溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何從RocketMQ消息持久化設計看磁盤性能瓶頸的突破,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
分布式消息隊列通常有高可靠性的要求,所以消息數據是需要持久化存儲的。那么以什么方式來進行持久化是一個值得商榷的問題。
從存儲方式和效率來看,文件系統 > KV存儲 > 關系型數據庫,直接操作文件系統自然是最快的一種存儲方式,但是僅僅如此就可以了嗎?
當然不是,在無數的過往學習中,磁盤IO性能拖累系統性能是眾所周知的。那么RocketMQ是怎么解決呢?
各位看官且待我慢慢道來。
首先我們回憶一下,假如現在有一個字你不認識,然后你手上正巧有一本漢語言辭典,請問該怎么做才能以最快的速度查到這個字?
凡是上過小學的人,應該都不會從漢語言辭典第一頁開始一頁一頁的查找。
作為優秀小學畢業生的我們,肯定是先通過偏旁檢索到這個字,然后根據檢索上這個字的頁碼,到漢語言辭典里對應的頁碼中去找到這個字,于是你就知道它讀什么了。
大道相通。
RocketMQ在文件系統中,把所有的消息都存在了同一個文件中,這就像一本厚厚的漢語言辭典,作為消費者,想要做到最大效率的實時消費,說白了就是要快速定位到這個消息在文件中的位置,肯定不能從文件偏移量0開始向下查找。
一張圖頂幾百字:
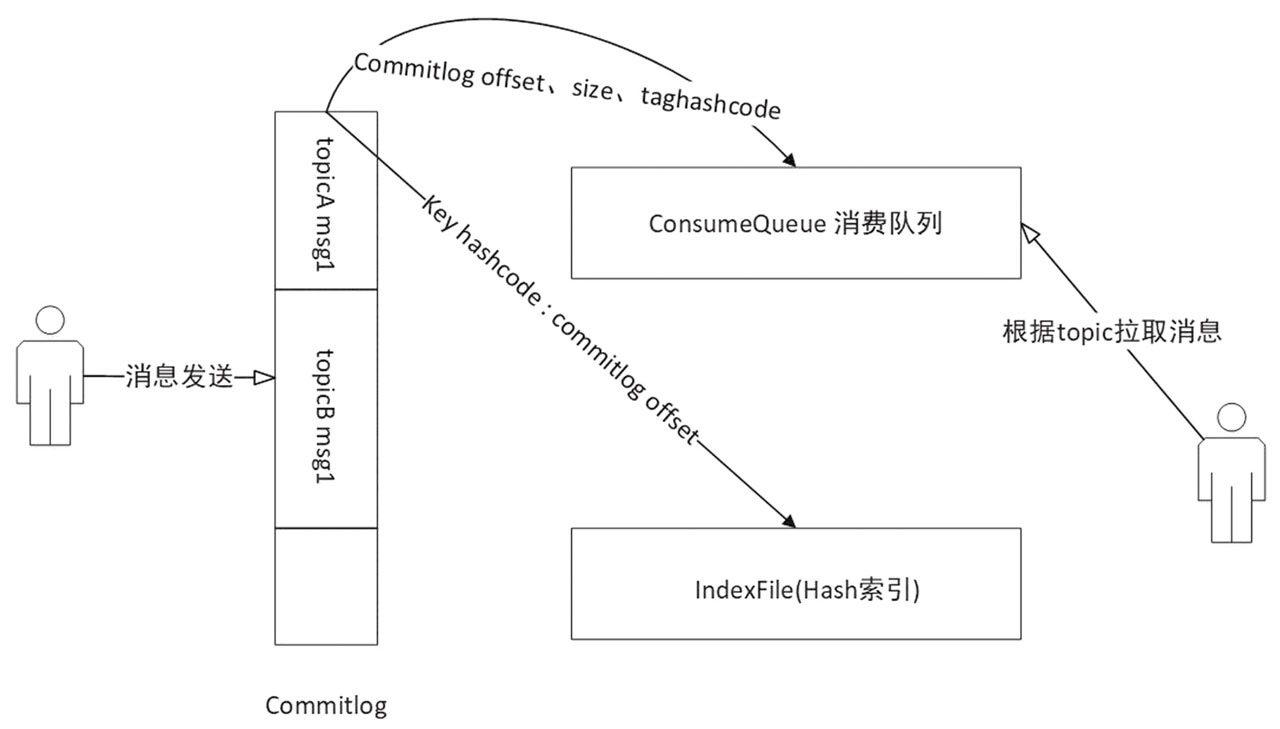
RocketMQ主要存儲文件有三個,分別是:
