溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、初識Flink
? 官網:https://flink.apache.org/
Apache Flink是一款分布式、高性能、高可用、高精確的為數據流應用而生的開源流式處理框架。在 2014 被 Apache 孵化器所接受,然后迅速地成為了 ASF(Apache Software Foundation)的頂級項目之一。
Flink核心是用Java和Scala編寫的一個流式的數據流執行引擎,其針對數據流的分布式計算提供了數據分布、數據通信以及容錯機制等功能。
可對無限數據流(實時流)和有限數據流(批處理)和進行有狀態計算。可部署在各種集群環境,對各種大小的數據規模進行快速計算。
Flink原生支持了迭代計算、內存管理和程序優化。
二、Flink基本架構介紹

具體組件:
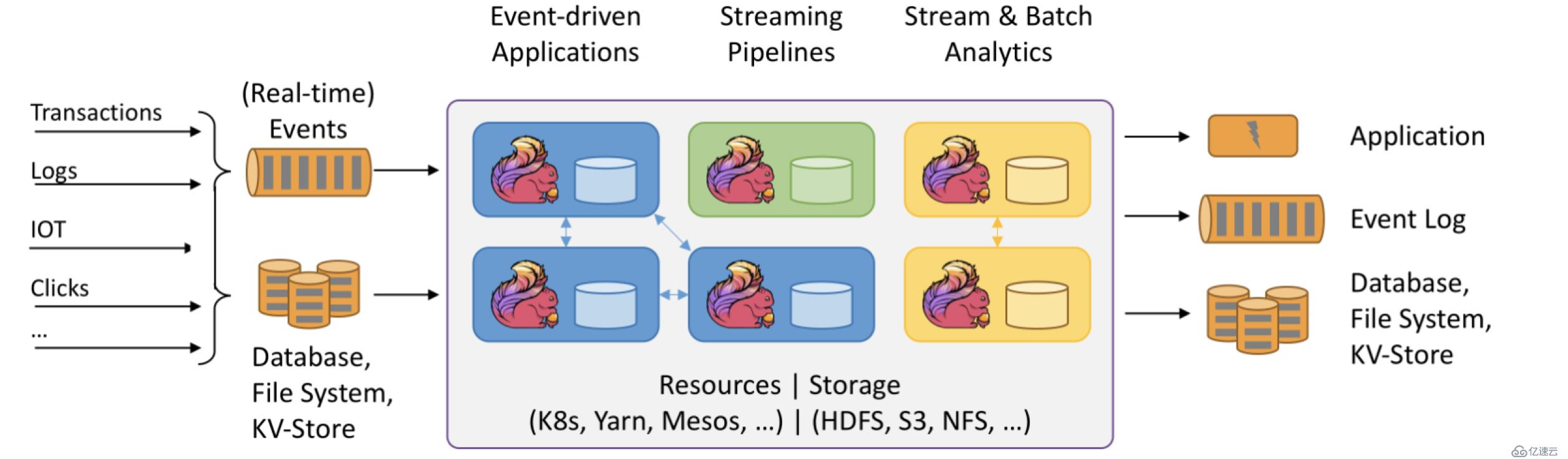
上圖大致可以分為三塊內容:左邊為數據輸入、右邊為數據輸出、中間為Flink數據處理。
Flink支持消息隊列的Events(支持實時的事件)的輸入,上游源源不斷產生數據放入消息隊列,Flink不斷消費、處理消息隊列中的數據,處理完成之后數據寫入下游系統,這個過程是不斷持續的進行。
數據源:
1.Transactions:即交易數據。比如各種電商平臺用戶下單,這個數據源源不斷寫入消息隊列
2.Logs:比如web應用運行過程中產生的錯誤日志信息,源源不斷發送到消息隊列中,后續Flink處理為運維部門提供監控依據。
3.IOT:即物聯網,英文全稱為Internet of things。物聯網的終端設備,比如華為手環、小米手環,源源不斷的產生數據寫入消息隊列,后續Flink處理提供健康報告
4.Clicks:即點擊流,比如打開淘寶網站,淘寶網站頁面上埋有很多數據采集點或者探針,當用戶點擊淘寶頁面的時候,它會采集用戶點擊行為的詳細信息,這些用戶的點擊行為產生的數據流我們稱為點擊流。
數據輸入系統:
Flink既支持實時(Real-time)流處理,又支持批處理。實時流消息系統,比如Kafka。批處理系統有很多,DataBase(比如傳統MySQL、Oracle數據庫),KV-Store(比如HBase、MongoDB數據庫),File System(比如本地文件系統、分布式文件系統HDFS)。
