溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了 如何理解R語言分類算法中的樸素貝葉斯分類,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1.樸素貝葉斯分類原理解析
根據已知的先驗概率P(A|B),利用貝葉斯公式P(B|A)=P(A|B)P(B)/P(A)求出后驗概率P(B|A),即該樣本屬于某一類的概率,然后選擇具有最大后驗概率的類作為該樣本所屬的類.
也就是說,對于給出的待分類樣本,求出在此樣本出現條件下各個類別出現的概率,哪個最大,就認為此樣本屬于哪個類別.
其優勢在于不怕噪聲和無關變量,不足之處在于,它假設各個特征屬性是無關的,而現實情況往往不是如此.
2.在R語言中的應用
樸素貝葉斯分類主要用到了klaR包里面的NaiveBayes(formula,data,...,subset,na,action=na.pass)函數。
3.以iris數據集為例進行判別分析
1)應用模型并觀察結果
library(klaR) fit_Bayes1=NaiveBayes(Species~.,data_train) fit_Bayes1[1:length(fit_Bayes1)]
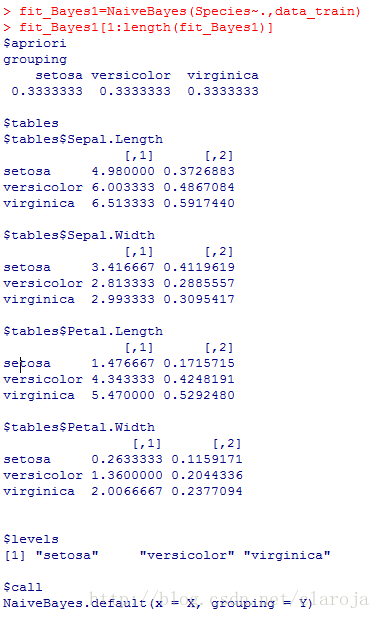

2)做出密度曲線
plot(fit_Bayes1)
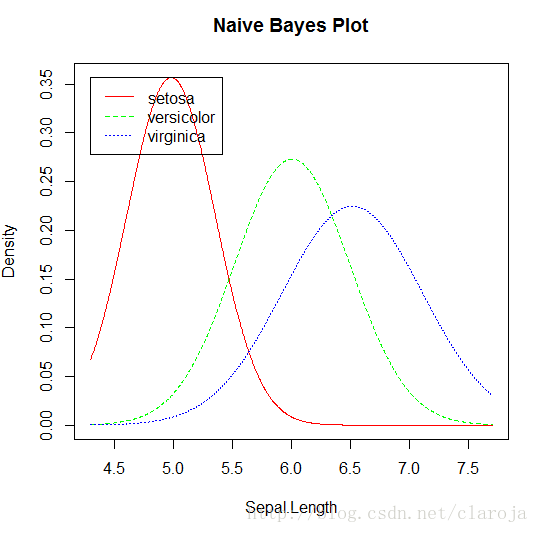
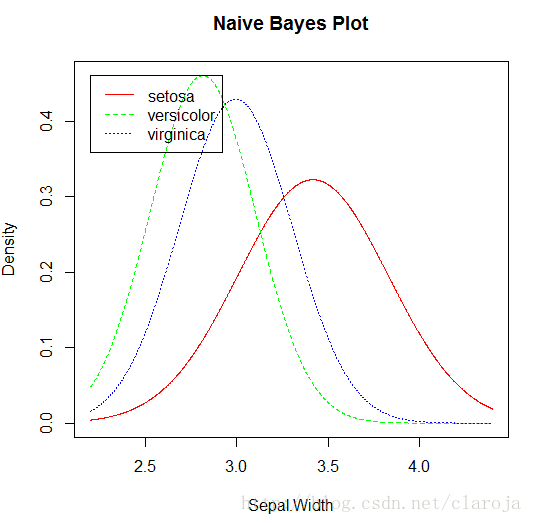
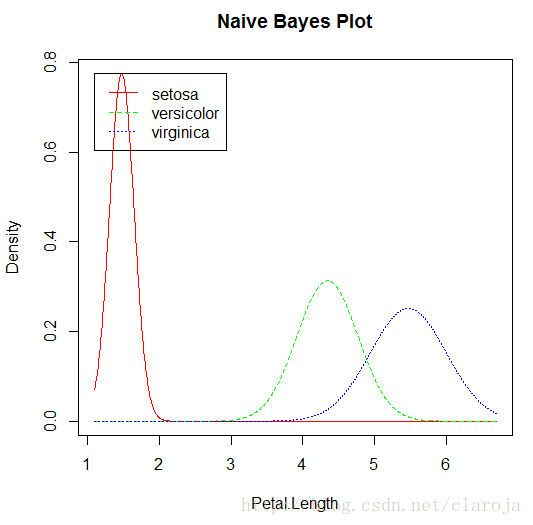
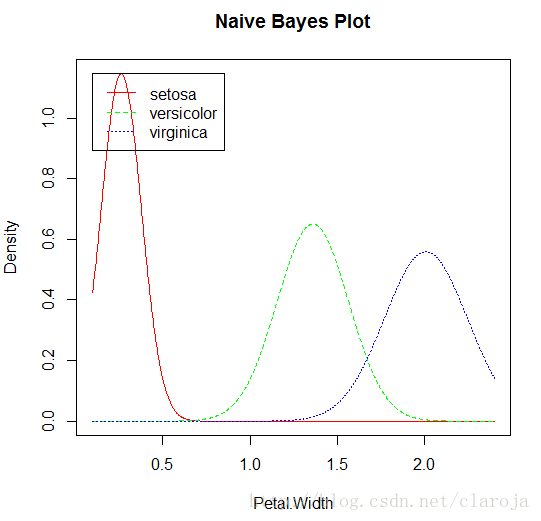
3)預測分析并對模型進行評測
pre_Bayes1=predict(fit_Bayes1,data_test) pre_Bayes1

table(data_test$Species,pre_Bayes1$class) error_Bayes1=sum(as.numeric(as.numeric(pre_Bayes1$class)!=as.numeric(data_test$Species)))/nrow(data_test); error_Bayes1

上述內容就是 如何理解R語言分類算法中的樸素貝葉斯分類,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