CommitLog:消息存儲文件,所有的消息存在這里;
ConsumeQueue:消費隊列文件,消息在存儲到CommitLog后,會將消息所在CommitLog偏移量、大小、tag的hashcode異步轉發到消費隊列存儲,供消費者消費,其類似于數據庫的索引文件,存儲的是指向物理存儲的地址,每個topic下的每個Message Queue都有一個對應的ConsumeQueue文件;
Index:索引文件,消息在存儲到CommitLog后,會將消息key與消息所在CommitLog偏移量轉發到索引文件存儲,供消息查詢。
從原理圖中,我們可以看出消息的生產與消費進行了分離,Producer端發送消息最終寫入的是CommitLog,Consumer端先從ConsumeQueue讀取持久化消息的起始物理位置偏移量offset、大小size和消息Tag的HashCode值,再從CommitLog中進行讀取待拉取消費消息的真正實體內容部分。
上面說了消費者如何快速定位到消息位置,使消費者可以高效的消費,那么下面我們說說RocketMQ中如何做到消息存儲的高效性。
我們先思考一個問題,假如你是印刷廠的老板,你如何才能快速印刷出一本完整沒有錯誤的漢語言辭典呢?
答案很簡單,從第一頁開始,按照順序一頁一頁的印刷,不要跳頁印刷,更不要隨機印刷。
正如我們的磁盤寫入一樣,據某某調查研究表明,高性能磁盤在順序寫入的時候,速度基本可以堪比內存的寫入速度,但是磁盤隨機寫入的時候,性能瓶頸非常明顯,速度會比較慢。
