溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
YOLOv2檢測過程的Tensorflow實現是怎樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
一、全部代碼解讀如下:
1、model_darknet19.py:yolo2網絡模型——darknet19。
YOLOv2采用了一個新的基礎模型(特征提取器),稱為Darknet-19,包括19個卷積層和5個maxpooling層,如下圖。Darknet-19與VGG16模型設計原則是一致的,主要采用3*3卷積,采用2*2的maxpooling層之后,特征圖維度降低2倍,而同時將特征圖的channles增加兩倍。
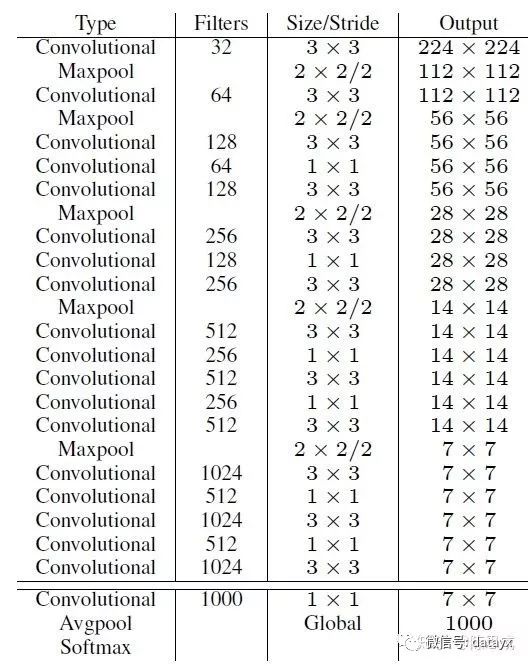
主要特點有:
(1)去掉了全連接層fc
·這樣大大減少了網絡的參數,個人理解這是yolo2可以增加每個cell產生邊界框以及每個邊界框能夠單獨的對應一組類別概率的原因。
·并且,網絡下采樣是32倍,這樣也使得網絡可以接收任意尺寸的圖片,所以yolo2有了Multi-Scale Training多尺度訓練的改進:輸入圖片resize到不同的尺寸(論文中選用320,352...,608十個尺寸,下采樣32倍對應10*10~19*19的特征圖)。每訓練10個epoch,將圖片resize到另一個不同的尺寸再訓練。這樣一個模型可以適應不同的輸入圖片尺寸,輸入圖像大(608*608)精度高速度稍慢、輸入圖片小(320*320)精度稍低速度快,增加了模型對不同尺寸圖片輸入的魯棒性。
(2)在每個卷積層后面都加入一個BN層并不再使用droput
·這樣提升模型收斂速度,而且可以起到一定正則化效果,降低模型的過擬合。
(3)采用跨層連接Fine-Grained Features
·YOLOv2的輸入圖片大小為416*416,經過5次maxpooling(下采樣32倍)之后得到13*13大小的特征圖,并以此特征圖采用卷積做預測。這樣會導致小的目標物體經過5層maxpooling之后特征基本沒有了。所以yolo2引入passthrough層:前面的特征圖維度是后面的特征圖的2倍,passthrough層抽取前面層的每個2*2的局部區域,然后將其轉化為channel維度,對于26*26*512的特征圖,經passthrough層處理之后就變成了13*13*2048的新特征圖,這樣就可以與后面的13*13*1024特征圖連接在一起形成13*13*3072大小的特征圖,然后在此特征圖基礎上卷積做預測。作者在后期的實現中借鑒了ResNet網絡,不是直接對高分辨特征圖處理,而是增加了一個中間卷積層,先采用64個1*1卷積核進行卷積,然后再進行passthrough處理,這樣26*26*512的特征圖得到13*13*256的特征圖。這算是實現上的一個小細節。
2、decode.py:解碼darknet19網絡得到的參數.

3、utils.py:功能函數,包含:預處理輸入圖片、篩選邊界框NMS、繪制篩選后的邊界框。
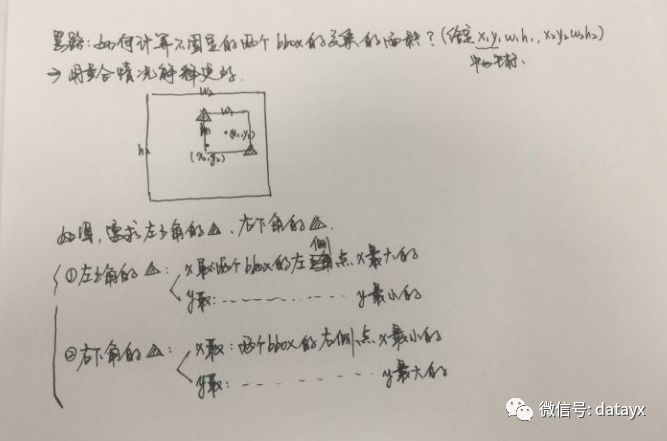
這里著重介紹NMS中IOU計算方式:yolo2中計算IOU只考慮形狀,先將anchor與ground truth的中心點都偏移到同一位置(cell左上角),然后計算出對應的IOU值。
IOU計算難點在于計算交集大小:首先要判斷是否有交集,然后再計算IOU。計算時候有一個trick,只計算交集部分的左上角和右下角坐標即可,通過取max和min計算:
4、Main.py:YOLO_v2主函數
對應程序有三個步驟:
(1)輸入圖片進入darknet19網絡得到特征圖,并進行解碼得到:xmin xmax表示的邊界框、置信度、類別概率
(2)篩選解碼后的回歸邊界框——NMS
(3)繪制篩選后的邊界框
Python3 + Tensorflow1.5 + OpenCV-python3.3.1 + Numpy1.13
windows和ubuntu環境都可以
請在yolo2檢測模型下載模型,并放到yolo2_model文件夾下
https://pan.baidu.com/s/1ZeT5HerjQxyUZ_L9d3X52w
1、model_darknet19.py:yolo2網絡模型——darknet19
2、decode.py:解碼darknet19網絡得到的參數
3、utils.py:功能函數,包含:預處理輸入圖片、篩選邊界框NMS、繪制篩選后的邊界框
4、config.py:配置文件,包含anchor尺寸、coco數據集的80個classes類別名稱
5、Main.py:YOLO_v2主函數,對應程序有三個步驟:
(1)輸入圖片進入darknet19網絡得到特征圖,并進行解碼得到:xmin xmax表示的邊界框、置信度、類別概率
(2)篩選解碼后的回歸邊界框——NMS
(3)繪制篩選后的邊界框
6、Loss.py:Yolo_v2 Loss損失函數(train時候用,預測時候沒有調用此程序)
(1)IOU值最大的那個anchor與ground truth匹配,對應的預測框用來預測這個ground truth:計算xywh、置信度c(目標值為1)、類別概率p誤差。
(2)IOU小于某閾值的anchor對應的預測框:只計算置信度c(目標值為0)誤差。
(3)剩下IOU大于某閾值但不是max的anchor對應的預測框:丟棄,不計算任何誤差。
7、yolo2_data文件夾:包含待檢測輸入圖片car.jpg、檢測后的輸出圖片detection.jpg、coco數據集80個類別名稱coco_classes.txt
1、car.jpg:輸入的待檢測圖片

2、detected.jpg:檢測結果可視化

可以看到,跟yolo1對比,yolo2引入anchor后檢測精度有了提升(car和person的類別置信度高了許多),并且每個邊界框對應一組類別概率解決了yolo1中多個目標中心點落在同一個cell只能檢測一個物體的問題(左側兩個person都檢測出來了)。相比yolo1還是有一定提升的。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





