溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關.net分布式系統架構的思路是什么,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
最近看到有部分招聘信息,要求應聘者說一下分布式系統架構的思路。今天早晨正好有些時間,我也把我們實際在.net方面網站架構的演化路線整理一下,只是我自己的一些想法,歡迎大家批評指正。
首先說明的是.net下開源內容較少,并且也不是做并行數據庫等基礎服務,因此在這里什么Hadoop、Spark、ZooKeeper、dubbo等我們暫不去考慮。
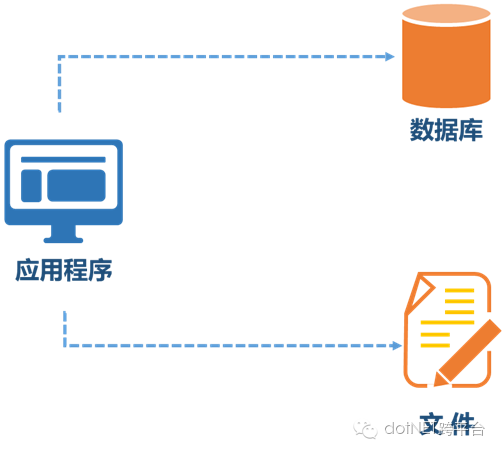
一、最初假設的網站中,我們把應用系統網站、文件和數據庫都放在一臺服務器上,一臺服務器包打天下。
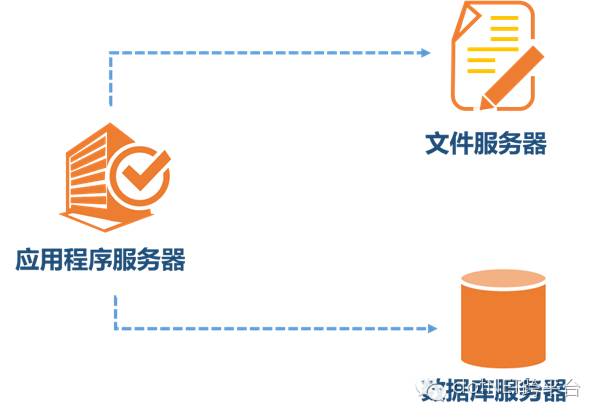
二、隨著業務擴展,一臺服務器無法滿足性能需求,將應用程序、數據庫、文件分別部署在不同的服務器上,并根據服務器用途不同,配置不同的硬件,達到性能最佳的效果。
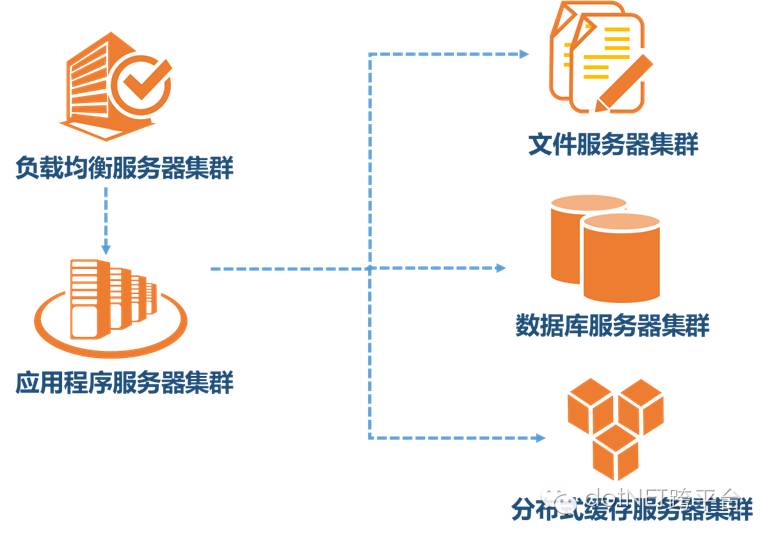
三、隨著業務擴展,一臺數據庫、網站、文件服務器再高性能也無法大量數據處理、高并發用戶訪問時,必須考慮采用集群方式。
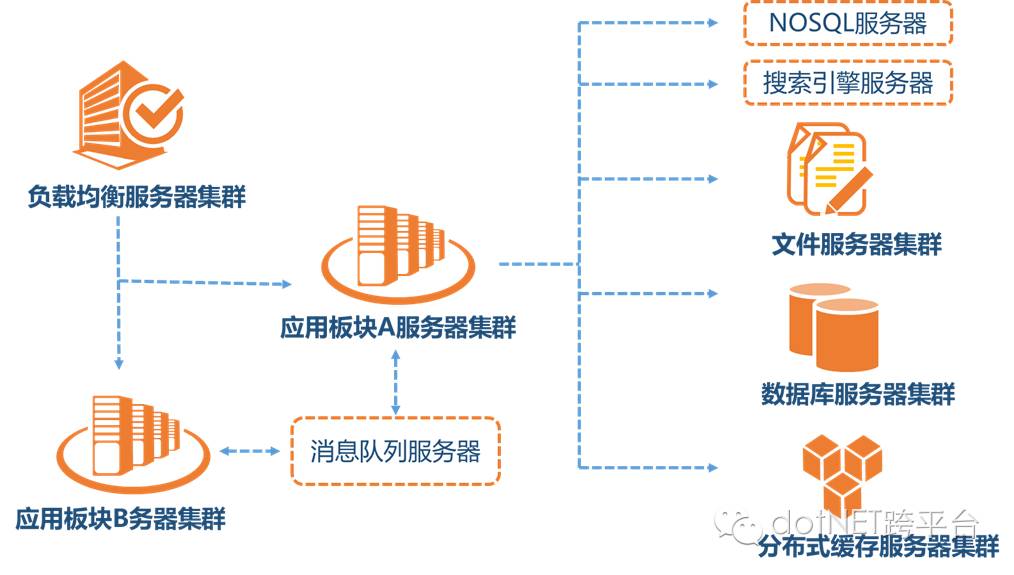
1、應用服務器作為網站的入口,會承擔大量的請求,我們往往通過應用服務器集群來分擔請求數。應用服務器前面部署負載均衡服務器調度用戶請求,根據分發策略將請求分發到多個應用服務器節點。常用的負載均衡技術硬件的有F5,價格比較貴,軟件的有LVS、Nginx、HAProxy等。
2、隨著用戶量的增加,數據庫成為最大的瓶頸,改善數據庫性能常用的手段是進行讀寫分離以及分表,讀寫分離顧名思義就是將數據庫分為讀庫和寫庫,通過主備功能實現數據同步。分庫分表則分為水平切分和垂直切分,水平切換則是對一個數據庫特大的表進行拆分,例如訂單、物流信息表等。垂直切分則是根據業務不同來切換,如訂單、計稅等等不同的主題放在不同的數據庫中。這種情況下,關聯查詢是沒有的,通過程序可以比較容易的去解決,還有就是采用分布式事務,來保證數據的一致性。我們這里還有一個做法,一個大的數據表拆分為當前操作表和歷史記錄表, 當前操作表只保留正在操作的數據,完成后轉入歷史記錄表,這樣可以提高當前操作數據的效率。
