溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何在Kubernetes中配置健康檢查,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
若您的應用程序是面向用戶的,那么確保持續可用性、盡力達到最短停機時間,是一項無比重要卻也不易的挑戰。因此,想要避免任何中斷,良好地監控應用程序的運行狀況,在此顯得至關重要。
Rancher 1.6中的健康檢查
Rancher 1.6中的編排引擎Cattle,具有為部署好的服務添加HTTP或TCP健康檢查的功能。Rancher自己的健康檢查微服務提供了健康檢查支持。你可以在這此了解更多信息:
https://rancher.com/docs/rancher/v1.6/en/cattle/health-checks/
簡單來說,Cattle用戶可以向服務添加TCP健康檢查。Rancher的健康檢查容器會在不同的主機上啟動,它們會測試TCP連接是否在服務容器的指定端口打開。請注意,對于最新版本(v1.6.20),健康檢查容器也與服務容器安排在同一主機上。
在部署服務時,也可以添加HTTP健康檢查。您可以要求Rancher在指定路徑上發出HTTP請求,并指定預期的響應。
這些健康檢查會定期完成,您可以自行配置檢查的間隔周期,重試/超時也是可配置的。如果健康檢查失敗,您還可以指示Rancher是否以及何時重新創建容器。
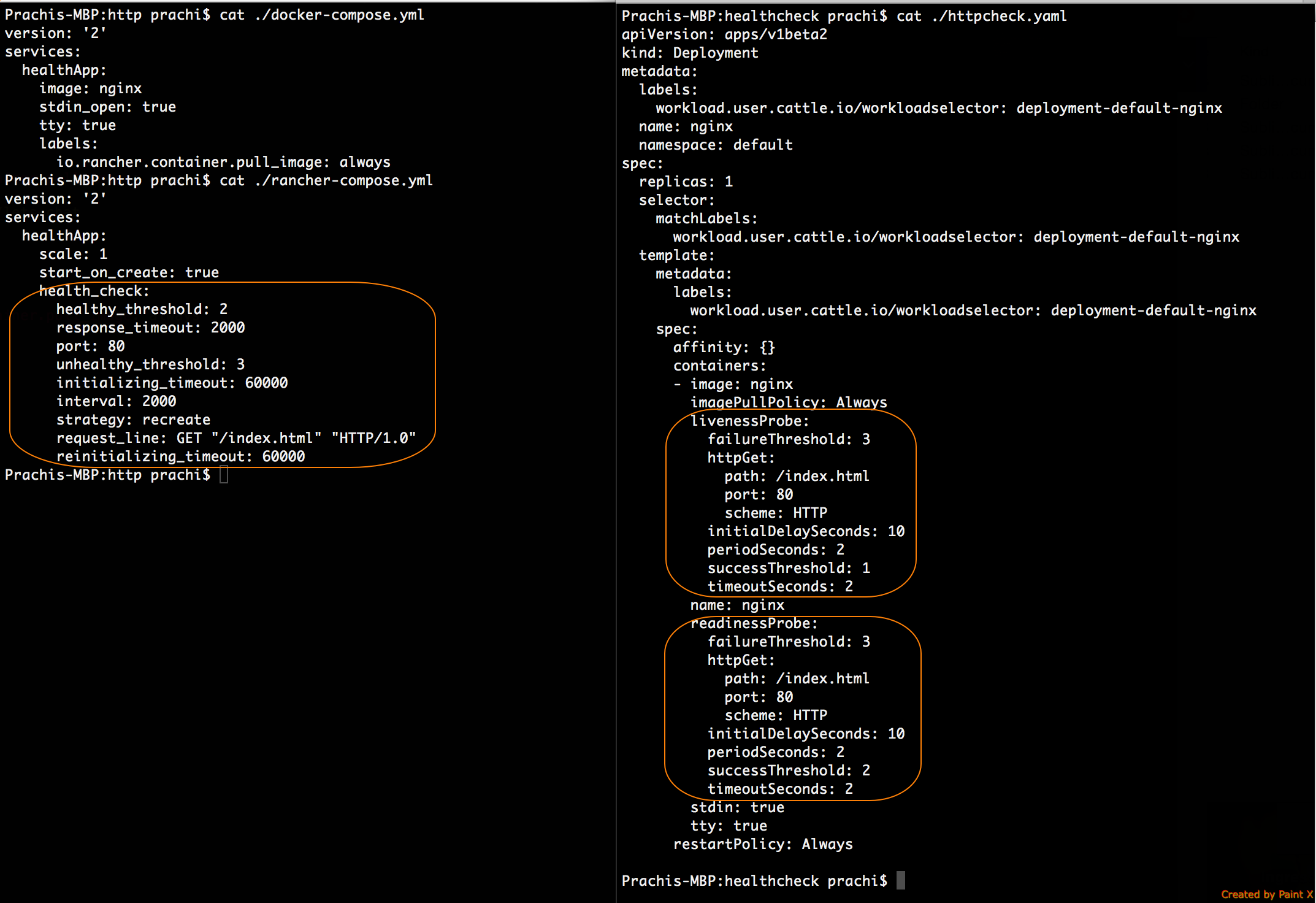
例如,在Cattle上運行Nginx鏡像的服務,并使用如下配置進行HTTP健康檢查:
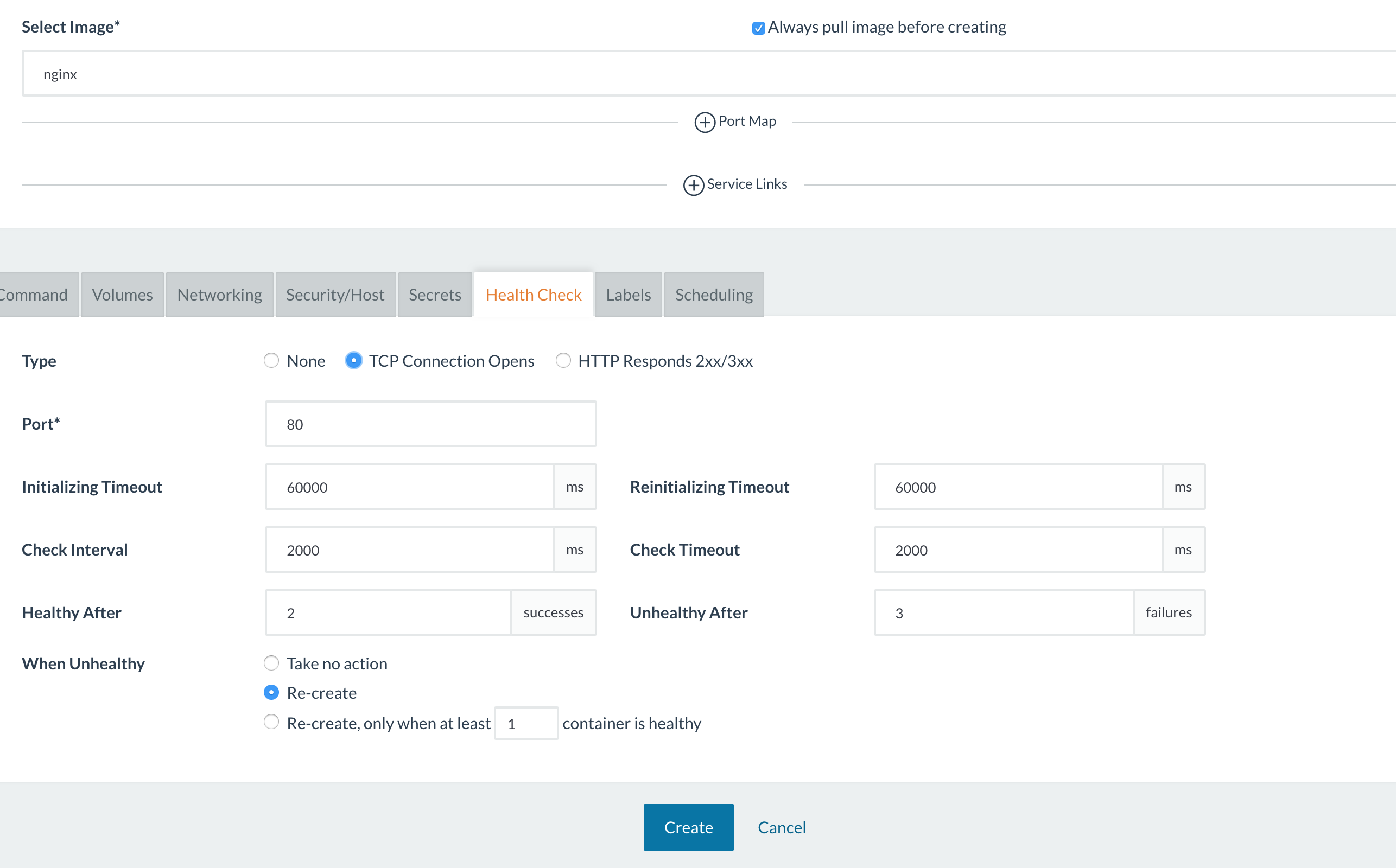
健康檢查的參數顯示在rancher-compose.yml文件中,而不是docker-compose.yml,因為健康檢查功能是由Rancher實現的。
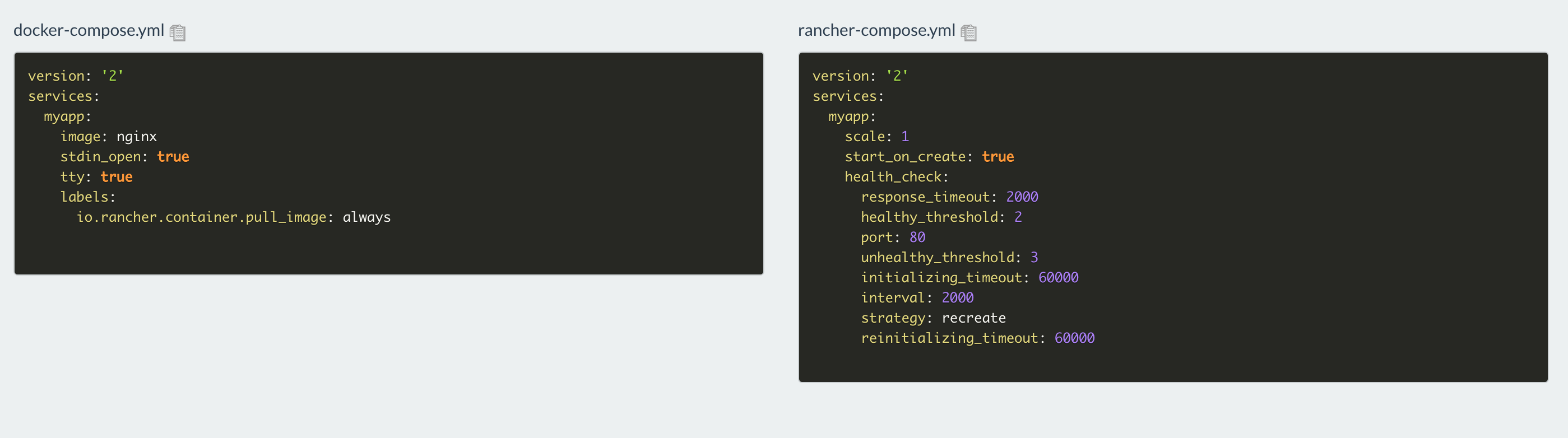
下面讓我們來看看我們是否可以在Rancher 2.0中配置相應的健康檢查。
Rancher 2.0中的健康檢查
