溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關hadoop2.0中namenode ha如何配置,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
hdfs的ha,主要的問題是active和standby的元數據信息同步問題,之前的解決方案有avatar等一系列。共享存儲可以采用NFS,bookkeeper等相關存儲。在這里我們采用Journal來實現共享存儲,主要是因為配置簡單。
虛擬機準備:三臺,列表如下:
機器名 | 功能 | IP |
master1 | namenode(active),JournalNode,zookeeper | 192.168.6.171 |
master2 | namenode,JournalNode,zookeeper | 192.168.6.172 |
datanode1 | datanode,JournalNode,zookeeper | 192.168.6.173 |
軟件版本:hadoop 2.4.1 zookeeper3.4.6
下載hadoop2.4.1后,解壓,解壓zookeeper
第一步先配置zookeeper集群
將zookeeper解壓后的文件夾下的conf下的zoo_sample.cfg重命名為zoo.cfg
修改配置
dataDir=/cw/zookeeper/ 我這里修改為/cw/zookeeper/ 確保該文件夾存在
在該文件尾部添加集群配置
server.1=192.168.6.171:2888:3888
server.2=192.168.6.172:2888:3888
server.3=192.168.6.173:2888:3888
將修改后的zookeeper文件夾分發到其他兩臺機器上
scp -r zookeeper-3.4.6 root@192.168.6.172:/cw/
scp -r zookeeper-3.4.6 root@192.168.6.173:/cw/
配置每臺機器的pid
在192.168.6.171機器上執行
echo "1" >> /cw/zookeeper/myid
在192.168.6.172機器上執行
echo "2" >> /cw/zookeeper/myid
在192.168.6.173機器上執行
echo "3" >> /cw/zookeeper/myid
啟動zookeeper,每臺分別執行
./zkServer.sh start
都啟動完成后,可以通過查看日志確認是否啟動OK,或者執行 ./zkServer.sh status來查看每一個節點的狀態。
---------------------------------------------------華立分割 hadoop開始----------------------------------------------------------------------------配置hadoop的相關參數
hadoop-env.sh主要配置java_home的路徑
core-site.xml配置內容如下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhadoop</value>
myhadoop是namespace的id
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.6.171,192.168.6.172,192.168.6.173</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>myhadoop</value>對應之前的namespace
<description>
Comma-separated list of nameservices.
as same as fs.defaultFS in core-site.xml.
</description>
</property>
<property>
<name>dfs.ha.namenodes.myhadoop</name>
<value>nn1,nn2</value>每一個nn的id編號
<description>
The prefix for a given nameservice, contains a comma-separated
list of namenodes for a given nameservice (eg EXAMPLENAMESERVICE).
</description>
</property>
<property>
<name>dfs.namenode.rpc-address.myhadoop.nn1</name>
<value>192.168.6.171:8020</value>
<description>
RPC address for nomenode1 of hadoop-test
</description>
</property>
<property>
<name>dfs.namenode.rpc-address.myhadoop.nn2</name>
<value>192.168.6.172:8020</value>
<description>
RPC address for nomenode2 of hadoop-test
</description>
</property>
<property>
<name>dfs.namenode.http-address.myhadoop.nn1</name>
<value>192.168.6.171:50070</value>
<description>
The address and the base port where the dfs namenode1 web ui will listen on.
</description>
</property>
<property>
<name>dfs.namenode.http-address.myhadoop.nn2</name>
<value>192.168.6.172:50070</value>
<description>
The address and the base port where the dfs namenode2 web ui will listen on.
</description>
</property>
<property>
<name>dfs.namenode.servicerpc-address.myhadoop.n1</name>
<value>192.168.6.171:53310</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.myhadoop.n2</name>
<value>192.168.6.172:53310</value>
</property>
下部分為對應的文件存儲目錄配置
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///cw/hadoop/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.6.171:8485;192.168.6.172:8485;192.168.6.173:8485/hadoop-journal</value>
<description>A directory on shared storage between the multiple namenodes
in an HA cluster. This directory will be written by the active and read
by the standby in order to keep the namespaces synchronized. This directory
does not need to be listed in dfs.namenode.edits.dir above. It should be
left empty in a non-HA cluster.
