溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了怎樣理解R語言,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
包是R函數、數據、預編譯代碼以一種定義完善的格式組成的集合。計算機上存儲包的目錄稱為庫(library)。函數.libPaths()能夠顯示庫所在的位置, 函數library()則可以顯示庫中有哪些包。
R自帶了一系列默認包(包括base、datasets、utils、grDevices、graphics、stats以及methods),它們提供了種類繁多的默認函數和數據集。其他包可通過下載來進行安裝。安裝好以后,它們必須被載入到會話中才能使用。命令search()可以告訴你哪些包已加載并可使用。
第一次安裝一個包,使用命令install.packages()即可,不加參數執行install.packages()將顯示一個CRAN鏡像站點的列表,選擇其中一個鏡像站點之后,將看到所有可用包的列表,選擇其中的一個包即可進行下載和安裝。如果知道自己想安裝的包的名稱,可以直接將包名作為參數提供給這個函數。
一個包僅需安裝一次。但和其他軟件類似,包經常被其作者更新。使用命update.packages()可以更新已經安裝的包。要查看已安裝包的描述,可以使用installed.packages()命令,這將列出安裝的包,以及它們的版本號、依賴關系等信息。
進入官方網站進行下載
https://cran.r-project.org/
數值(numeric)
字符(character)
邏輯值(logical)
復數型(complex)
 x[9]<-9;x # 當向量x不夠長時,指定第9個元素為9
x[9]<-9;x # 當向量x不夠長時,指定第9個元素為9


seq(length=,from=, to=)
length:指定生成個數
from:是指開始生成的點
to:截止點
如果不指定,則默認條件下:
seq(N1,N2,BY=)
n1:開始位置
n2:截止位置
by=指定間隔


#<,>,<=,>= 大于,小于,大于等于,小于等于
# %/% 整除
# %% 求余數
#abs絕對值,sqrt平方根
#簡單統計函數:sum求和,min最小值,
max最大值,mean平均值,

sort();
輸出排序后的結果;
order();
輸出排序后的各個向量位置



矩陣的存儲默認是按列進行存儲的

創建一個c(1:12)的三行四列的矩陣

y<-t(x)
若是針對的是一個向量
y<-(1:10)
轉置后得到的是行向量

用class( )函數獲得的類型分別是數值型和字符型
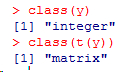
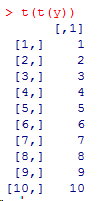
若要得到列向量則
4. 創建對角矩陣和單位陣

5.代數意義下的矩陣乘法"%*%"
yy<- matrix(1:6, 3, 2); zz <- matrix(1:6, 2, 3)
yy%*% zz; zz %*% yy
6. 矩陣行和列的維數
xx<- matrix(1:20, 4, 5)
dim(xx)#行和列的維數
nrow(xx);ncol(xx) #行數和列數
7.矩陣合并
aa<- matrix(1:6, 3, 2); bb <- matrix(7:12, 3, 2)
cbind(aa,bb) #按列合并
rbind(aa,bb) #按行合
8.矩陣apply()運算函數:
語法是apply(data, dim,function),dim取1表示對行運用函數,取2表示對列運用函數。
xx<- matrix(1:20, 4, 5)
colMeans(xx)#列均值
colSums(xx)#列和
rowMeans(xx)#行均值
rowSums(xx)#行和
i
由于不同的列可以包含不同模式(數值型、字符型等)的數據,數據框的概念較矩陣來說更為一般。數據框將是在R中常處理的 數據結構。
數據框可通過函數data.frame()創建,其中的列向量col1, col2, col3,…可為任何類型(如字符型、數值型或邏輯型)。每一列的 名稱可由函數names指定。
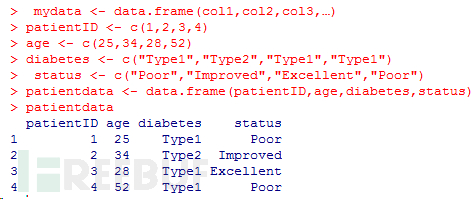
每一列數據的模式必須唯一,不過卻可以將多個模式的不同列放到一起組成數據框。
選取數據框中元素的方式有若干種。可以使用前述(如矩陣中的)下標記號,亦可直接指定列名。如:
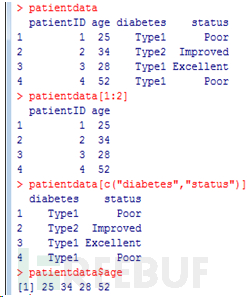
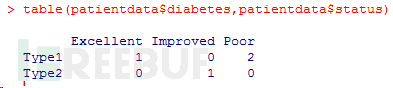
第三個例子中的記號$是新出現的 。它被用來選取一個給定數據框中的某個特定變量。例 如,如果你想生成糖尿病類型變量diabetes和病情變量status的列聯表,使用以下代碼即可
在每個變量名前都鍵入一次patientdata$可能會讓人生厭,所以不妨走一些捷徑。可以聯 合使用函數attach()和detach()或單獨使用函數with()來簡化代碼。
attach()、detach()和with() 函數attach()可將數據框添加到R的搜索路徑中。R在遇到一個變量名以后,將檢查搜索路 徑中的數據框,以定位到這個變量。
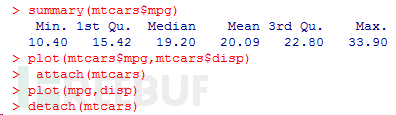
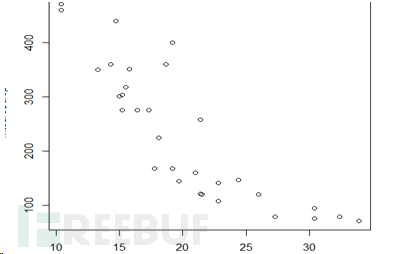
函數detach()將數據框從搜索路徑中移除。
當名稱相同的對象不止一個時,這種方法的局限性就很明顯了。

類別(名義型)變量和有序類別(有序型)變量在R中稱為因子(factor)。因子在R中非常重要,因為它決定了數據的分析方式以及如何進行視覺呈現。函數factor()以一個整數向量的形式存儲類別值,整數的取值范圍是[1… k ](其中k 是名義型變量中唯一值的個數),同時一個由字符串(原始值)組成的內部向量將映射到這些整數上。
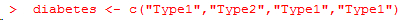
語句diabetes <- factor(diabetes)將此向量存儲為(1, 2,1, 1),并在內部將其關聯為 1=Type1和2=Type2(具體賦值根據字母順序而定)。針對向量diabetes進行的任何分析都會將 其作為名義型變量對待,并自動選擇適合這一測量尺度的統計方法。 要表示有序型變量,需要為函數factor()指定參數ordered=TRUE。給定向量:

語句status <- factor(status, ordered=TRUE)會將向量編碼為(3, 2, 1, 3),并在內部將這 些值關聯為1=Excellent、2=Improved以及3=Poor。
對于字符型向量,因子的水平默認依字母順序創建。這對于因子status是有意義的,因為 “Excellent”、“Improved”、“Poor”的排序方式恰好與邏輯順序相一致。如果“Poor”被編碼為 “Ailing”,會有問題,因為順序將為“Ailing”、“Excellent”、“Improved”。如果理想中的順序是 “Poor”、“Improved”、“Excellent”,則會出現類似的問題。按默認的字母順序排序的因子很少能夠讓人滿意。 你可以通過指定levels選項來覆蓋默認排序。
例如:

上述內容就是怎樣理解R語言,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