在2.0中,Rancher使用的是原生的Kubernetes健康檢查機制:livenessProbe和readinessProbe。
參考此文檔的定義,探針(probe)是由Kubelet在容器上定期執行的診斷:鏈接。在Rancher 2.0中,與Rancher 1.6中的跨主機健康檢查相比,健康檢查由本地運行的Kubelet完成。
快速Kubernetes健康檢查摘要
livenessProbe
livenessProbe是對容器執行的操作,用于檢查容器是否正在運行。如果探針報告失敗,Kubernetes將終止pod容器,并根據規范中指定的重新啟動策略重新啟動它。
readinessProbe
readinessProbe用于檢查容器是否已準備好接受請求及滿足請求。當readinessProbe失敗時,則不會通過公共端點公開pod容器,因此容器不會接收到任何請求。
如果您的工作負載在處理請求之前忙于執行某些啟動例程,則最好為工作負載配置readinessProbe。
可以為Kubernetes工作負載配置以下類型的livenessProbe和readinessProbe:
tcpSocket – Kubelet會檢查是否可以針對指定端口上的容器IP地址打開TCP連接。
httpGet -在指定路徑上發出 HTTP / HTTPS GET請求,如果它返回200和400之間的HTTP響應代碼,則報告為成功。
exec - Kubelet在容器內執行指定的命令,并檢查命令是否以狀態0退出。
您可在此查看上述探針的更多配置詳細信息:
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/#configure-probes
在Rancher 2.0中配置健康檢查
通過Rancher UI,用戶可以向Kubernetes工作負載添加TCP或HTTP健康檢查。默認情況下,Rancher會要求您為工作負載配置readinessProbe,并使用相同的配置應用livenessProbe。您也可以選擇定義單獨的livenessProbe。