</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///cw/hadoop/data</value>
<description>Determines where on the local filesystem an DFS data node
should store its blocks. If this is a comma-delimited
list of directories, then data will be stored in all named
directories, typically on different devices.
Directories that do not exist are ignored.
</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>
Whether automatic failover is enabled. See the HDFS High
Availability documentation for details on automatic HA
configuration.
</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/cw/hadoop/journal/</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.myhadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/yarn/.ssh/id_rsa</value>
<description>the location stored ssh key</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>1000</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>8</value>
</property>
</configuration>
以上所涉及的文件夾需要手工建立,如不存在會出現異常。
以后配置完成后,將配置好的hadoop分發到所有集群節點。同時每一個節點建立需要的文件夾。
下面開始格式化zk節點,執行:./hdfs zkfc -formatZK
執行完畢后,啟動ZookeeperFailoverController,用來監控主備節點的狀態。
./hadoop-daemon.sh start zkfc 一般在主備節點啟動就可以
下一步啟動共享存儲系統JournalNode
在各個JN節點上啟動:hadoop-daemon.sh start journalnode
下一步,在主NN上執行./hdfs namenode -format格式化文件系統
執行完畢后啟動主NN./hadoop-daemon.sh start namenode
在備用NN節點先同步NN的元數據信息,執行./hdfs namenode -bootstrapStandby
同步完成后,啟動備用NN ./hadoop-daemon.sh start namenode
由于zk已經自動選擇了一個節點作為主節點,這里不要手工設置。如想手工設置主備NN可以執行
./hdfs haadmin -transitionToActive nn1
啟動所有的datanode
分別打開192.168.6.171:50070和192.168.6.172:50070
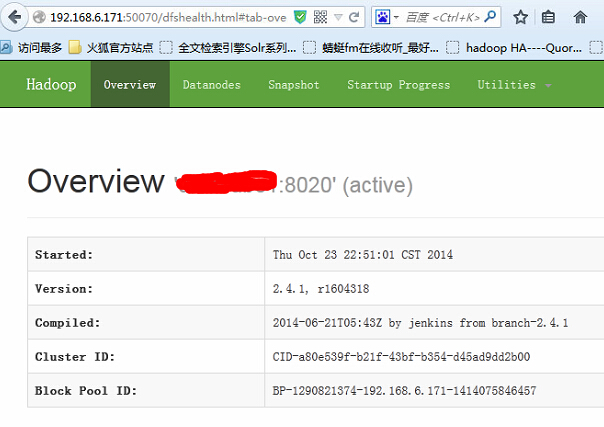

可以執行相關的hdfs shell命令來驗證集群是否正常工作。
下面來kill掉主節點的NN
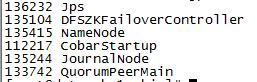
kill -9 135415
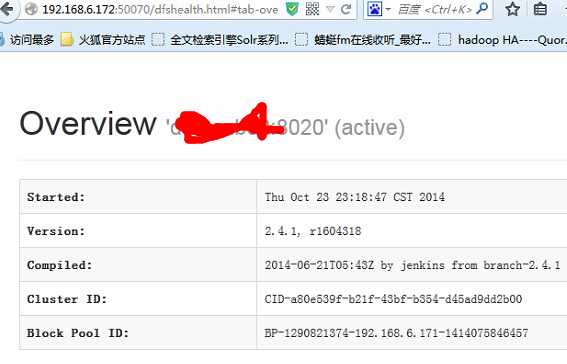
可以看到已經成功切換。
關于“hadoop2.0中namenode ha如何配置”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





