倍,所以LinkedList所占的內存空間要更小一些
二者的遍歷效率接近,但需要注意,遍歷LinkedList時應用iterator方式,不要用get(int)方式,否則效率會很低
Vector和ArrayList很像,都是基于數組實現的集合,它和ArrayList的主要區別在于
Vector是線程安全的,而ArrayList不是
由于Vector中的方法基本都是synchronized的,其性能低于ArrayList
Vector可以定義數組長度擴容的因子,ArrayList不能
與 Vector一樣,CopyOnWriteArrayList也可以認為是ArrayList的線程安全版,不同之處在于 CopyOnWriteArrayList在寫操作時會先復制出一個副本,在新副本上執行寫操作,然后再修改引用。這種機制讓 CopyOnWriteArrayList可以對讀操作不加鎖,這就使CopyOnWriteArrayList的讀效率遠高于Vector。 CopyOnWriteArrayList的理念比較類似讀寫分離,適合讀多寫少的多線程場景。但要注意,CopyOnWriteArrayList只能保證數據的最終一致性,并不能保證數據的實時一致性,如果一個寫操作正在進行中且并未完成,此時的讀操作無法保證能讀到這個寫操作的結果。
Vector vs CopyOnWriteArrayList
二者均是線程安全的、基于數組實現的List
Vector是【絕對】線程安全的,CopyOnWriteArrayList只能保證讀線程會讀到【已完成】的寫結果,但無法像Vector一樣實現讀操作的【等待寫操作完成后再讀最新值】的能力
CopyOnWriteArrayList讀性能遠高于Vector,并發線程越多優勢越明顯
CopyOnWriteArrayList占用更多的內存空間
圖片.png
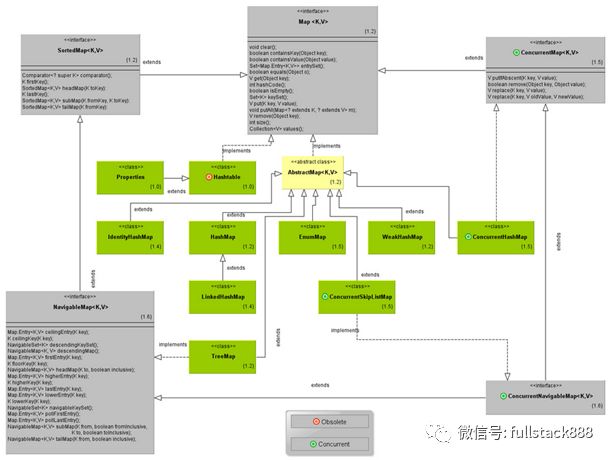
Map將key和value封裝至一個叫做Entry的對象中,Map中存儲的元素實際是Entry。只有在keySet()和values()方法被調用時,Map才會將keySet和values對象實例化。
每一個Map根據其自身特點,都有不同的Entry實現,以對應Map的內部類形式出現。
前文已經對Map接口的基本特點進行過描述,我們直接來看一下Map接口的常用實現類
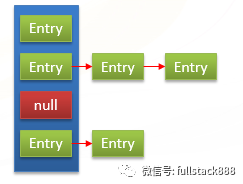
HashMap將Entry對象存儲在一個數組中,并通過哈希表來實現對Entry的快速訪問:
圖片.png
由每個Entry中的key的哈希值決定該Entry在數組中的位置。以這種特性能夠實現通過key快速查找到Entry,從而獲得該key對應的value。在不發生哈希沖突的前提下,查找的時間復雜度是O(1)。
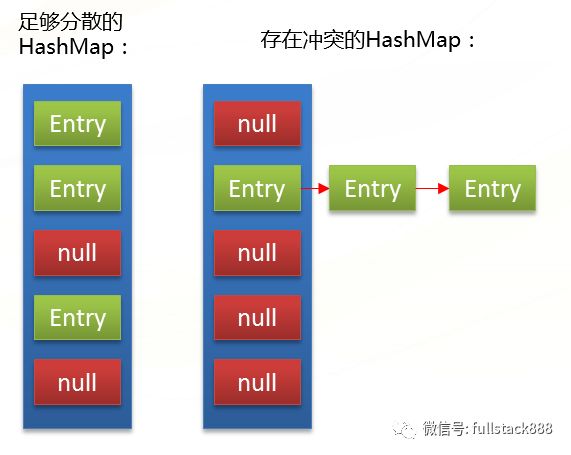
如果兩個不同的key計算出的index是一樣的,就會發生兩個不同的key都對應到數組中同一個位置的情況,也就是所謂的哈希沖突。HashMap處理哈 希沖突的方法是拉鏈法,也就是說數組中每個位置保存的實際是一個Entry鏈表,鏈表中每個Entry都擁有指向鏈表中后一個Entry的引用。在發生哈希沖突時,將沖突的Entry追加至鏈表的頭部。當HashMap在尋址時發現某個key對應的數組index上有多個Entry,便會遍歷該位置上的 Entry鏈表,直到找到目標的Entry。
圖片.png
HashMap的Entry類:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash;}HashMap由于其快速尋址的特點,可以說是最經常被使用的Map實現類