如果健康檢查失敗,則容器會根據工作負載規范中定義的restartPolicy重新啟動。這相當于以前的rancher-compose.yml文件中的strategy參數,那時這一參數是用于使用Cattle中的健康檢查的1.6服務的。
TCP健康檢查
在Rancher 2.0中部署工作負載時,用戶可以配置TCP健康檢查,以檢查是否可以在特定端口打開TCP連接。
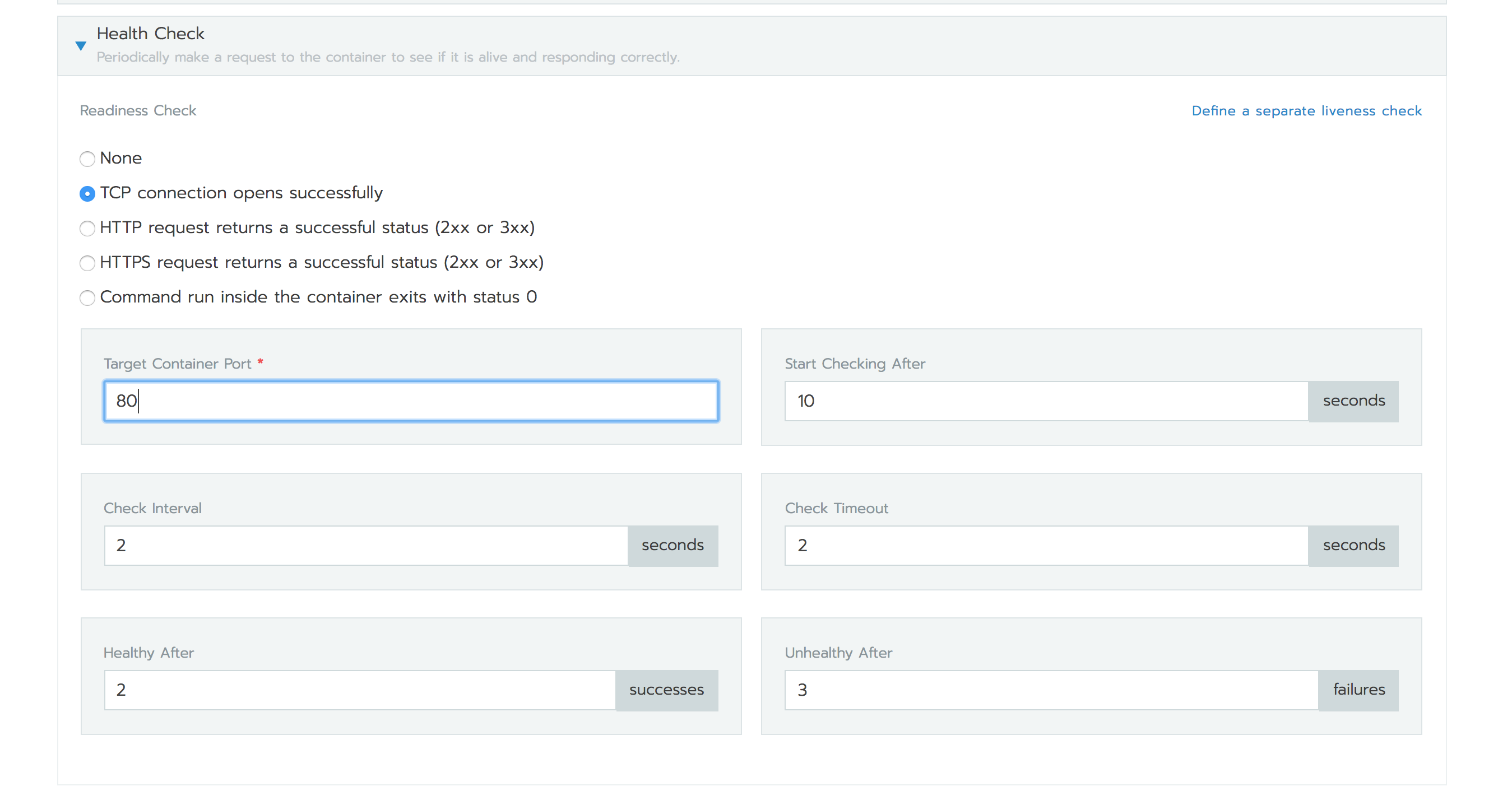
以下是Kubernetes YAML規范,也就是為上文說的Nginx工作負載所配置的TCP readinessProbe。Rancher還使用相同的配置為您的工作負載添加了livenessProbe。
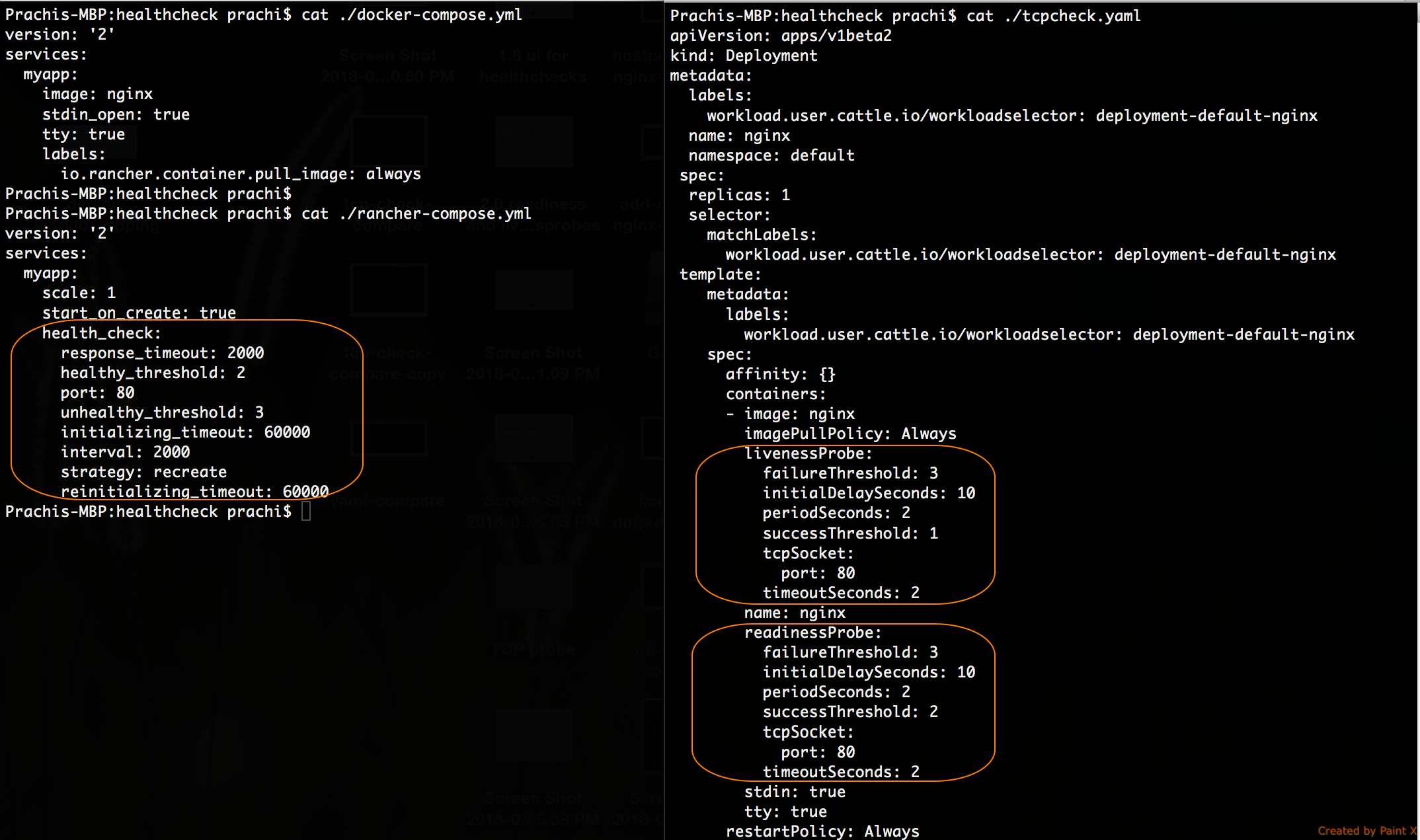
從1.6到2.0,健康檢查參數的變化:
port 變成 tcpSocket.port
response_timeout 變成
timeoutSeconds
healthy_threshold 變成 failureThreshold
unhealthy_threshold 變成
successThreshold