Flink數據處理:
Flink在數據處理過程中,資源管理調度可以使用K8s(Kubernetes 簡稱K8s,是Google開源的一個容器編排引擎)、YARN、Mesos,中間數據存儲可以使用HDFS、S3、NFS等
數據輸出:
Flink可以將處理后的數據輸出下游的應用(Application),也可以將處理過后的數據寫入消息隊列(比如Kafka),還可以將處理后的輸入寫入Database、File System和KV-Store。
三、Flink核心組件棧
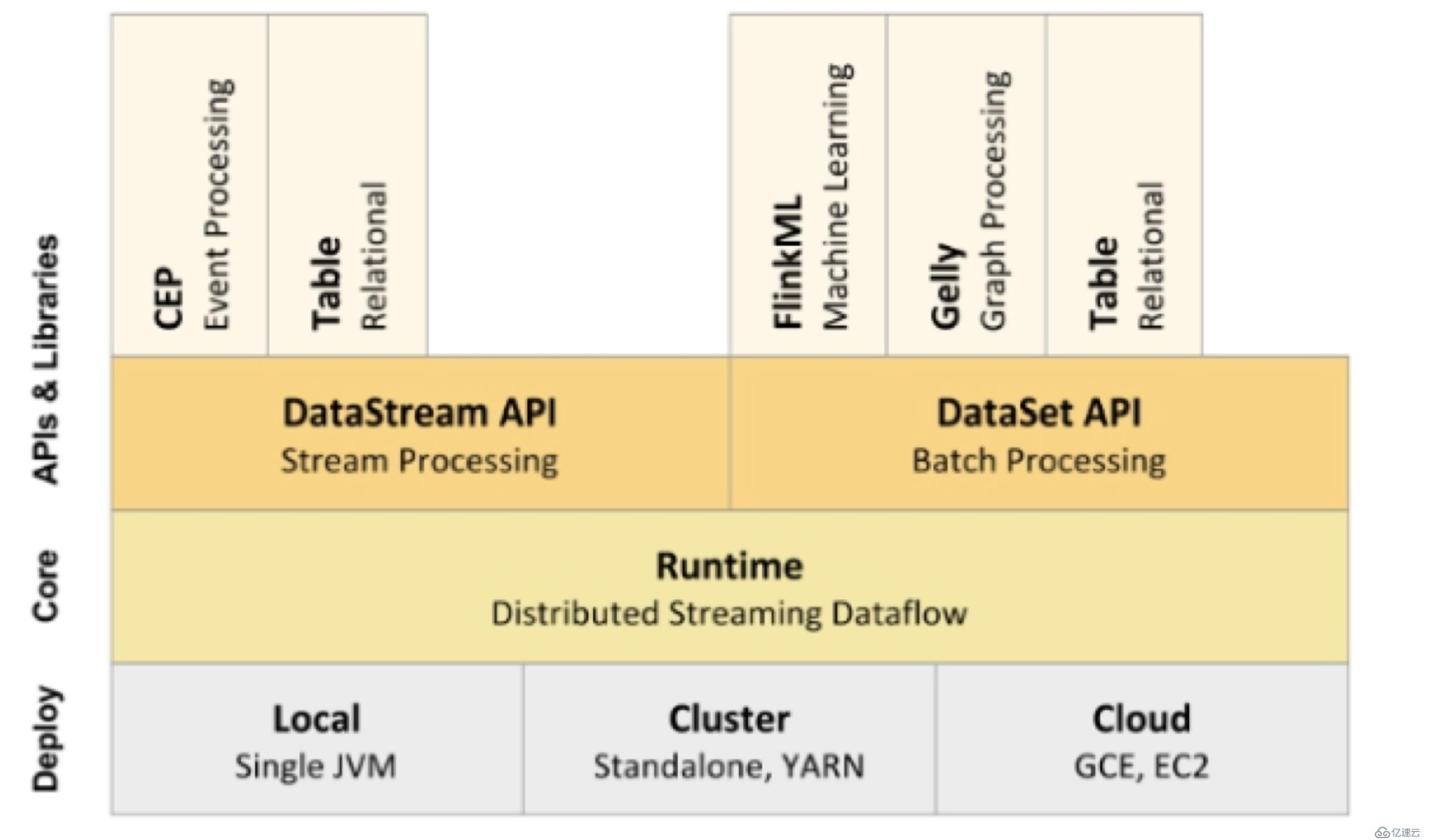
從上圖可以看出Flink的底層是Deploy,Flink可以Local模式運行,啟動單個 JVM。Flink也可以Standalone 集群模式運行,同時也支持Flink ON YARN,Flink應用直接提交到YARN上面運行。另外Flink還可以運行在GCE(谷歌云服務)和EC2(亞馬遜云服務)。
Deploy的上層是Flink的核心(Core)部分Runtime。在Runtime之上提供了兩套核心的API,DataStream API(流處理)和DataSet API(批處理)。在核心API之上又擴展了一些高階的庫和API,比如CEP流處理,Table API和SQL,Flink ML機器學習庫,Gelly圖計算。SQL既可以跑在DataStream API,又可以跑在DataSet API。
四、Flink的前世今生
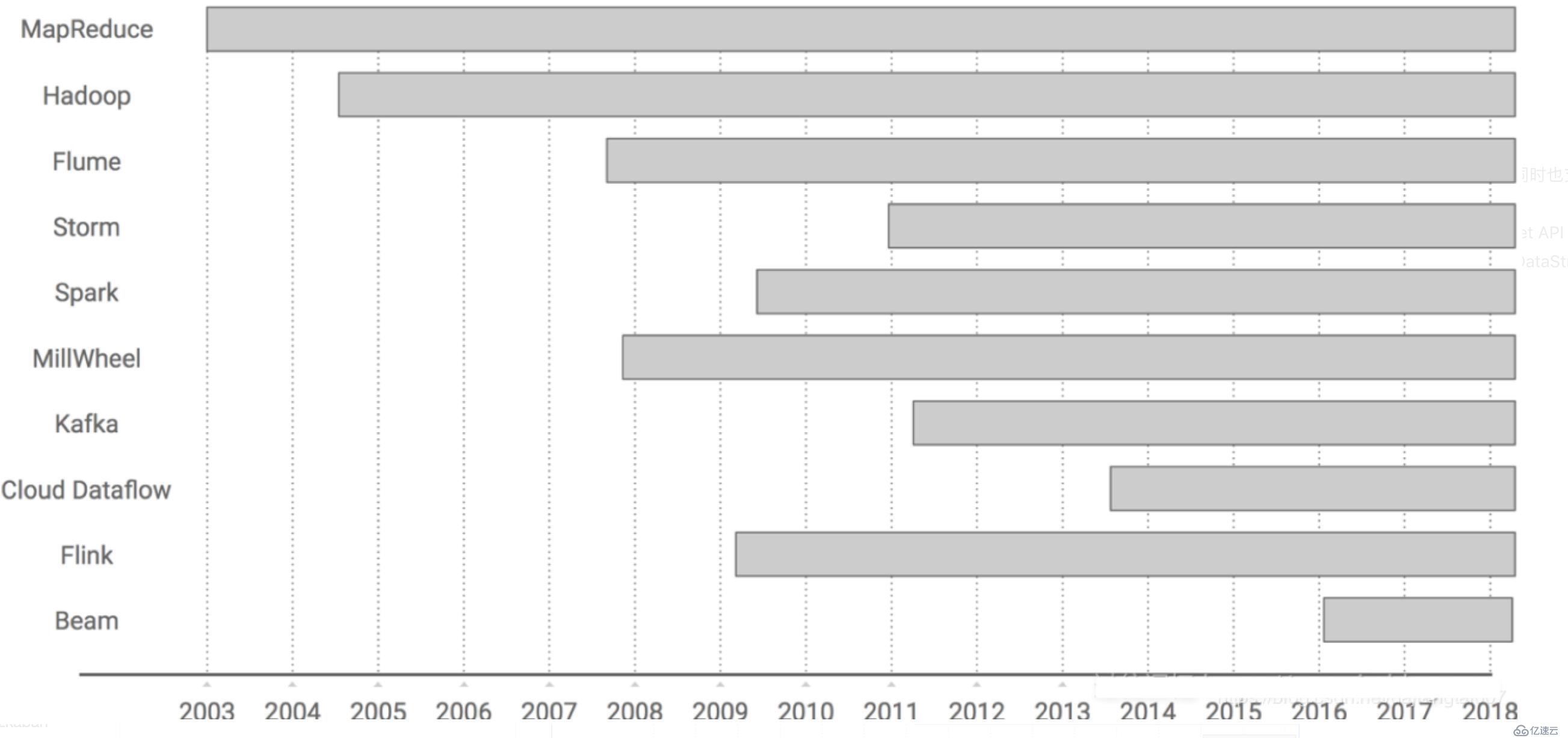
Flink在發展過程的關鍵時刻:
誕生于2009年,原來叫StratoSphere,是柏林工業大學的一個研究性項目,早期專注于批計算。
2014年孵化出Flink項目并捐給了Apache。
2015年開始引起大家注意,出現在大數據舞臺。
2016年在阿里得到大規模應用。
五、為什么是Flink?
大數據生態圈很龐大,優秀的框架和組件,為何Flink如此受寵?
