溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹PB級數據分析工具Prestodb怎么用,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
prestodb,是facebook開源的一款sql on hadoop系統,是facebook的工程師對hive的查詢速度忍無可忍后,下決心開發的一款高性能查詢引擎,基于java8編寫,其基于page的pipeline技術,使其具有高效的交互式查詢性能,并可以高效的控制GC;而其和底層數據源解耦的特性,使其能夠對接各類數據源,并具有跨源查詢的特性。目前在國內,有京東、美團、同城以及滴滴等公司對prestodb有深度使用,在國外,除facebook外,還有uber等公司對prestodb有深度使用,而teradata公司則在維護獨立的分支,并將其作為自己的主打的即系查詢產品的后臺。本文介紹prestodb,先主要介紹presto的架構和查詢原理,presto的搭建比較簡單,大家可以參考官網的文章進行操作。
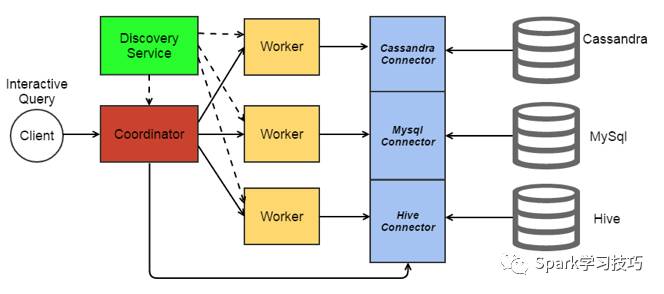
如上圖所示,prestodb主要由一個coordinator和多個worker組成,coordinaor節點負責和client對接,接收client發送過來的各類請求(DDL和DML)。coordinator在接收到client的請求后,就開始進行請求的處理,最后把查理結果返回給client。coordinator在進行請求處理時,對各類sql語句進行詞法解析、語法分析、語義分析、優化、生成執行計劃最后在調度模塊進行任務的分發,把子任務分發到各個worker節點。worker節點是實際的執行節點,會執行包括聚合、排序、join以及去重等操作。整體執行流程如下圖所示: 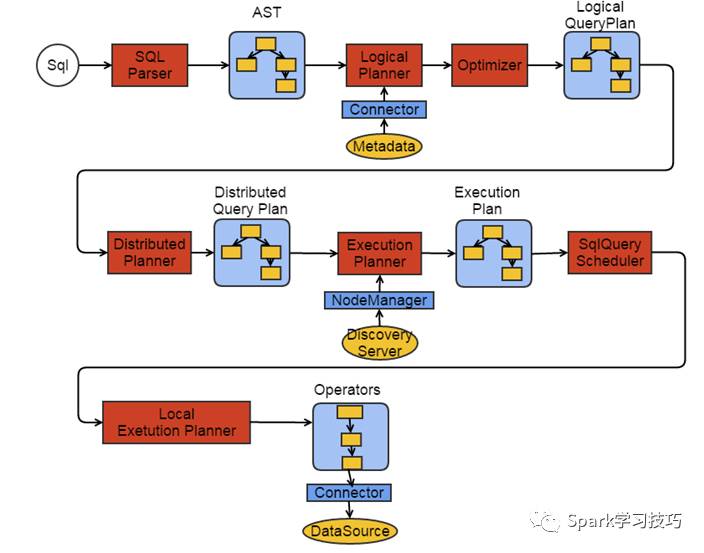
其中大多數流程會在后邊會進行詳細的介紹。
這篇文章的主要目的是入門和普及分布式sql的執行原理,看過一些其他的相關文章,都是從上到下的介紹,個人感覺這樣不利于入門,很多人看到執行計劃那里就“知難而退”了。所以我在介紹presto時,準備采用從下到上的方式來介紹。
分布式sql說白了也是sql,既然是sql,典型的幾個查詢語句就是groupby、orderby、join等。本文以groupby為例來進行介紹,orderby和join等的執行流程也會在后續文章中進行介紹。
物理執行計劃是最接近我們理解的一個步驟了,所以這里先來看看presot中得物理執行計劃。假設我們有一張訂單表,這個訂單表的數據分布在兩個節點上,node1上的數據分片是: 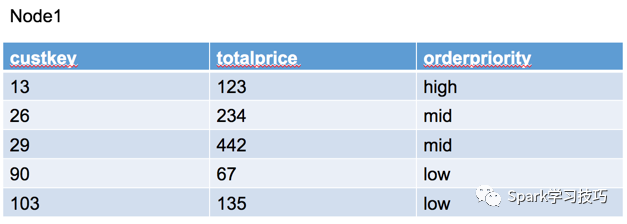
