溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關namenode中怎么存儲復本,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Hadoop的默認布局策略是在運行客戶端的節點上放第1個復本,如果客戶端運行在集群之外就隨機選擇一個節點,不過系統會避免挑選那些存儲太滿或太忙的節點。第2個復本放在與第一個不同且隨機另外選擇的機架中節點上(離架)。第3個復本與第2個復本放在同一機架上,且隨機選擇另外一個節點。其他復本放在集群中隨機選擇的節點上,不過系統會盡量避免在同一個機架上放太多的復本。
一旦選定復本的放置位置,就根據網絡拓撲創建一個管線,如果復本為3,則有如圖的管線。
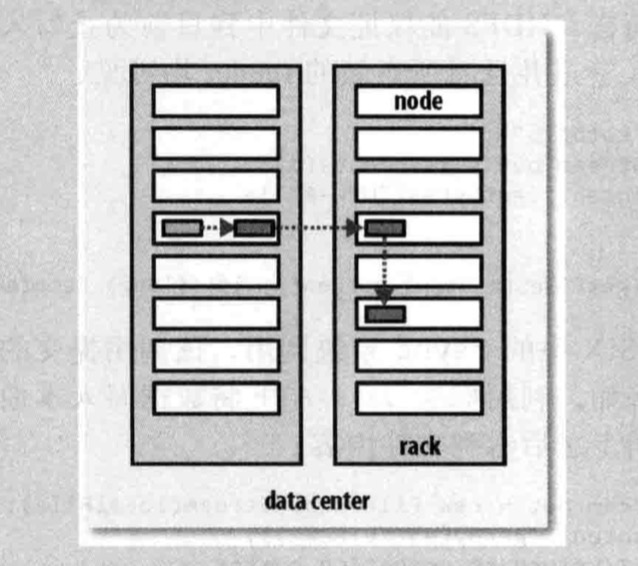
總的來說,這一方法不僅提供很好的穩定性(數據塊存儲在兩個機架中)并且實現很好的附在均衡,包括寫入帶寬(寫入操作只需要遍歷一個交換機),讀取性能(可以從兩個機架中選擇讀取)和集群中塊的均勻分布(客戶端只在本地機架上寫入一個塊)。
以上就是namenode中怎么存儲復本,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