所以RocketMQ采用了全部消息都存入一個CommitLog文件中,并且對寫操作加鎖(putMessageLock),保證串行順序寫入消息,避免磁盤竟爭導致IO WAIT增高,大大提高寫入效率。
我們可以用一個更詳細的圖來說明:
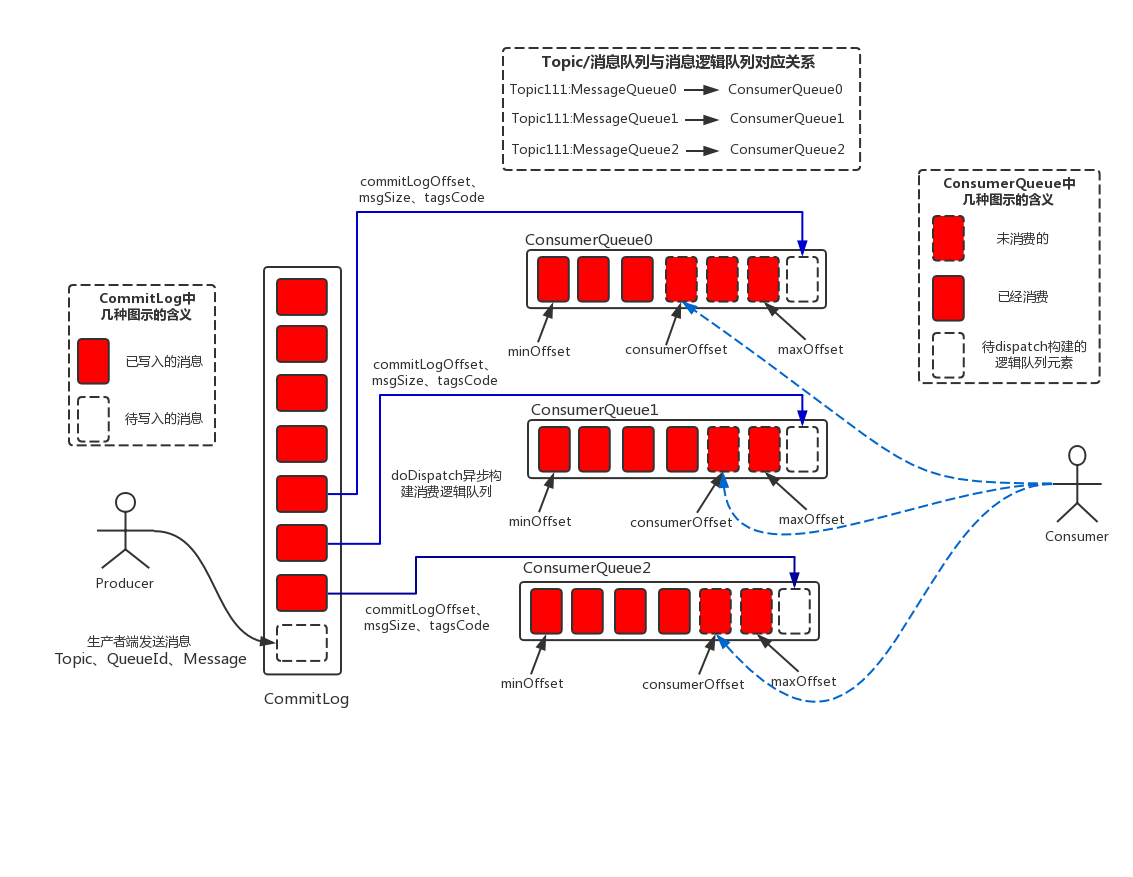
生產者按順序寫入CommitLog,消費者通過順序讀取ConsumeQueue進行消費,這里有一個地方需要注意,雖然消費者是按照順序讀取ConsumeQueue,但是并不代表它就是按照順序讀取消息,因為根據ConsumeQueue中的起始物理位置偏移量offset讀取消息真實內容,在并發量非常高的情況下,實際上是隨機讀取CommitLog,而隨機讀取文件帶來的性能開銷影響還是比較大的,所以在這里,RocketMQ利用了操作系統的pagecache機制,批量從磁盤讀取,作為cache存在內存中,加速后速的讀取速度。
我們打開RocketMQ在磁盤上持久化的目錄(store目錄下),便可以很直觀的看到CommitLog,ConsumeQueue,Index三個文件夾。(其中config文件夾中是運行期間一些配置信息,而abort,checkpoint我會在后續的文章中講述它們的作用,關注“IT一刻鐘”吧,不要在猶豫中錯過了重要內容!)


可以看到每個文件1G大小,以該文件中第一個偏移量為文件名,偏移量小于20位用0補齊。如圖所示,第一個文件的初始偏移量為9663676416,第二個文件的初始偏移量為10737418240。
CommitLog文件內部存儲邏輯是,每條消息的前4個字節存儲該條消息的總長度(包含長度信息本身),隨后便是消息內容。如圖所示:

消息的長度=消息長度信息(4字節)+ 消息內容長度。
實現消息查找的步驟:
1.消費者從消費隊列中獲取到某個消息的偏移量offset與長度size;
2.根據偏移量offset定位到消息所在的commitLog物理文件;
3.用偏移量與文件長度取模,得到消息在這個commitLog文件內部的偏移量;
4.從該偏移量取得size長度的內容返回即可。
注:如果只是根據消息偏移量查找消息,則首先找到文件內偏移量,然后讀取前4個字節獲取消息的實際長度,然后讀取指定的長度。 這里有一個比較巧妙的設計,CommitLog文件并不是每次生成一個,然后寫滿之后再創建下一個,而是有一個預分配的機制。
即,CommitLog創建過程是把下一個文件的路徑、下下個文件的路徑以及文件大小作為參數封裝到AllocateRequest對象并添加到隊列中,后臺運行的AllocateMappedFileService服務線程會不停地run,只要請求隊列里存在請求對象,就會去創建下個CommitLog,同時還會將下下個CommitLog預先創建并保存至請求隊列中等待下次獲取時直接返回,不用再次因為等待CommitLog創建分配而產生時間延遲。
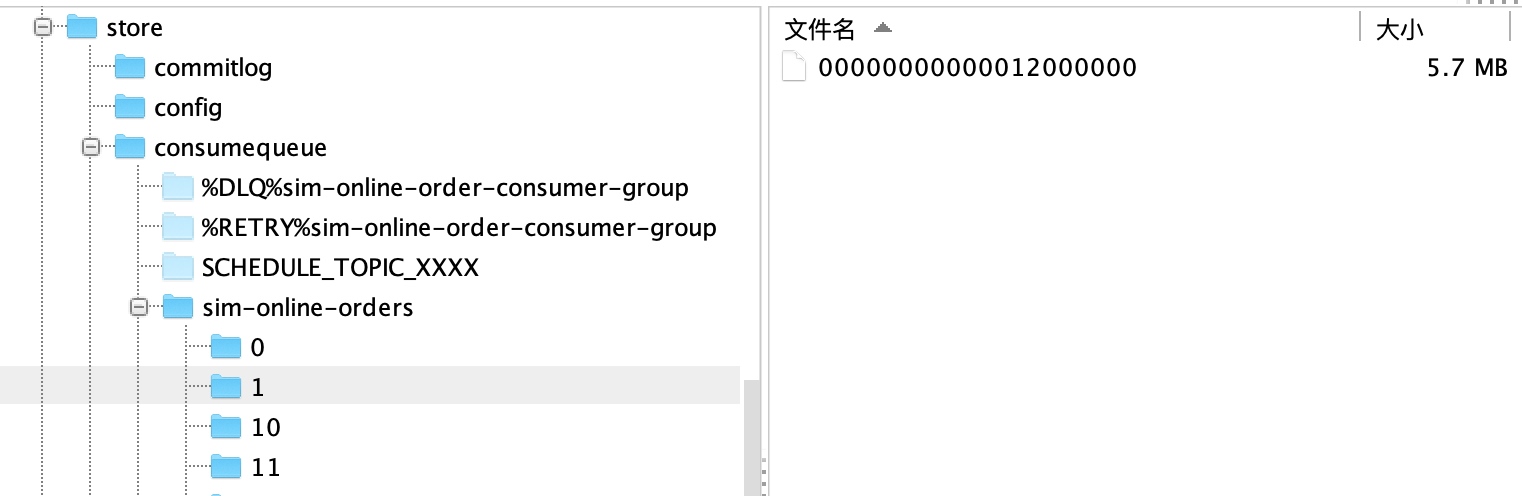
對于消費者來說,最關心的莫過于某個主題下的所有消息,但是在RocketMQ中,不同主題下的消息都交錯雜糅在同一個文件里,想要提高查詢速度,必須要構建類似于搜索索引的文件,于是就有了消費隊列ConsumeQueue文件。