3、用戶一天天增加,業務量越來越大,產生的文件越來越多。通常情況下,一個目錄下的文件建議不能超過1萬個,否則對于文件的查找和輪詢都會非常慢,會導致整個系統無法正常運行。我們一般是按照"\應用程序名\模塊名稱\日期"的目錄結構組織的,對于文件數目仍舊很大的應用,應該再細分。當單臺的文件服務器已經不能滿足需求,就需要分布式的文件系統支撐。常用的分布式文件系統有NFS。我們用的是MS的分布式文件系統(DFS),與AD域相關性較大。
4、因為應用服務器是集群方式,用戶前后兩次請求可能訪問的不是一臺服務器。因此已經不能像以前一樣使用狀態(Application、Session、Cache、ViewState等),應用系統必須是無狀態的(當然了,用的負載均衡具有會話保持的時候,一個用戶只會定位到一臺服務器)。系統的緩存應該保存在專門的緩存服務器上,如果必須有狀態,也應該保存在專門的緩存服務器中。作為第一批吃螃蟹者,我們用了微軟的AppFabric作為緩存服務器,因為當時版本很低,問題也不少,后來我們棄用了AppFabric,使用Redis作為緩存服務。現在,AppFabric已經改進了不少,運行在Azure云上,應該是不會存在以前的問題了。
中間插一段啊。對于各種政府、單位等不能將系統部署到互聯網的部門,并且在各省、市都有對應的分支機構。因為網絡專線的價格還是比較高的,至少比互聯網的網絡帶寬低了不少,當然了不差錢的不說啊。這種情況下,一般不采用如上的集中式、集群部署方式,而是采用分布式部署的方式,第一種分布式部署是各分支機構搭建一整套系統,定期(例如每天)進行數據的同步工作,將分支數據匯總到總部、總部的數據下發回各分部;第二種分布式部署方式是各分支部署中間件,但是數據集中在總部。
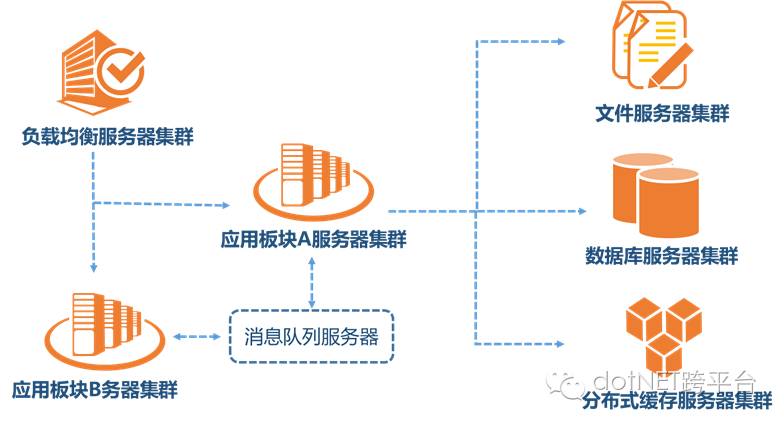
四、隨著業務進一步擴展,應用程序變得非常臃腫,這時我們需要將應用程序進行業務拆分,如我們做的綜合業務管理系統分為門戶、聯系處置、業務信息、指標、數據查詢分析等業務板塊。每個業務板塊是一個獨立的應用負責相對獨立的業務運作。業務板塊之間通過消息隊列進行通信來實現。數據庫也進行相應的拆分,不同的主題放到不同的數據庫中。同時,最好搭建靜態資源服務器,將公用的css、js、images等都存放到靜態資源服務器中。
五、對于海量數據的查詢,我們使用nosql數據庫加上搜索引擎可以達到更好的性能。并不是所有的數據都要放在關系型數據中。常用的NOSQL有mongodb和redis,搜索引擎有lucene,我們使用的Solr、ElasticSearch等基于Lucene內核實現的更易用的搜索引擎。數據量大的話,Solr等也要做成集群。