1. 從技術角度來說,目前大數據計算引擎中, 能夠同時支持流處理和批處理的計算引擎,只有Spark和Flink(Storm只支持流處理)。其中Spark的技術理念是基于微批處理來模擬流的計算。而Flink則完全相反,它采用的是基于流計算來模擬批計算。從技術發展方向看,用批來模擬流有一定的技術局限性,并且這個局限性可能很難突破。而Flink基于流來模擬批,在技術上有更好的擴展性。
2. 從語言方面來說,提供友好且優雅流暢的java和scala api和支持,java用戶眾多也是一個重要原因。
3. 大公司的風向標作用, 阿里全面轉向Flink無疑是一個催化劑。目前,阿里巴巴所有的業務,包括阿里巴巴所有子公司都采用了基于Flink搭建的實時計算平臺。
阿里巴巴計算平臺事業部資深技術專家莫問在云棲大會的演講內容 —— 阿里巴巴為什么選擇Apache Flink?這個框架的性能表現確實很優秀, Flink最初上線阿里巴巴只有數百臺服務器,目前規模已達上萬臺,此等規模在全球范圍內也是屈指可數;基于Flink,阿里內部積累起來的狀態數據已經是PB級別規模;如今每天在阿里Flink的計算平臺上,處理的數據已經超過萬億條;在峰值期間可以承擔每秒超過4.72億次的訪問,最典型的應用場景是阿里巴巴雙11大屏。
其實不光阿里,國內很多一線的公司都投入很多人力和財力在Flink實時計算上。

六、流式計算的代表:Flink、Spark Streaming、Storm對比
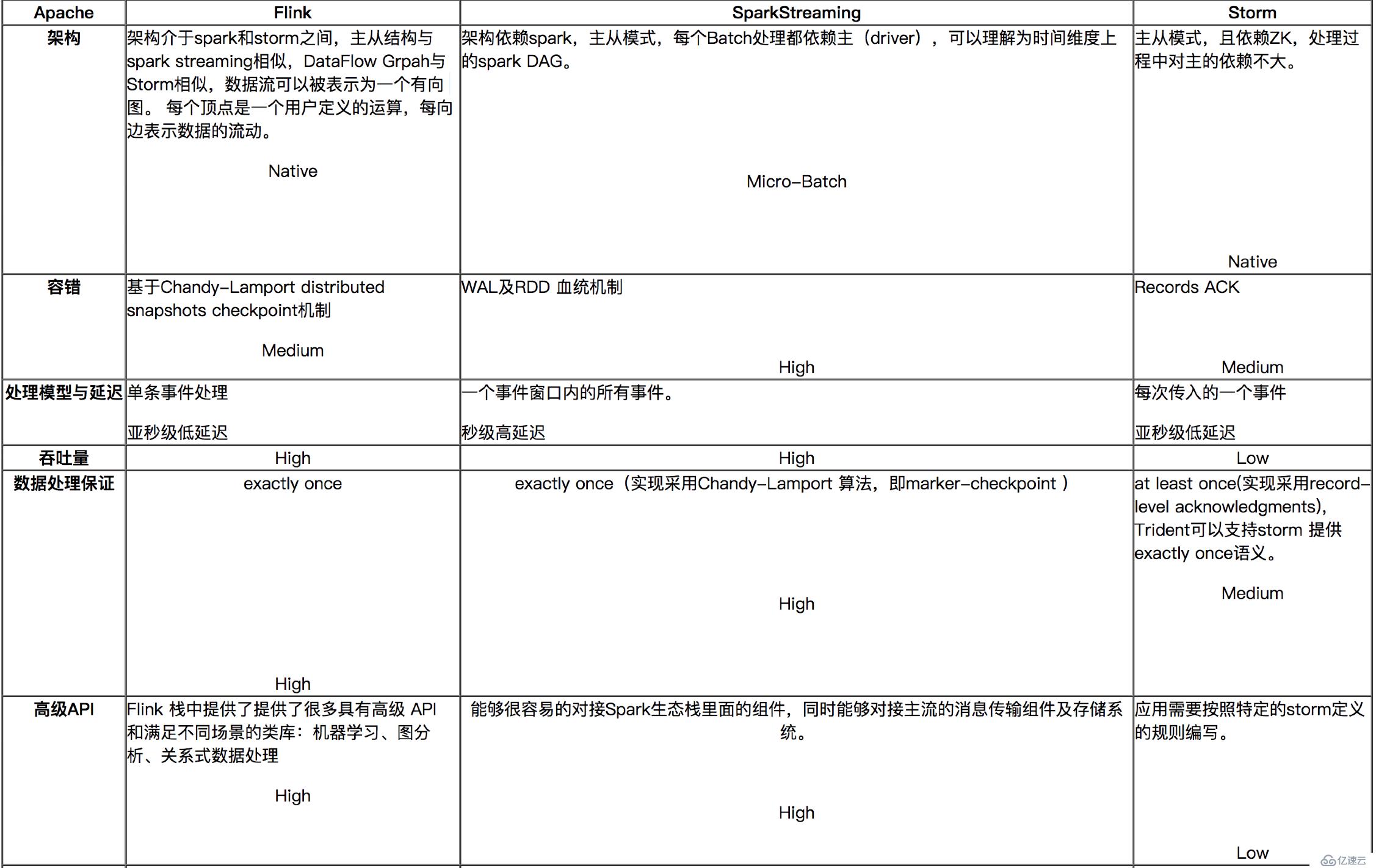
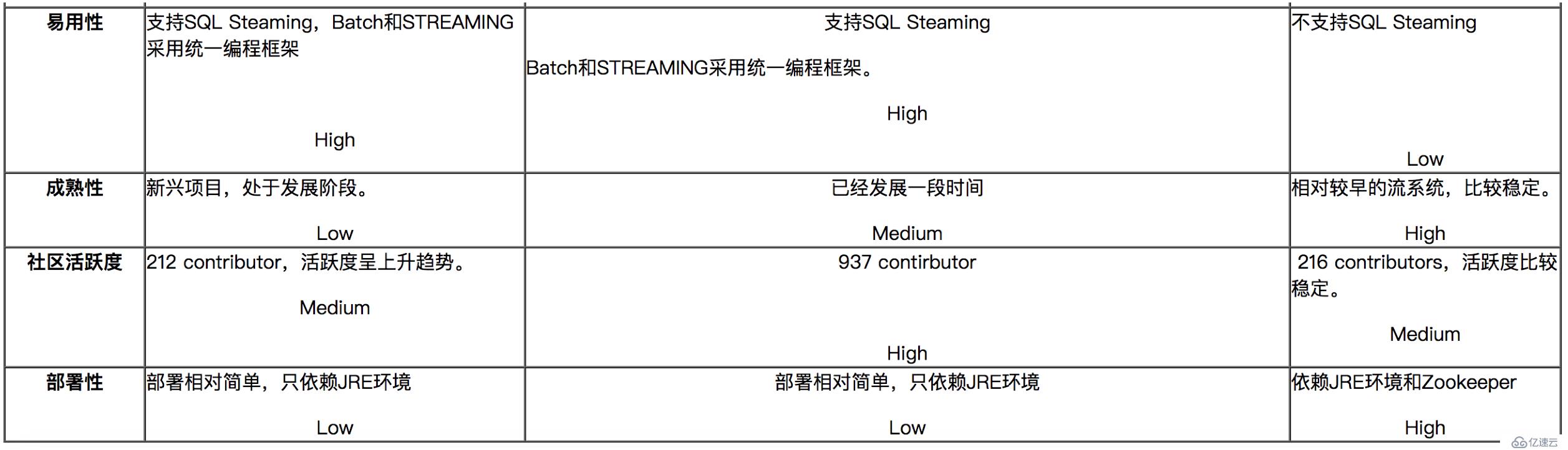
對比分析與建議:
? ? ? ?如果對延遲要求不高的情況下,建議使用Spark Streaming,豐富的高級,使用簡單,天然對接Spark生態棧中的其他組件,吞吐量大,部署簡單,UI界面也做的更加智能,社區活躍度較高,有問題響應速度也是比較快的,比較適合做流式的ETL,而且Spark的發展勢頭也是有目共睹的,相信未來性能和功能將會更加完善。
如果對延遲性要求比較高的話,建議可以嘗試下Flink,Flink是目前發展比較火的一個流系統,采用原生的流處理系統,保證了低延遲性,在和容錯上也是做的比較完善,使用起來相對來說也是比較簡單的,部署容易,而且發展勢頭也越來越好,相信后面社區問題的響應速度應該也是比較快的。
七、案例演示(java&scala)
1、maven依賴導入