Hashtable 可以說是HashMap的前身(Hashtable自JDK1.0就存在,而HashMap乃至整個Map接口都是JDK1.2引入的新特性),其實現思 路與HashMap幾乎完全一樣,都是通過數組存儲Entry,以key的哈希值計算Entry在數組中的index,用拉鏈法解決哈希沖突。二者最大的不同在于,Hashtable是線程安全的,其提供的方法幾乎都是同步的。
ConcurrentHashMap是HashMap的線程安全版(自JDK1.5引入),提供比Hashtable更高效的并發性能。
圖片.png
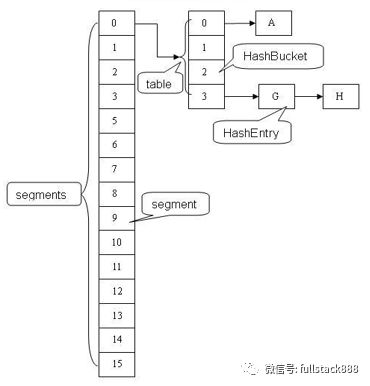
Hashtable 在進行讀寫操作時會鎖住整個Entry數組,這就導致數據越多性能越差。而ConcurrentHashMap使用分離鎖的思路解決并發性能,其將 Entry數組拆分至16個Segment中,以哈希算法決定Entry應該存儲在哪個Segment。這樣就可以實現在寫操作時只對一個Segment 加鎖,大幅提升了并發寫的性能。
在進行讀操作時,ConcurrentHashMap在絕大部分情況下都不需要加鎖,其Entry中的value是volatile的,這保證了value被修改時的線程可見性,無需加鎖便能實現線程安全的讀操作。
ConcurrentHashMap的HashEntry類:
static final class HashEntry<K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next;}但是魚與熊掌不可兼得,ConcurrentHashMap的高性能是有代價的(否則Hashtable就沒有存在價值了),那就是它不能保證讀操作的絕對 一致性。ConcurrentHashMap保證讀操作能獲取到已存在Entry的value的最新值,同時也能保證讀操作可獲取到已完成的寫操作的內容,但如果寫操作是在創建一個新的Entry,那么在寫操作沒有完成時,讀操作是有可能獲取不到這個Entry的。
HashMap vs Hashtable vs ConcurrentHashMap
三者在數據存儲層面的機制原理基本一致
HashMap不是線程安全的,多線程環境下除了不能保證數據一致性之外,還有可能在rehash階段引發Entry鏈表成環,導致死循環
Hashtable是線程安全的,能保證絕對的數據一致性,但性能是問題,并發線程越多,性能越差
ConcurrentHashMap 也是線程安全的,使用分離鎖和volatile等方法極大地提升了讀寫性能,同時也能保證在絕大部分情況下的數據一致性。但其不能保證絕對的數據一致性, 在一個線程向Map中加入Entry的操作沒有完全完成之前,其他線程有可能讀不到新加入的Entry
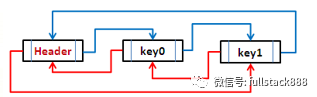
LinkedHashMap與HashMap非常類似,唯一的不同在于前者的Entry在HashMap.Entry的基礎上增加了到前一個插入和后一個插入的Entry的引用,以實現能夠按Entry的插入順序進行遍歷。
圖片.png
TreeMap是基于紅黑樹實現的Map結構,其Entry類擁有到左/右葉子節點和父節點的引用,同時還記錄了自己的顏色:
static final class Entry<K,V> implements Map.Entry<K,V> { K key; V value; Entry<K,V> left = null; Entry<K,V> right = null; Entry<K,V> parent; boolean color = BLACK;}紅黑樹實際是一種算法復雜但高效的平衡二叉樹,具備二叉樹的基本性質,即任何節點的值大于其左葉子節點,小于其右葉子節點,利用這種特性,TreeMap能夠實現Entry的排序和快速查找。