從實際物理存儲來說,ConsumeQueue對應每個Topic和QueuId下面的文件,在上圖中,00000000000012000000就是在主題為sim-online-orders,QueueId為1下的ConsumeQueue文件。單個文件大小約5.72M,每個文件由30W條數據組成,每個文件默認大小為600萬個字節,即每條數據20個字節。當一個ConsumeQueue類型的文件寫滿了,則寫入下一個文件。
ConsumeQueue文件內部存儲邏輯如圖:
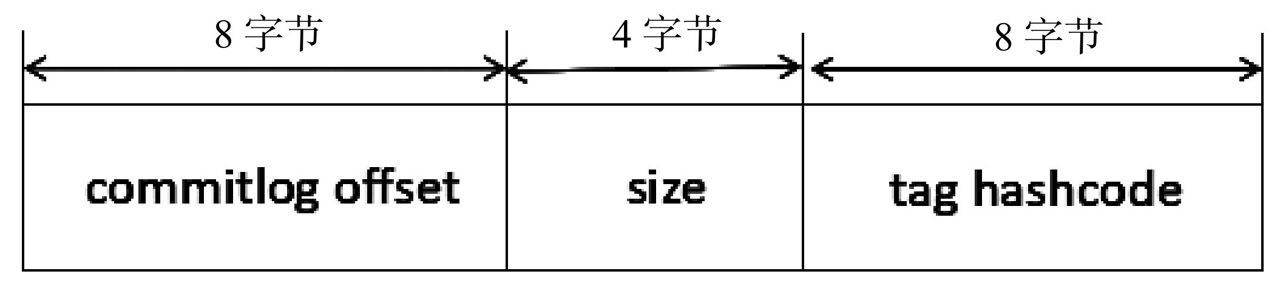
包含消息在commitLog文件的偏移量,消息長度,消息tag的HashCode。 單個ConsumeQueue文件可以看作是ConsumeQueue條目數組,其下標是ConsumeQueue的邏輯偏移量。
消息消費隊列是RocketMQ為消息訂閱構建的索引文件,目的在于提高主題與消息隊列檢索消息的速度。

RocketMQ為了通過消息Key值查詢消息真正的實體內容,引入了Hash索引機制。在實際的物理存儲上,文件名則是以創建時的時間戳命名的,固定的單個IndexFile文件大小約為400M,一個IndexFile可以保存2000W個索引。
我們先來看看Index索引文件的內部存儲邏輯:
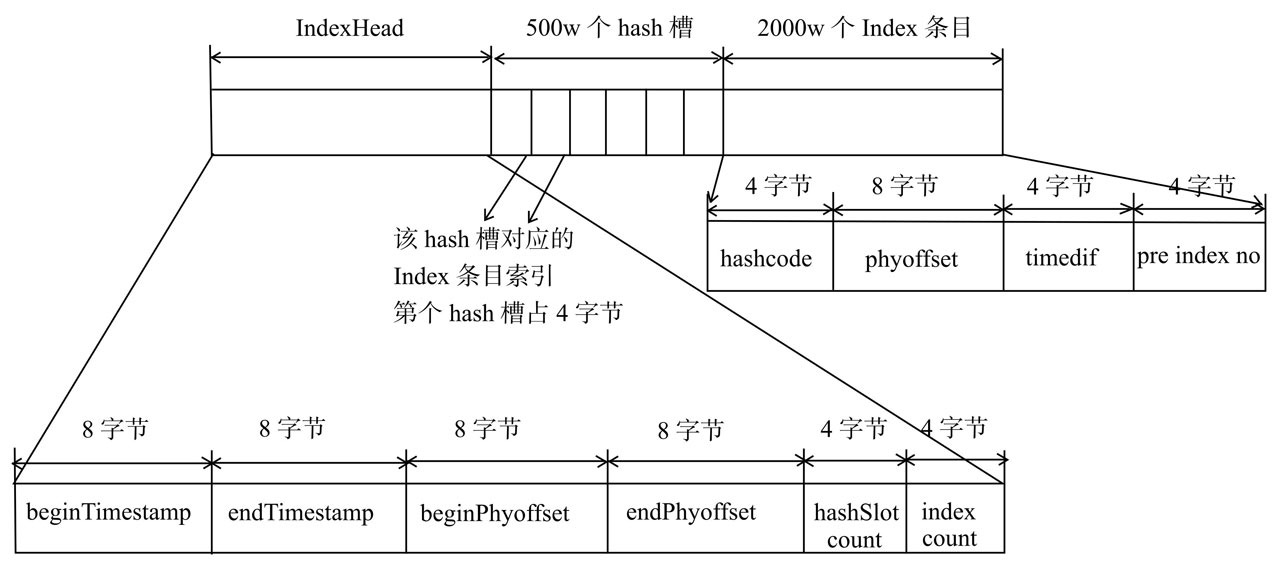
IndexFile包含三個部分:IndexHead,Hash槽,Index條目。
1.IndexHead,包含40個字節,記錄一些統計信息:
beginTimestamp:該索引文件中包含消息的最小存儲時間。
endTimestamp:該索引文件中包含消息的最大存儲時間。
beginPhyoffset:該索引文件中包含消息的最小物理偏移量(commitlog文件偏移量)。
endPhyoffset:該索引文件中包含消息的最大物理偏移量(commitlog文件偏移量)。
hashslotCount: hashslot個數,并不是hash槽使用的個數,在這里意義不大。
indexCount: Index條目列表當前已使用的個數,Index條目在Index條目列表中按順序存儲。
2.Hash槽,默認500萬個槽,每個槽位存儲著該消息key的HashCode所對應的最新Index條目的下標數。
3.Index條目列表,默認一個索引文件包含2000萬個條目:
hashcode:key的HashCode。
phyoffset:消息對應的物理偏移量。
timedif:該消息存儲時間與第一條消息的時間戳的差值,小于0該消息無效。
preIndexNo:該HashCode上一個條目的Index索引,當出現hash沖突時,構建的鏈表結構。
大家看懂了這個數據結構沒有?設計的真是精妙。
如果沒有理解,我給大家畫個圖,來體會一下這個數據結構的精妙:
首先根據key的HashCode對槽數取模,得到槽位,然后將相應的數據按順序存入到Index條目中,同時將條目數存回對應的槽內。
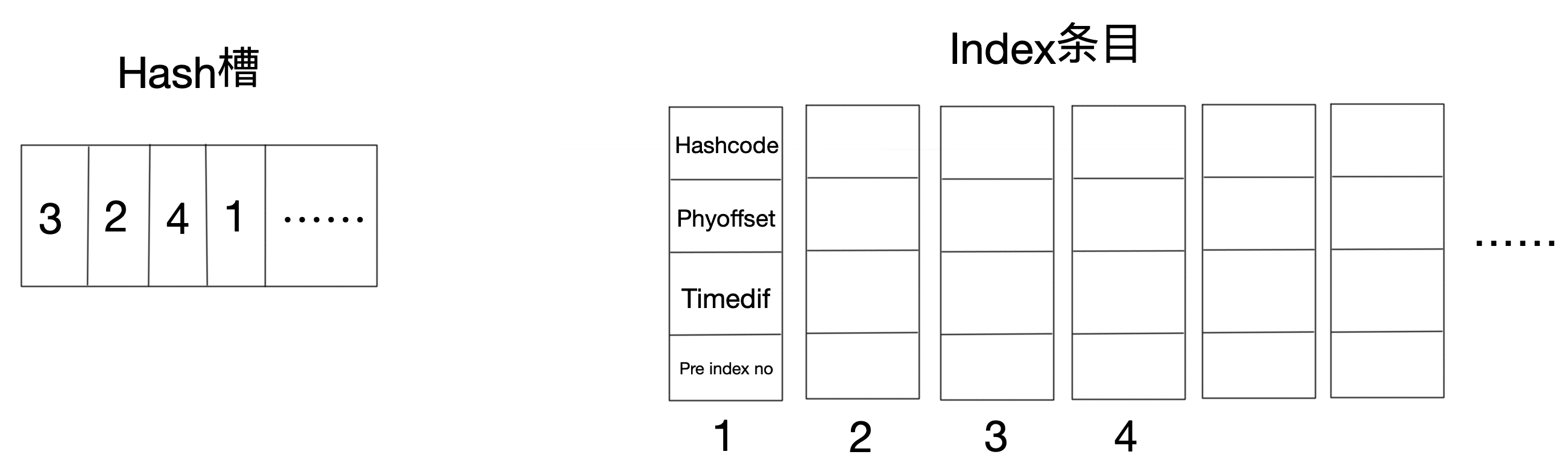