interval 變成 periodSeconds
initializing_timeout 變成
initialDelaySeconds
strategy 變成 restartPolicy
HTTP健康檢查
您還可以指定HTTP健康檢查,并在pod容器中提供Kubelet將發出HTTP / HTTPS GET請求的路徑。但是,不同于Rancher 1.6中支持任何HTTP方法,Kubernetes僅支持HTTP / HTTPS GET請求。
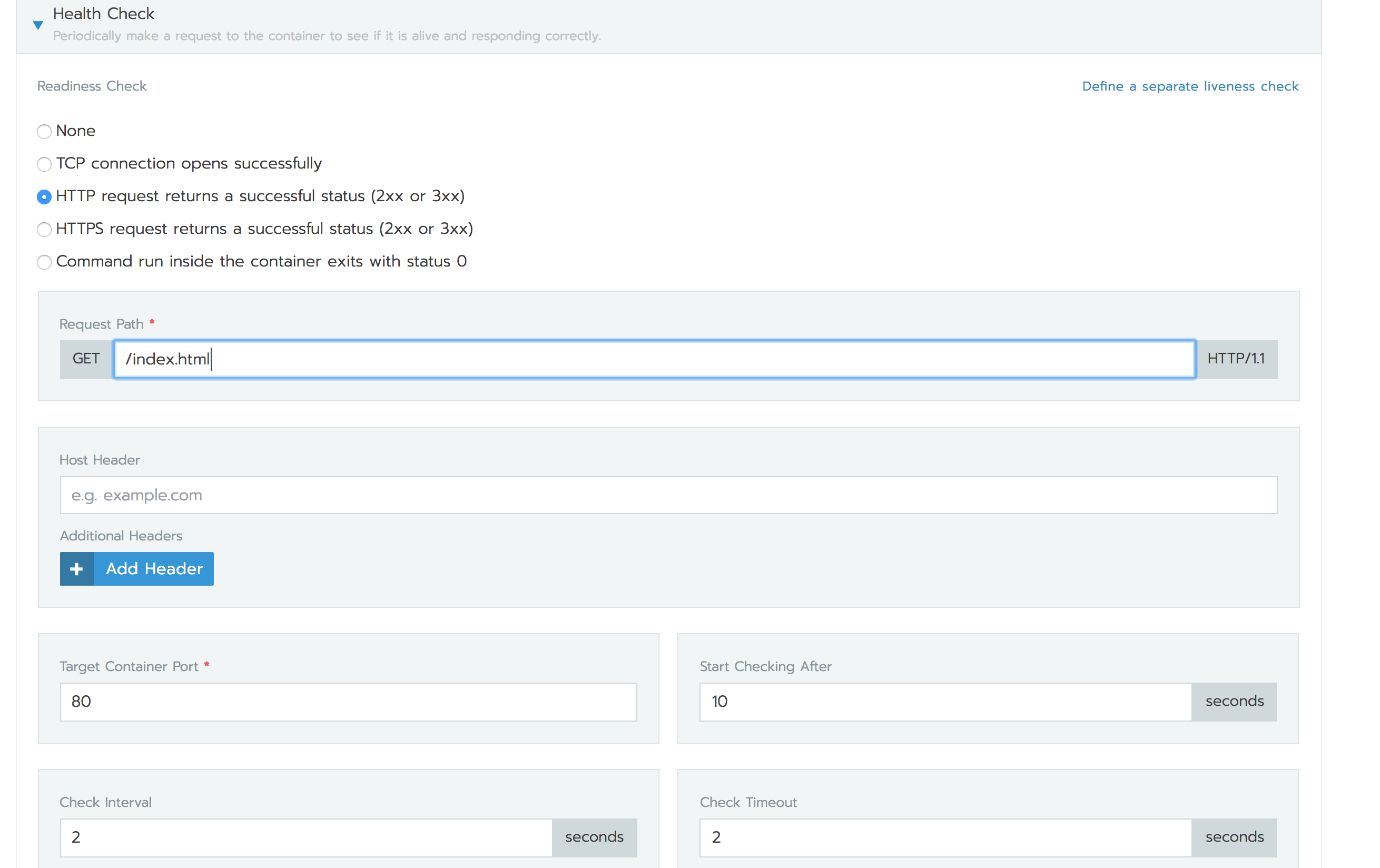
下面是Kubernetes YAML規范,顯示了為上文所說的Nginx工作負載配置的HTTP readinessProbe和livenessProbe。
健康檢查在行動
現在讓我們看看當Kubernetes中的健康檢查失敗時會發生什么,以及工作負載如何恢復。
假定在我們的Nginx工作負載上執行上述HTTP健康檢查,在/index.html路徑上執行HTTP GET。為了刻意使健康檢查失敗,我使用Rancher中的Execute Shell UI選項在pod容器中執行了一個exec。