node2上得數據分片是: 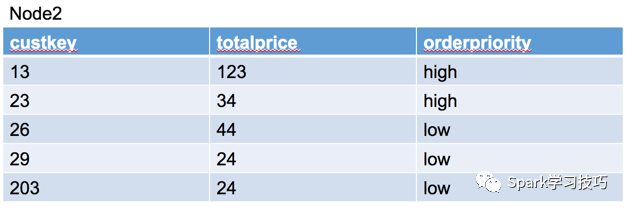
假設我們有這樣一個分組聚合查詢查詢:
SELECT sum(totalprice),orderpriorityFROM orderswhere custkey<100GROUP BY orderpriority
這個查詢中有過濾(custkey<100),有分組(group by orderpriority),有聚合(sum),是一個非常典型的數據庫查詢語句。我們先不看presto怎么實現這樣的查詢,我們可以先自己想想如果我們自己去完成這樣的操作我們要怎么做?首先,我們肯定會先從數據源讀取數據,但是讀到數據并非符合我們的需要,這時我們就需要對數據按照一定的條件進行過濾,過濾完之后的數據就是我們感興趣的數據;那么過濾完之后留下的數據我們是先聚合還是先分組呢?肯定是先分組了,如果沒有分組,聚合也就無從談起了,因為聚合就是針對一個組內的數據進行的聚合,如果是不同組就沒有聚合的必要了。分組的方法很多,可以使用hash的方式完成分組,也可以使用sort的方式完成分組,或者更高級的,如果有倒排索引,組已經就是分好的了,省了很多事情。presto采用hash的方式完成分組。等分組完成后,就可以在一個組內進行聚合操作了,比如進行計數統計、求和或者求平均等。
好了,那么我們看看presot的執行流程(物理執行計劃)是否符合我們的預期: 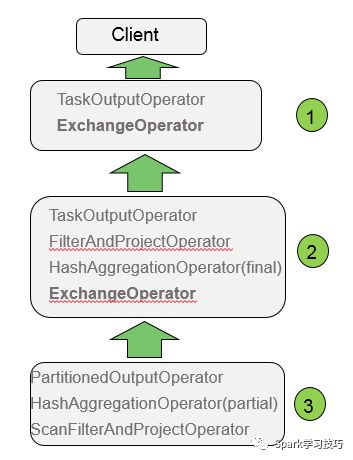
上圖所示有三個大的方框,每個方框表示一個presto執行過程中的一個stage(類似spark中的stage,以shuffle操作作為stage的邊界),先看標號為3的方框,在這個方框內有三個operator,最下邊的是ScanFilterAndProjectOperotor,從名字就可以看出,這個物理操作符的主要任務是掃描、過濾和投影,掃描和過濾后的數據如下: 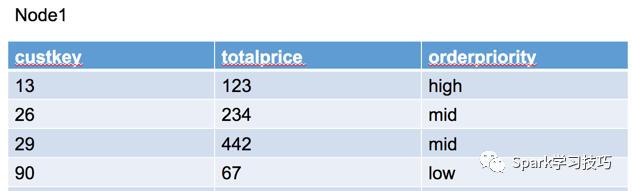
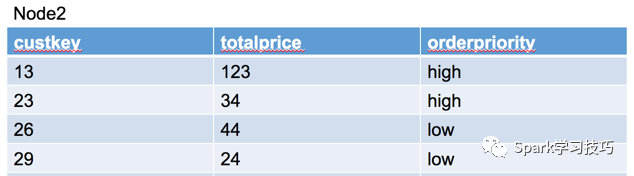
可以看出,custkey大于100的行已經被過濾掉了。這里的投影(project)的意思是把上層operator需要的字段值篩選出來,以上圖的sql為例,要帥選的字段包括orderpriority和totalprice,因為這兩個字段才是后續的分組和聚合需要的字段,而字段custkey只是起了一個過濾數據的作用,所以在project是不會被向上層傳遞。所以上層operator接收到的數據如下: 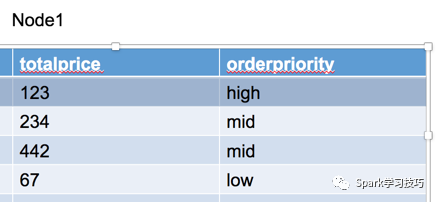
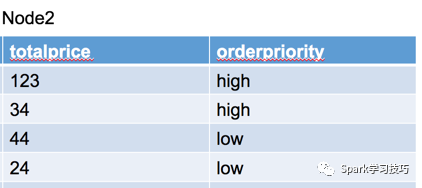