關于紅黑樹的具體介紹,可以參考這篇文章,非常詳細:http://blog.csdn.net/chenssy/article/details/26668941
TreeMap的Entry是有序的,所以提供了一系列方便的功能,比如獲取以升序或降序排列的KeySet(EntrySet)、獲取在指定key(Entry)之前/之后的key(Entry)等等。適合需要對key進行有序操作的場景。
ConcurrentSkipListMap同樣能夠提供有序的Entry排列,但其實現原理與TreeMap不同,是基于跳表(SkipList)的:
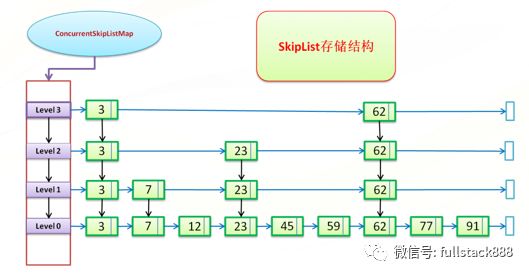
圖片.png
如上圖所示,ConcurrentSkipListMap由一個多級鏈表實現,底層鏈上擁有所有元素,逐級上升的過程中每個鏈的元素數遞減。在查找時從頂層鏈出發,按先右后下的優先級進行查找,從而實現快速尋址。
static class Index<K,V> { final Node<K,V> node; final Index<K,V> down;//下引用 volatile Index<K,V> right;//右引用}與TreeMap不同,ConcurrentSkipListMap在進行插入、刪除等操作時,只需要修改影響到的節點的右引用,而右引用又是volatile的,所以ConcurrentSkipListMap是線程安全的。但ConcurrentSkipListMap與ConcurrentHashMap一樣,不能保證數據的絕對一致性,在某些情況下有可能無法讀到正在被插入的數據。
TreeMap vs ConcurrentSkipListMap
二者都能夠提供有序的Entry集合
二者的性能相近,查找時間復雜度都是O(logN)
ConcurrentSkipListMap會占用更多的內存空間
ConcurrentSkipListMap是線程安全的,TreeMap不是
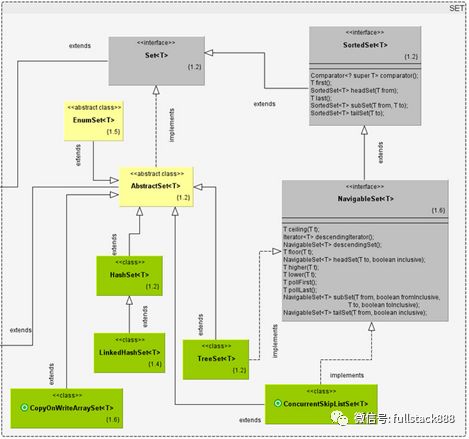
Set 接口繼承Collection,用于存儲不含重復元素的集合。幾乎所有的Set實現都是基于同類型Map的,簡單地說,Set是閹割版的Map。每一個Set內都有一個同類型的Map實例(CopyOnWriteArraySet除外,它內置的是CopyOnWriteArrayList實例),Set把元素作為key存儲在自己的Map實例中,value則是一個空的Object。Set的常用實現也包括 HashSet、TreeSet、ConcurrentSkipListSet等,原理和對應的Map實現完全一致,此處不再贅述。
圖片.png
圖片.png
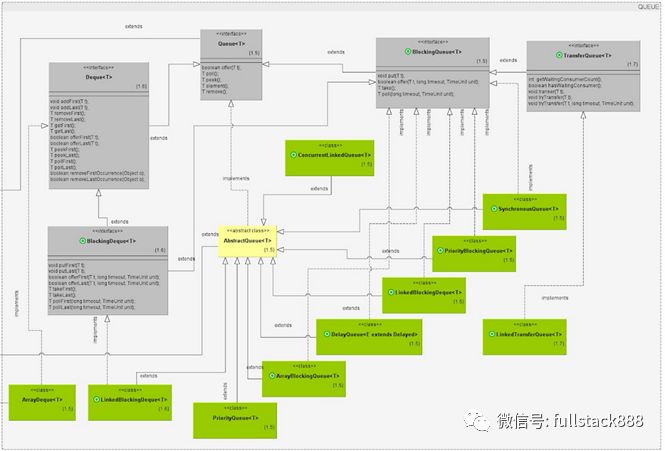
Queue和Deque接口繼承Collection接口,實現FIFO(先進先出)的集合。二者的區別在于,Queue只能在隊尾入隊,隊頭出隊,而Deque接口則在隊頭和隊尾都可以執行出/入隊操作
Queue接口常用方法:
add(E)/offer(E):入隊,即向隊尾追加元素,二者的區別在于如果隊列是有界的,add方法在隊列已滿的情況下會拋出IllegalStateException,而offer方法只會返回false
remove()/poll():出隊,即從隊頭移除1個元素,二者的區別在于如果隊列是空的,remove方法會拋出NoSuchElementException,而poll只會返回null
element()/peek():查看隊頭元素,二者的區別在于如果隊列是空的,element方法會拋出NoSuchElementException,而peek只會返回null
Deque接口常用方法:
addFirst(E) / addLast(E) / offerFirst(E) / offerLast(E)
