溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何利用邊緣監督信息加速Mask R-CNN實例分割訓練,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Mask R-CNN是實例分割的經典模型,作者通過在Mask R-CNN框架上附加一個新任務,達到更快的網絡收斂速度。
該文對MaskR-CNN添加了一個新的預測任務,稱為Edge Agreement Head(也許可以翻譯為“邊緣協定預測端”?),它的靈感來自人工實例標注的方式。當人們對實例進行像素級標注的時候,僅僅會關注實例的邊緣部分,而實例內部則只需要簡單的復制邊緣的標注信息就可以了。所以實例的mask邊緣非常有用,它們很好地表征了實例。Edge Agreement Head的作用即鼓勵深度網絡訓練時預測的實例mask邊緣與groundtruth的邊緣相似。
算法思想
作者通過觀察Mask R-CNN訓練前期輸出的預測圖像,發現很多時候邊緣都不在點上,很顯然,神經網絡在走彎路。
請看下面的例子:
這是Mask R-CNN深度網絡訓練前期的一些預測的Mask,發現它并沒有像人類一樣先把邊緣找出來,甚至缺失的很離譜(你可以預測的不很精細準確,但至少要表現出在向這個方向努力吧!)。
為了避免神經網絡走彎路,作者把實例的邊緣信息作為一種監督的指引,即將groundtruth進行邊緣濾波,讓神經網絡同時去預測實例的邊緣。指了條明路。
Mask R-CNN的多任務損失函數: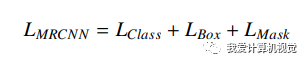
具體的做法是,增加一個新分支,預測邊緣并與groundtruth的邊緣相比較,請看下圖
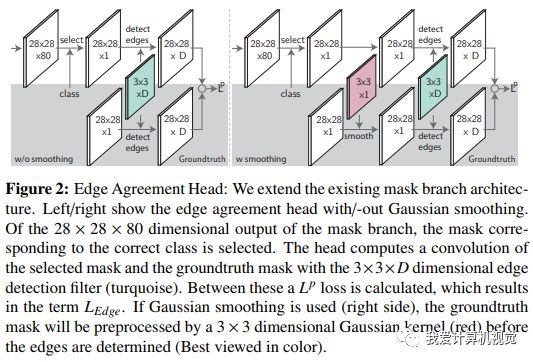
作者僅是對每個實例28*28大小區域內(所以增加的計算量有限)進行上述操作,通過添加簡單的3*3邊緣檢測計算預測和groundtruth的邊緣,因為邊緣檢測往往和圖像平滑一起用,所以右邊的圖增加了平滑的步驟。
上圖中Lp代表計算兩者差異的方式,如下: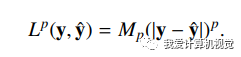
p代表像素差值的冪次方參數。
作者嘗試了普通的Sobel濾波和Laplacian濾波檢測邊緣。
作者通過Edge Agreement Head方式增加了一個損失函數,模型復雜度略微增加,沒添加任何額外的需要訓練的模型變量,訓練的計算成本增加很小,而網絡推斷時不增加計算量。
實驗結果
作者在MS COCO 2017數據集上做了實驗,比較訓練達到160k steps時基準模型和提出的模型的COCO AP metrics精度。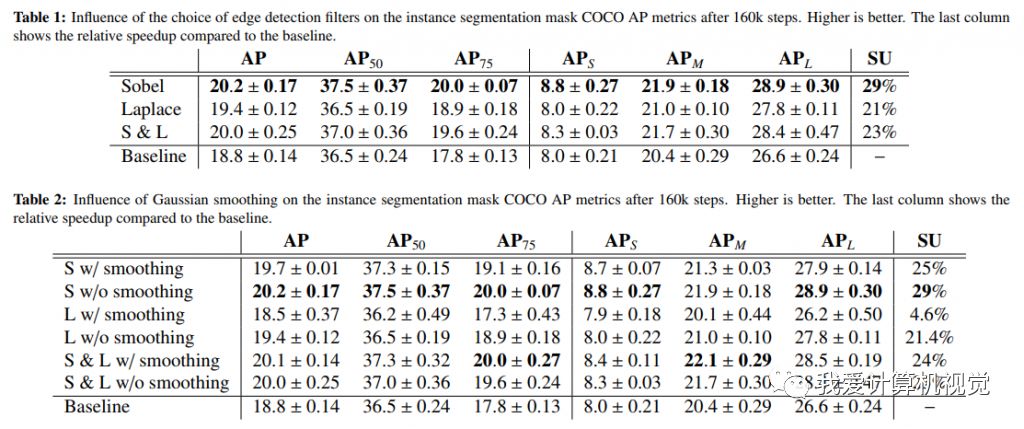
Table 1說明當訓練達到160k steps時,使用Edge Agreement Head的模型訓練達到了更高的精度,尤其是使用Soble邊緣算子的模型。
Table 2表明不使用圖像平滑加速更加明顯,達到更高的精度。
預測結果比較圖示:

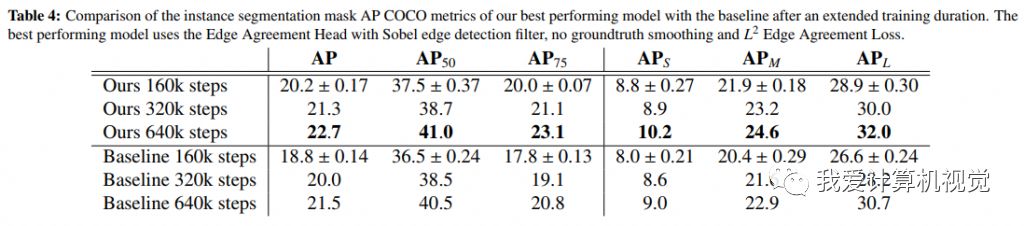
Table 4表明,拉長訓練時間,使用Edge Agreement Head仍然獲得了更高的精度。
以上就是如何利用邊緣監督信息加速Mask R-CNN實例分割訓練,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