等數據被發送到上一級的operator后,就要開始進行分組了,這里用到的操作符是HashAggregationOperator,從名字可以看出,這里使用了hash的方式對數據進行了分組,即把具有相同hash值的數據作為一個組,同時在分組完成后進行了聚合操作(Aggregation),注意這里的HashAggregationOperator后跟了一個(partial)關鍵字,表示這一步的分組和聚合只是完成一個局部的分組聚合,這是因為數據在分布式環境下,一個group的數據可能是存在多個partition下,甚至是跨不同物理機的,所以需要首先完成局部聚合,降低后續要進行shuffle的數據量。這就類似spark中的reduceByKey算子,可以對數據進行map side combine,從而減少shuffle時數據的傳輸量,而如果使用groupByKey,沒有進行map side combine,就會產生大量的數據需要通過網絡傳輸。經過這個局部聚合后的數據如下圖所示: 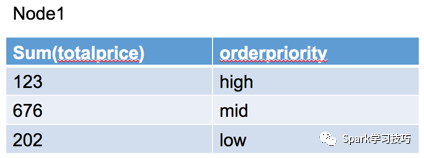

其中在node1,有三個分組,分別是high,mid,low,在node2右兩個分組,分別是high和low。
在往上看,操作符是PartitionedOutputOperator,可以看出這是一個分區操作,主要是把上一步聚合分組和聚合的結果根據分組的key(即組名,例如high,low等)進行分區,寫到不同的分區文件中(類似spark的shuffle操作中shuffle write)。至此,方框3(stage 3)中的操作完成。
接下來到了stage2 ,在這個stage中,首先要進行的上一個stage最后階段輸出數據的拉取(類似spark中得shuffle read),在presto中對應的操作符是ExchangeOperator,拉取了數據之后,展現給上一層操作符的數據如下: 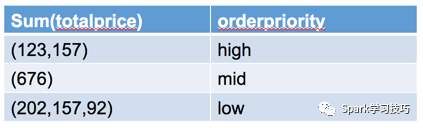
可以看出,不同節點相同分組key的數據已經被聚合分組在一起了,這時只需要再進行一次聚合操作即可最終的分組聚合操作。在進行分組聚合查詢時,經常會使用到hiving這樣的操作,而再上一層的FilterAndProject操作就是進行分組聚合結果的過濾和投影,最后把這樣的處理結果交給最后一個stage,即stage1,進行結果的輸出。
至此,一個典型的group by查詢的分布式物理執行計劃就按照一定的邏輯執行完成了。從以上這個物理執行流程,我們可以看出presto在進行分布式數據處理時和sparksql有諸多類似的地方,其實不止是和sparksql類似,所有的分布式sql都是遵循這樣那個的基本原理。
關于PB級數據分析工具Prestodb怎么用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