<dependencies>
<!--java-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<!--scala-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.7</version>
</dependency>
</dependencies>
java代碼:
package?com.fwmagic.flink;
import?org.apache.flink.api.common.functions.FlatMapFunction;
import?org.apache.flink.api.java.utils.ParameterTool;
import?org.apache.flink.streaming.api.datastream.DataStream;
import?org.apache.flink.streaming.api.datastream.DataStreamSource;
import?org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import?org.apache.flink.streaming.api.windowing.time.Time;
import?org.apache.flink.util.Collector;
import?java.text.SimpleDateFormat;
import?java.util.Date;
/**
*?使用flink對指定窗口內的數據進行實時統計,最終把結果打印出來
*?先在機器上執行nc?-lk?9000
*/
public?class?StreamingWindowWordCountJava?{
public?static?void?main(String[]?args)?throws?Exception?{
//定義socket的端口號,默認9999
final?int?port;
try?{
final?ParameterTool?parameterTool?=?ParameterTool.fromArgs(args);
port?=?parameterTool.getInt("port",?9999);
}?catch?(Exception?e)?{
System.err.println("No?port?specified.?Please?run?'SocketWindowWordCount?--port?<port>'");
return;
}
//獲取運行環境
StreamExecutionEnvironment?env?=?StreamExecutionEnvironment.getExecutionEnvironment();
//連接socket獲取輸入的數據
DataStreamSource<String>?text?=?env.socketTextStream("localhost",?port,?"\n");
//計算數據
//拍平操作,把每行的單詞轉為<word,count>類型的數據
DataStream<WordWithCount>?windowCount?=?text.flatMap(new?FlatMapFunction<String,?WordWithCount>()?{
public?void?flatMap(String?value,?Collector<WordWithCount>?out)?{
String[]?splits?=?value.split("\\s");
for?(String?word?:?splits)?{
out.collect(new?WordWithCount(word,?1L));
}
}
//針對相同的word數據進行分組
}).keyBy("word")
//指定計算數據的窗口大小和滑動窗口大小,每1秒計算一次最近5秒的結果
.timeWindow(Time.seconds(5),Time.seconds(1))
.sum("count");
windowCount.print().setParallelism(1);
//把數據打印到控制臺,使用一個并行度
//?windowCount.print().setParallelism(1);
//注意:因為flink是懶加載的,所以必須調用execute方法,上面的代碼才會執行
env.execute("streaming?word?count");
}
/**
*?存儲單詞以及單詞出現的次數