六、再往下走,系統需要與其他系統進行交互,系統也要給各種前端(例如網站、安卓、IOS)提供服務,這樣我們就要在邏輯層之上建設應用服務層,提供對客戶端的和對外的SOA服務接口。這樣又涉及到DTO、WebService、WCF和WebApi(Rest)等概念。但是最重要的是,SOA方式下,包括前面的MQ方式下,事務一致性無法得到保障的,必須采用一定的機制例如事務補償機制來確保事務的最終一致性。各個業務板塊所在的服務器,在不同時段的壓力也不同,為了盡量做到服務器集群內各服務器的壓力平攤, 還需要提供更好的機制,記錄下每個服務器的壓力、資源情況、連接數等等,以便將新的請求轉向到壓力最小的服務器上。
七、業務繼續發展,就是CDN,再往下就是搭建幾個中心,將系統部署在各個中心,各地用戶訪問距離他最近的中心,中心間數據保持同步。
八、上面講了應用系統方面比較多,數據方面也要做許多工作。上面已經介紹了分庫分表方式。應用系統做大了,勢必有許多的數據資源,尤其是現在大數據這個名詞非常火爆的情況下,數據分析和處理是一個系統必須要做的事情。這樣做的好處是,將數據的查詢、分析等獨立出來,不影響正式運行中的系統,另外是通過分析挖掘確實能得到許多意想不到的價值。
這時,主要的工作是搭建數據倉庫,然后進行后續的分析和處理。使用ETL/ELT將數據定期從正式環境中導入到數據倉庫中,按照不同的主題搭建一個個的數據集市。對于數據量比較小的系統,可以使用關系數據庫+多維數據庫的方式;對于大型系統,就要使用按列存儲、并行數據庫等方式了。對于數據的分析可以以報表、KPI、儀表盤駕駛艙等方式提供上層領導決策,也可以使用數據挖掘、機器學習和訓練等方式實現價值發現、風險控制等。
九、一般情況下,企業是沒有那么大的財力和人員去做上述內容的,因此使用云成為企業的一個選擇。無論是Azure、阿里云、亞馬遜等都會提供一個個的服務。我們就以阿里云為例,ECS提供虛擬服務器、SLB提供負載均衡、RDS提供數據庫服務、OSS提供存儲服務、DRDS是分布式數據服務、ODSP(現在改名叫MaxCompute)提供大數據的計算服務、RocketMQ提供MQ、OCS提供分布式緩存服務、以及CDN、OTS、ADS等等就不一一列舉了。
對了,現在還有Docker這個利器,無論在企業還是云中都可以使用,我們在自己內部使用的Redis、Memcached、RabbitMQ、Solr等都部署在Docker中,確實比較方便。
上面說了一大堆,其實架構做的再好,還需要底層來實現。目前流行的語言還是面向對象OO的Java、.net等,也就是說還是用OO的思想和理念去編程。抽象、封裝、繼承、多態盡管很字面上比較容易理解,但是深入的認識確實需要一定的程序量的積累,面向對象的幾大原則和設計模式還是編寫出更高可擴展、可替換、可配置、可維護等軟件質量指標的代碼的重要保證。
看完上述內容,你們對.net分布式系統架構的思路是什么有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