removeFirst() / removeLast() / pollFirst() / pollLast()
getFirst() / getLast() / peekFirst() / peekLast()
removeFirstOccurrence(Object) / removeLastOccurrence(Object)
Queue接口的常用實現類:
ConcurrentLinkedQueue是基于鏈表實現的隊列,隊列中每個Node擁有到下一個Node的引用:
private static class Node<E> { volatile E item; volatile Node<E> next;}由于Node類的成員都是volatile的,所以ConcurrentLinkedQueue自然是線程安全的。能夠保證入隊和出隊操作的原子性和一致性,但在遍歷和size()操作時只能保證數據的弱一致性。
與ConcurrentLinkedQueue不同,LinkedBlocklingQueue是一種無界的阻塞隊列。所謂阻塞隊列,就是在入隊時如果隊列已滿,線程會被阻塞,直到隊列有空間供入隊再返回;同時在出隊時,如果隊列已空,線程也會被阻塞,直到隊列中有元素供出隊時再返回。LinkedBlocklingQueue同樣基于鏈表實現,其出隊和入隊操作都會使用ReentrantLock進行加鎖。所以本身是線程安全的,但同樣的,只能保證入隊和出隊操作的原子性和一致性,在遍歷時只能保證數據的弱一致性。
ArrayBlockingQueue是一種有界的阻塞隊列,基于數組實現。其同步阻塞機制的實現與LinkedBlocklingQueue基本一致,區別僅在于前者的生產和消費使用同一個鎖,后者的生產和消費使用分離的兩個鎖。
ConcurrentLinkedQueue vsLinkedBlocklingQueue vs ArrayBlockingQueue
ConcurrentLinkedQueue是非阻塞隊列,其他兩者為阻塞隊列
三者都是線程安全的
LinkedBlocklingQueue是無界的,適合實現不限長度的隊列, ArrayBlockingQueue適合實現定長的隊列
SynchronousQueue算是JDK實現的隊列中比較奇葩的一個,它不能保存任何元素,size永遠是0,peek()永遠返回null。向其中插入元素的線程會阻塞,直到有另一個線程將這個元素取走,反之從其中取元素的線程也會阻塞,直到有另一個線程插入元素。
這種實現機制非常適合傳遞性的場景。也就是說如果生產者線程需要及時確認到自己生產的任務已經被消費者線程取走后才能執行后續邏輯的場景下,適合使用SynchronousQueue。
這兩種Queue并不是FIFO隊列,而是根據元素的優先級進行排序,保證最小的元素最先出隊,也可以在構造隊列時傳入Comparator實例,這樣PriorityQueue就會按照Comparator實例的要求對元素進行排序。
PriorityQueue是非阻塞隊列,也不是線程安全的,PriorityBlockingQueue是阻塞隊列,同時也是線程安全的。
Deque 的實現類包括LinkedList(前文已描述過)、ConcurrentLinkedDeque、LinkedBlockingDeque,其實現機制與前文所述的ConcurrentLinkedQueue和LinkedBlockingQueue非常類似,此處不再贅述
最后,對本文中描述的常用集合實現類做一個簡單總結:
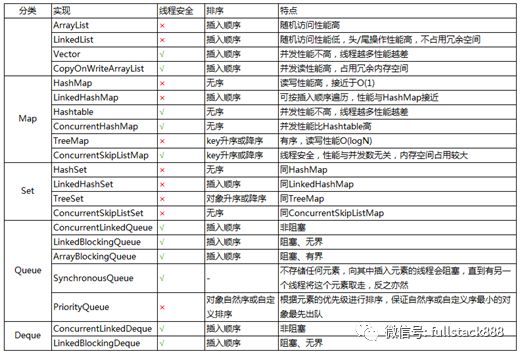
“JAVA集合框架中的常用集合及其特點和實現原理簡介”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





