溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關TF-IDF如何提取文本特征詞,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
01
—
TF-IDF主要做什么?
文本分類中大都用到TF-IDF技術,比如扔給我們1篇新浪網推送的消息,讓機器判斷下屬于新聞類,還是財經類,還是體育類,還是娛樂類;再比如,今日頭條推送的1篇消息,如何提取出里面的關鍵詞匯,以此推薦給符合我們胃口的文章。
02
—
TF-IDF主要思想
TF-IDF的主要思想是:如果某個詞或短語在一篇文章中出現的頻率 TF 高,并且在其他文章中很少出現(IDF值大),則認為此詞或者短語具有很好的類別區分能力,適合用來分類。
03
—
TF-IDF全稱叫什么?
TF-IDF(term frequency–inverse document frequency)是一種用于信息檢索與數據挖掘的常用加權技術。TF意思是詞頻(Term Frequency),IDF意思是逆向文件頻率(Inverse Document Frequency)。
04
—
為什么叫逆向文件頻率?
TF-IDF中詞頻的描述TF,我們好理解,不就是一篇文章中一個詞在我們的語料庫中出現的次數嗎,但是逆向文件頻率,該怎么理解?
拿我們的母語來說,比如,“的”,“我們”,類似的這種詞語,大家覺得會對我們判斷這篇文章是體育類,還是娛樂類的文章作用大嗎?盡管它們的TF很大,但是實質對我們的分類沒有幫助,所以,此時自然要想到對TF加一個權重影響因子:IDF,逆向文件頻率,比如,一篇文章中如果出現了 “貝葉斯”這個詞語,那么,我們去語料庫,發現現有的1億個網頁中,有500個網頁,出現了這個貝葉斯分類,而“的”這個詞,有1億個都出現了,這個時候,我們希望“貝葉斯”比“的”IDF要大,即權重要大,IDF的計算公式最終的確實現了這個效果,這個在下文中我們可以看出來。
05
—
TF,IDF的數學公式
一篇網頁中的總詞語數是100個,而詞語“貝葉斯”出現了3次,那么“貝葉斯”一詞在該文件中的詞頻就是 3/100=0.03,
對應的數學公式:
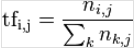
以上公式的字符含義,i是語料庫中第i個單詞,j是當前的這篇網頁的編號。
分析語料庫的1億個網頁時,發現有500個網頁含有“貝葉斯”,所以貝葉斯這個詞的IDF計算公式:
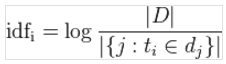
i依然是語料庫中的第i個詞(貝葉斯),D是語料庫中所有的網頁個數,分母的集合表示,貝葉斯出現在1億個網頁中的個數,如上所述為500個網頁。最后,再取對數,可以得出貝葉斯的IDF比“的”的IDF大。
06
—
Get together
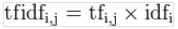
這個公式實現的效果:
某一特定文件內的高詞語頻率,以及該詞語在整個文件集合中的低文件頻率,可以產生出高權重的TF-IDF。
過濾掉常見的詞語,比如“的”,“我們”,“吃”。
最終:提取了一篇文章中重要的詞語。
上述就是小編為大家分享的TF-IDF如何提取文本特征詞了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