如果遇到Hash沖突,Index條目會通過pre index no構建鏈表結構:
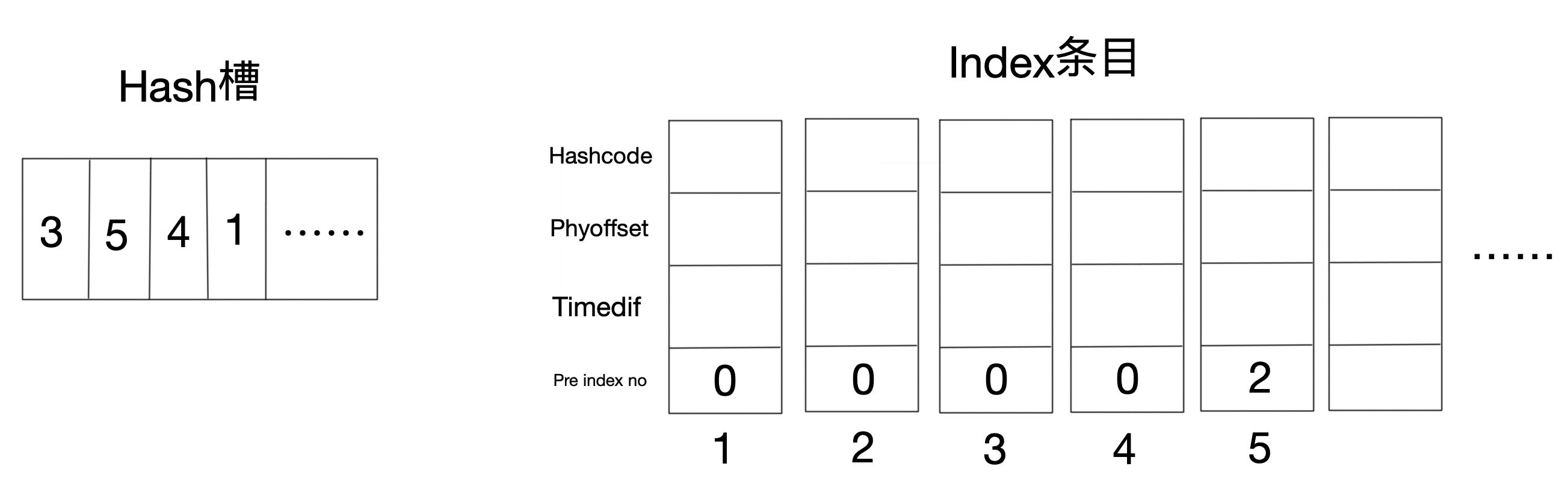
如圖第二個槽位沖突,第5條index條目的pre index no存儲原來的第二條序號。 其實就是HashMap的變形結構。
通過以上結構便可以用消息的key快速定位到消息內容。
如果說以上內容是RocketMQ通過優化數據結構的方式來提高分布式消息隊列的性能,那么這里便是通過操作系統底層來優化性能。
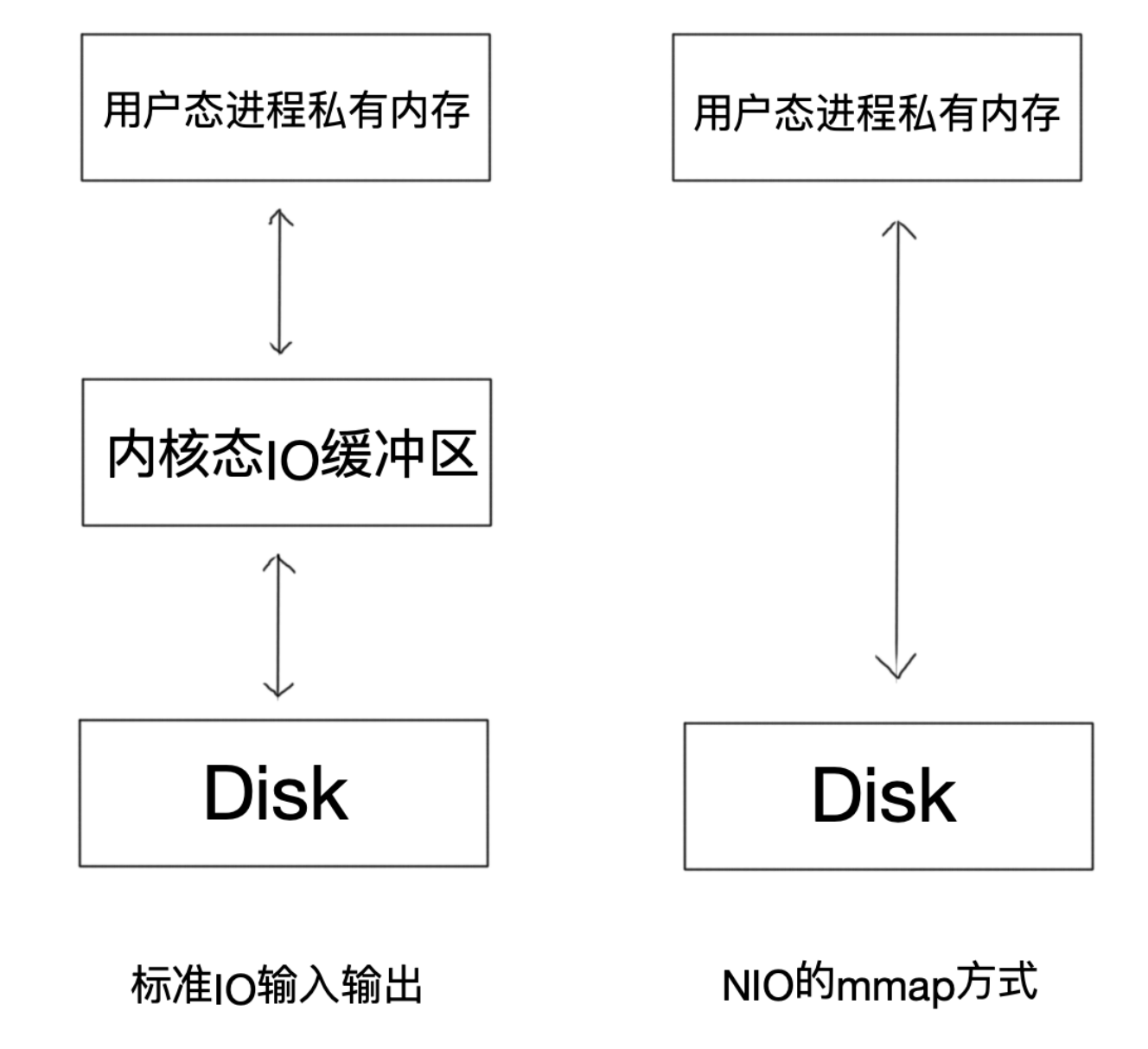
在Linux中,操作系統分為“用戶態”和“內核態”,普通的標準IO操作文件時,首先從磁盤將數據復制到內核態內存,接著從內核態內存復制到用戶態內存,完成讀取操作,然后從用戶態內存復制到網絡驅動的內核態內存,最后從網絡驅動的內核態內存復制到網卡中進行傳輸,完成寫出操作。
這個全過程中涉及到四次復制,可以說效率是可見的低。
于是,在RocketMQ中,通過Java中的MappedByteBuffer(mmap方式)實現“零拷貝”,省去了向用戶態的內存復制,提高了消息存儲和網絡發送的速度。
這里我們說一說什么是mmap內存映射技術。
mmap技術可以直接將用戶進程私有地址空間中的一塊區域與文件對象建立映射關系,這樣程序就好像可以直接從內存中完成對文件讀/寫操作一樣。當發生缺頁中斷時,直接將文件從磁盤拷貝至用戶態的進程空間內,只進行了一次數據拷貝。對于容量較大的文件來說(文件大小一般需要限制在1.5~2G以下),采用mmap的方式讀/寫效率和性能都非常高。如圖:
使用Mmap的限制:
a.Mmap映射的內存空間釋放的問題:由于映射的內存空間本身就不屬于JVM的堆內存區(Java Heap),因此其不受JVM GC的控制,卸載這部分內存空間需要通過系統調用 unmap()方法來實現。然而unmap()方法是FileChannelImpl類里實現的私有方法,無法直接顯示調用。RocketMQ中的做法是,通過Java反射的方式調用“sun.misc”包下的Cleaner類的clean()方法來釋放映射占用的內存空間;
b.MappedByteBuffer內存映射大小限制:因為其占用的是虛擬內存(非JVM的堆內存),大小不受JVM的-Xmx參數限制,但其大小也受到OS虛擬內存大小的限制。一般來說,一次只能映射1.5~2G 的文件至用戶態的虛擬內存空間,這也是為何RocketMQ默認設置單個CommitLog日志數據文件為1G的原因了;
c.使用MappedByteBuffe的其他問題:會存在內存占用率較高和文件關閉不確定性的問題;
1.簡單高效的數據結構,提高檢索速度;
2.磁盤的順序寫入,避免無序io競爭,提高消息存儲速度;
3.預分配機制,降低文件處理等待時間;
4.依賴pagecache機制,批量從磁盤讀取消息并加載到緩存,提高讀取速度;
5.內存映射機制,較少用戶態內核態之間的復制次數,提高處理效率。
看完上述內容,你們對如何從RocketMQ消息持久化設計看磁盤性能瓶頸的突破有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