*/
public?static?class?WordWithCount?{
public?String?word;
public?long?count;
public?WordWithCount()?{
}
public?WordWithCount(String?word,?long?count)?{
this.word?=?word;
this.count?=?count;
}
@Override
public?String?toString()?{
String?date?=?new?SimpleDateFormat("yyyy-MM-dd?HH:mm:ss").format(new?Date());
return?date?+?":{"?+
"word='"?+?word?+?'\''?+
",?count="?+?count?+
'}';
}
}
}
scala代碼:
package?com.fwmagic.flink
import?org.apache.flink.api.java.utils.ParameterTool
import?org.apache.flink.streaming.api.scala.{DataStream,?StreamExecutionEnvironment}
import?org.apache.flink.streaming.api.windowing.time.Time
import?org.apache.flink.streaming.api.scala._
object?StreamingWWC?{
def?main(args:?Array[String]):?Unit?=?{
val?parameterTool:?ParameterTool?=?ParameterTool.fromArgs(args)
val?port:?Int?=?parameterTool.getInt("port",9999)
val?env:?StreamExecutionEnvironment?=?StreamExecutionEnvironment.getExecutionEnvironment
val?text:?DataStream[String]?=?env.socketTextStream("localhost",port)
val?wc:?DataStream[WordCount]?=?text.flatMap(t?=>?t.split(","))
.map(w?=>?WordCount(w,?1))
.keyBy("word")
.timeWindow(Time.seconds(5),?Time.seconds(1))
.reduce((a,b)?=>?WordCount(a.word,a.count+b.count))
//.sum("count")
wc.print().setParallelism(1)
env.execute("word?count?streaming?!")
}
}
case?class?WordCount(word:String,count:Long)八、Flink部署
以local部署模式為例,后續會介紹在yarn上部署:
下載:http://apache.website-solution.net/flink/flink-1.8.0/flink-1.8.0-bin-scala_2.11.tgz
解壓:tar -zxvf flink-1.8.0-bin-scala_2.11.tgz
啟動:bin/start-cluster.sh
查看頁面:http://localhost:8081/
打包、提交任務:
mvn clean package
1、通過頁面的Submit new Job來提交任務
2、通過命令行提交:bin/flink run -c com.fwmagic.flink.StreamingWindowWordCountJava examples/myjar/fwmagic-flink.jar ?--port 6666
注意:提交任務前先開啟端口:nc -lk 6666
測試:
發送消息,在頁面中查看日志:TaskManagers->點擊任務->Stdout
或者在命令行查看日志:tail -f log/flink-*-taskexecutor-*.out

停止任務
1:web ui界面停止
2:命令行執行bin/flink cancel <job-id>
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。