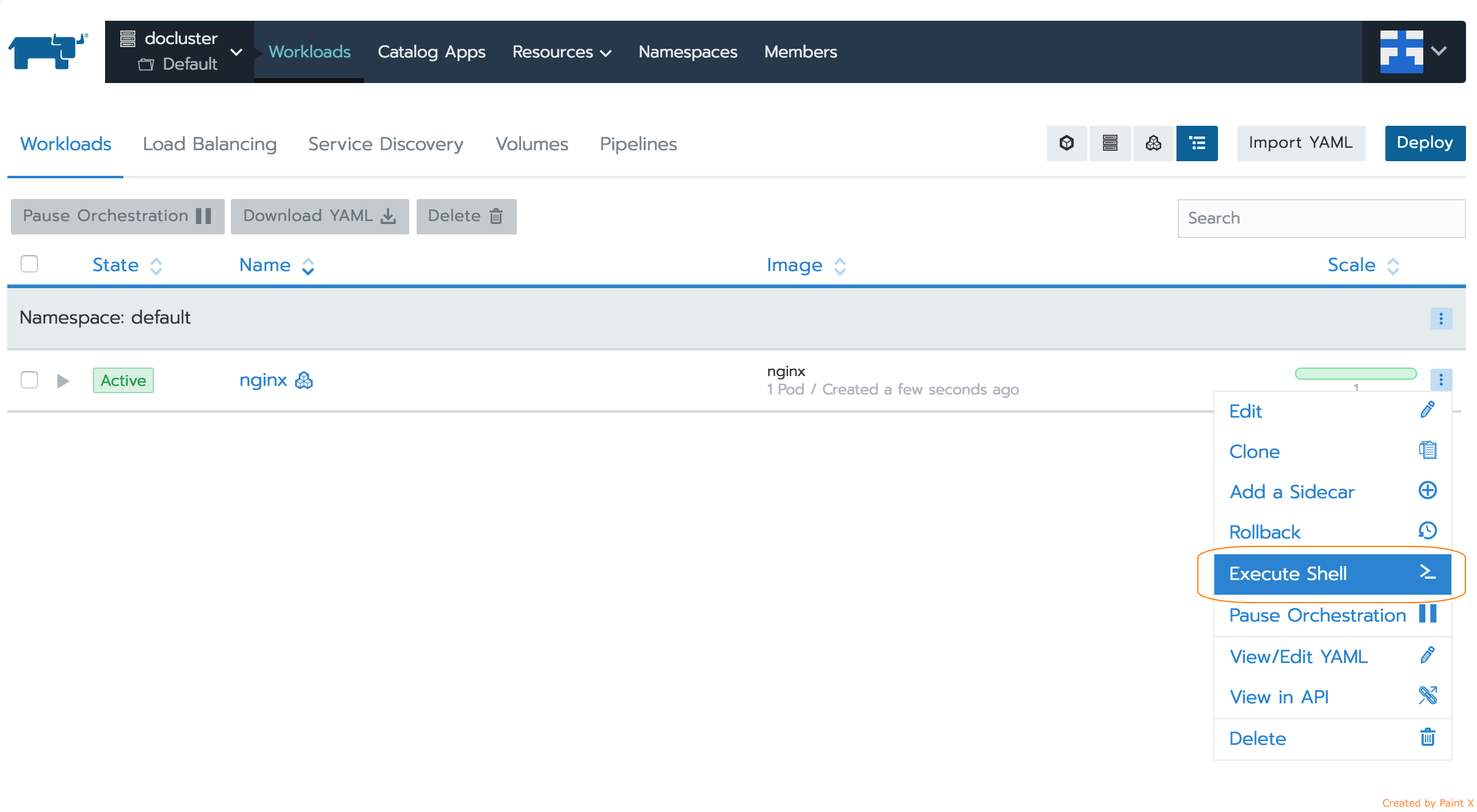
exec容器后,我移動了健康檢查執行GET的文件。

readinessProbe和livenessProbe檢查失敗,并且工作負載狀態已變為“不可用”。
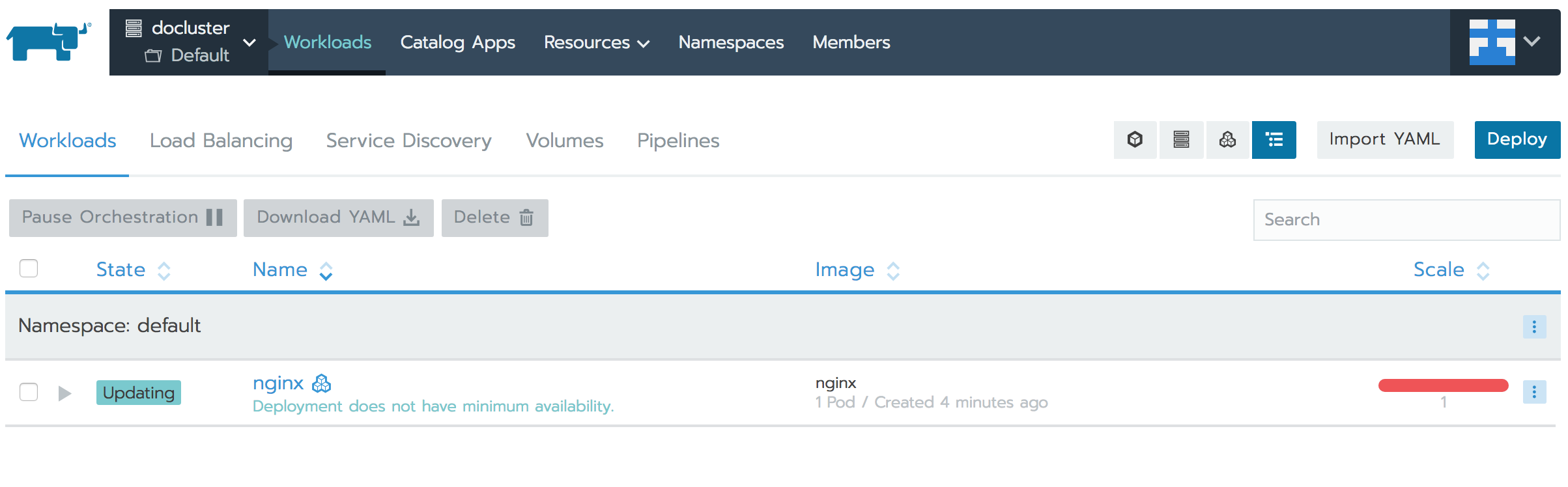
Kubernetes很快就殺死了原pod并重新創建了pod,并且由于restartPolicy設置為了Always,工作負載很快恢復了。
使用Kubectl,您可以看到這些健康檢查事件日志:
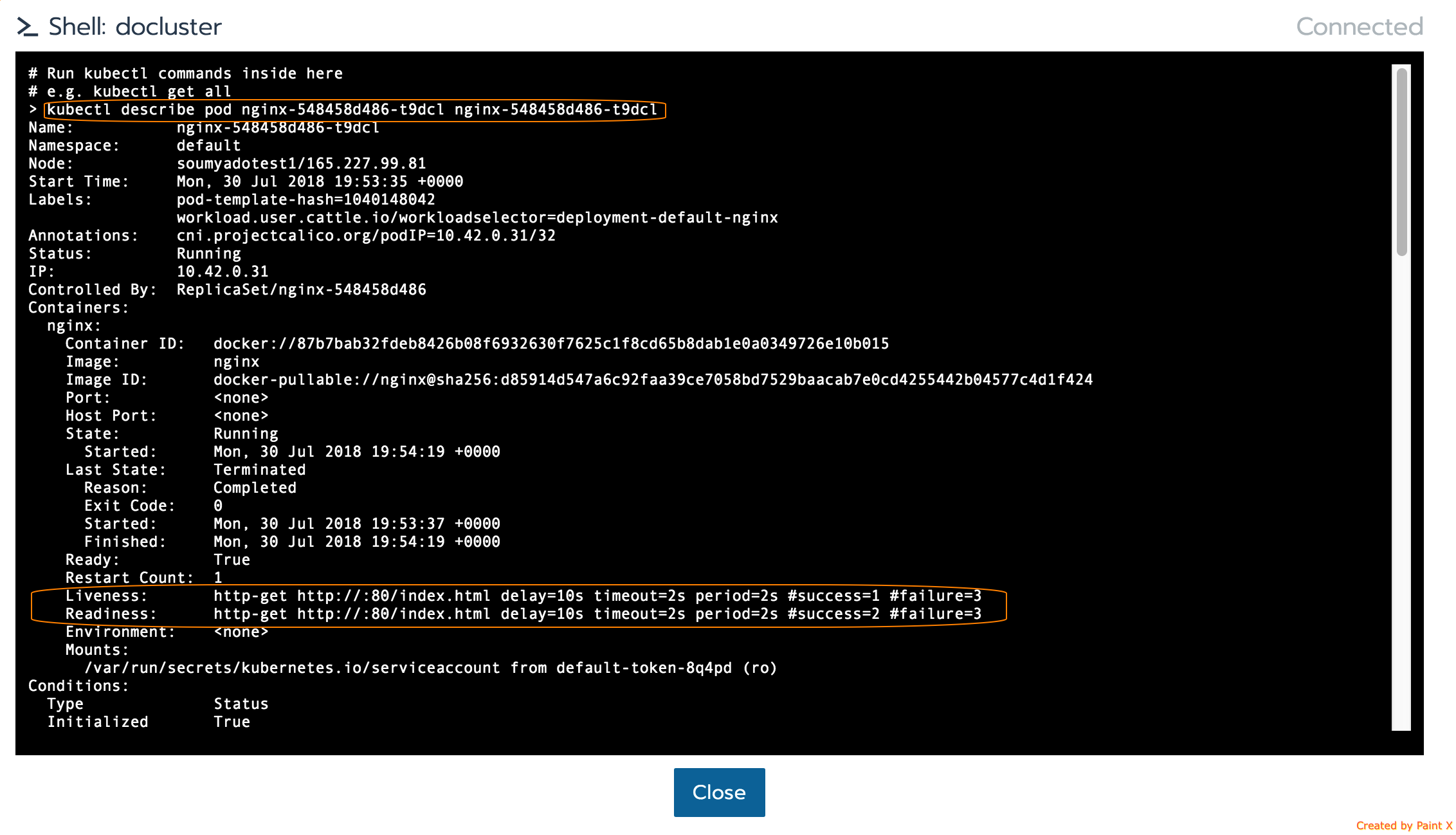
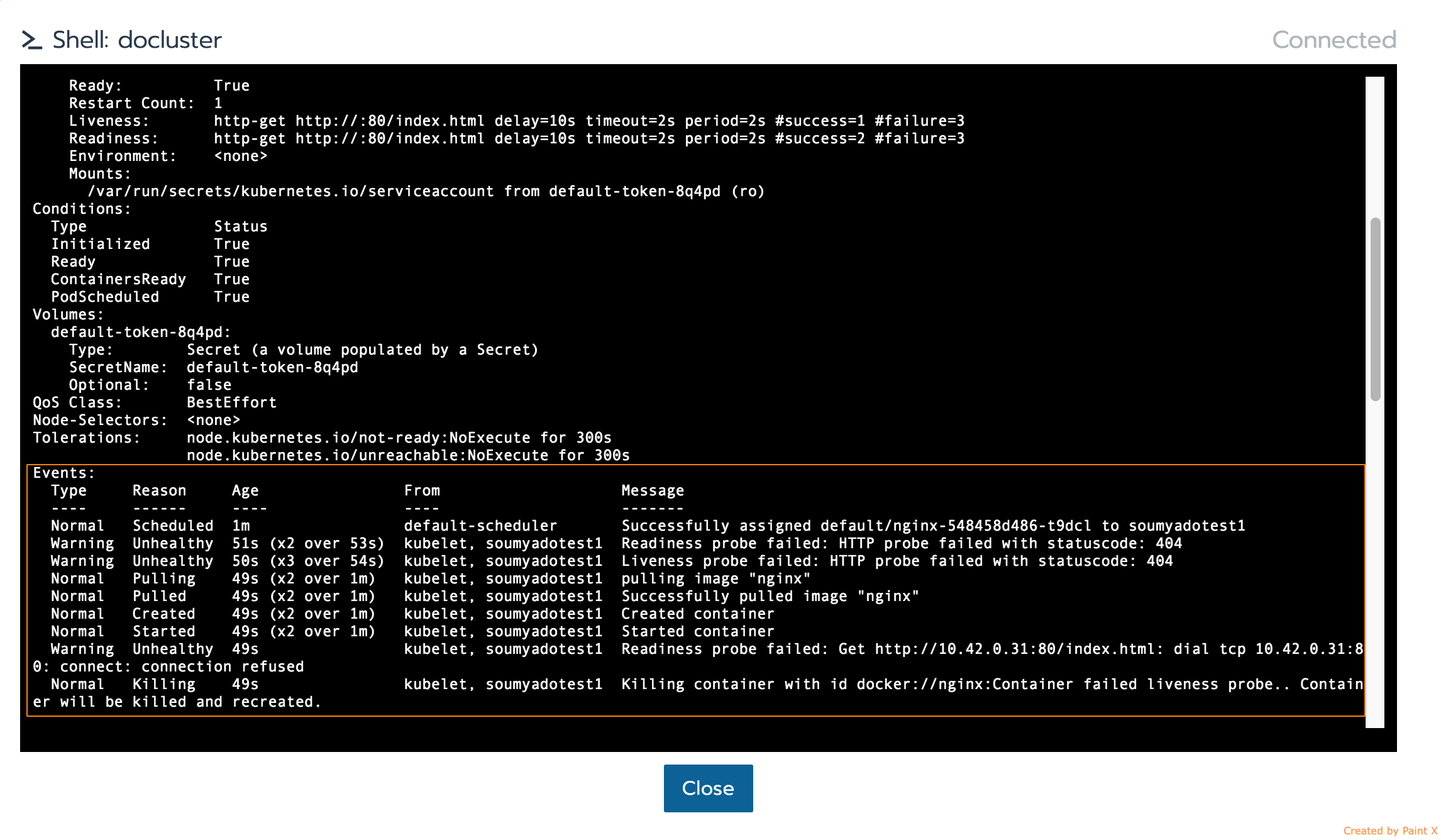
小提示:Rancher 2.0 UI提供了從Kubernetes Cluster視圖啟動Kubectl的功能,您可以在該視圖中在集群對象上運行原生的Kubernetes命令。
將健康檢查從Docker Compose遷移到Kubernetes Yaml?
Rancher 1.6通過自己的微服務提供了健康檢查,這就是為什么Cattle用戶添加到服務中的健康檢查參數會出現在rancher-compose.yml文件而不是docker-compose.yml配置文件中。
我們之前在文章《如何簡潔優雅地實現Kubernetes服務暴露》中使用的Kompose工具適用于標準的docker-compose.yml參數,因此無法解析Rancher健康檢查構造。目前,我們暫時無法使用此工具將Rancher 健康檢查從compose配置轉換為Kubernetes Yaml。
可用于在Rancher 2.0中添加TCP或HTTP健康檢查的配置參數與Rancher 1.6非常相似。Cattle服務使用的健康檢查配置可以完全轉換為2.0而不會丟失任何功能。
上述內容就是如何在Kubernetes中配置健康檢查,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





