溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行spark2.0.1安裝部署及使用jdbc連接基于hive的sparksql,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
如下配置,除了配置spark還配置了spark history服務
#先到http://spark.apache.org/根據自己的環境選擇編譯好的包,然后獲取下載連接 cd /opt mkdir spark wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.6.tgz tar -xvzf spark-2.0.1-bin-hadoop2.6.tgz cd spark-2.0.1-bin-hadoop2.6/conf
復制一份spark-env.sh.template,改名為spark-env.sh。然后編輯spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_111 export SPARK_MASTER_HOST=hadoop-n
復制一份spark-defaults.conf.template,改成為spark-defaults.conf,然后編輯spark-defaults.conf
#指定master地址,以便在啟動的時候不用再添加--master參數來啟動集群 spark.master spark://hadoop-n:7077 #對sql查詢進行字節碼編譯,小數據量查詢建議關閉 spark.sql.codegen true #開啟任務預測執行機制,當出現比較慢的任務時,嘗試在其他節點執行該任務的一個副本,幫助減少大規模集群中個別慢任務的影響 spark.speculation true #默認序列化比較慢,這個是官方推薦的 spark.serializer org.apache.spark.serializer.KryoSerializer #自動對內存中的列式存儲進行壓縮 spark.sql.inMemoryColumnarStorage.compressed true #是否開啟event日志 spark.eventLog.enabled true #event日志記錄目錄,必須是全局可見的目錄,如果在hdfs需要先建立文件夾 spark.eventLog.dir hdfs://hadoop-n:9000/spark_history_log/spark-events #是否啟動壓縮 spark.eventLog.compress true
復制一份slaves.template,改成為slaves,然后編輯slaves
hadoop-d1 hadoop-d2
從$HIVE_HOME/conf下拷貝一份hive-site.xml到當前目錄下。
編輯/etc/下的profile,在末尾處添加
export SPARK_HOME=/opt/spark/spark-2.0.1-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://hadoop-n:9000/spark_history_log/spark-events"
為了保證絕對生效,/etc/bashrc也做同樣設置,然后刷新設置
source /etc/profile source /etc/bashrc
a)首先啟動hadoop;
cd $HADOOP_HOME/sbin ./start-dfs.sh
訪問http://ip:port:50070查看是否啟動成功
b)然后啟動hive
cd $HIVE_HOME/bin ./hive --service metastore
執行beeline或者hive命令查看是否啟動成功,默認hive日志在/tmp/${username}/hive.log
c)最后啟動spark
cd $SPARK_HOME/sbin ./start-all.sh
sprark ui :http://hadoop-n:8080
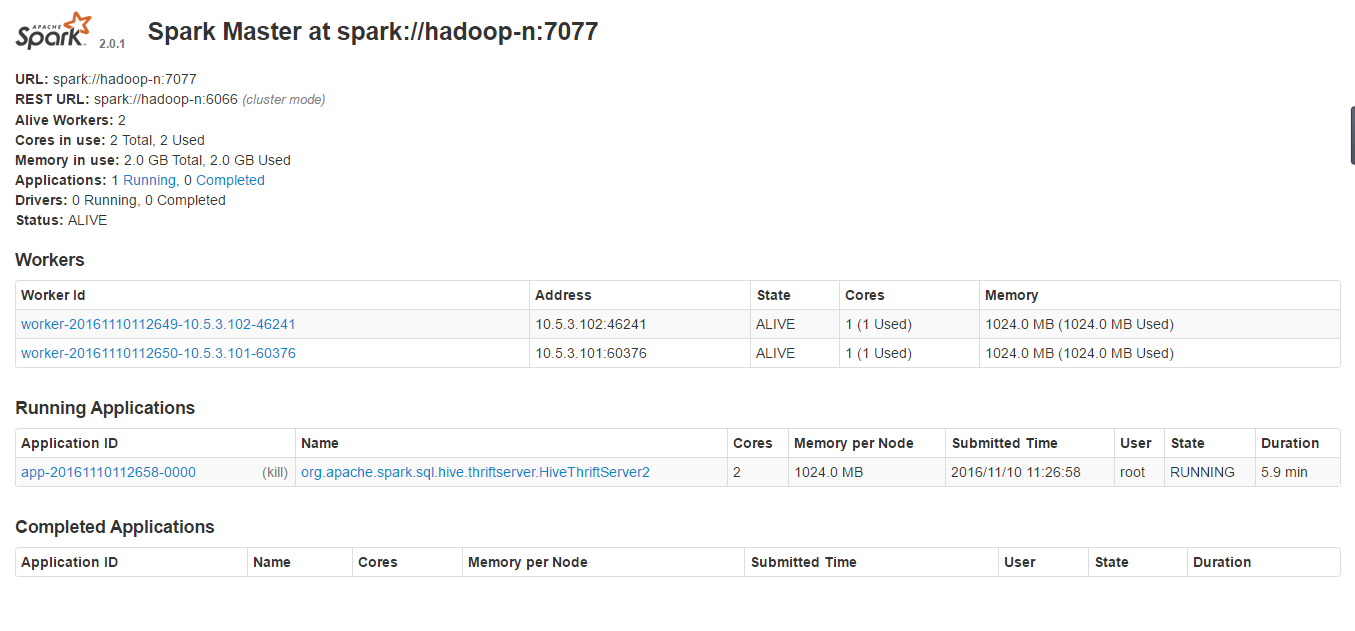
spark客戶端
cd $SPARK_HOME/bin ./spark-shell
sparksql客戶端
cd $SPARK_HOME/bin ./spark-sql
注意執行命令后提示的webui的端口號,通過webui可以查詢對應監控信息。
啟動thriftserver
cd $SPARK_HOME/sbin ./start-thriftserver.sh
spark thriftserver ui:http://hadoop-n:4040
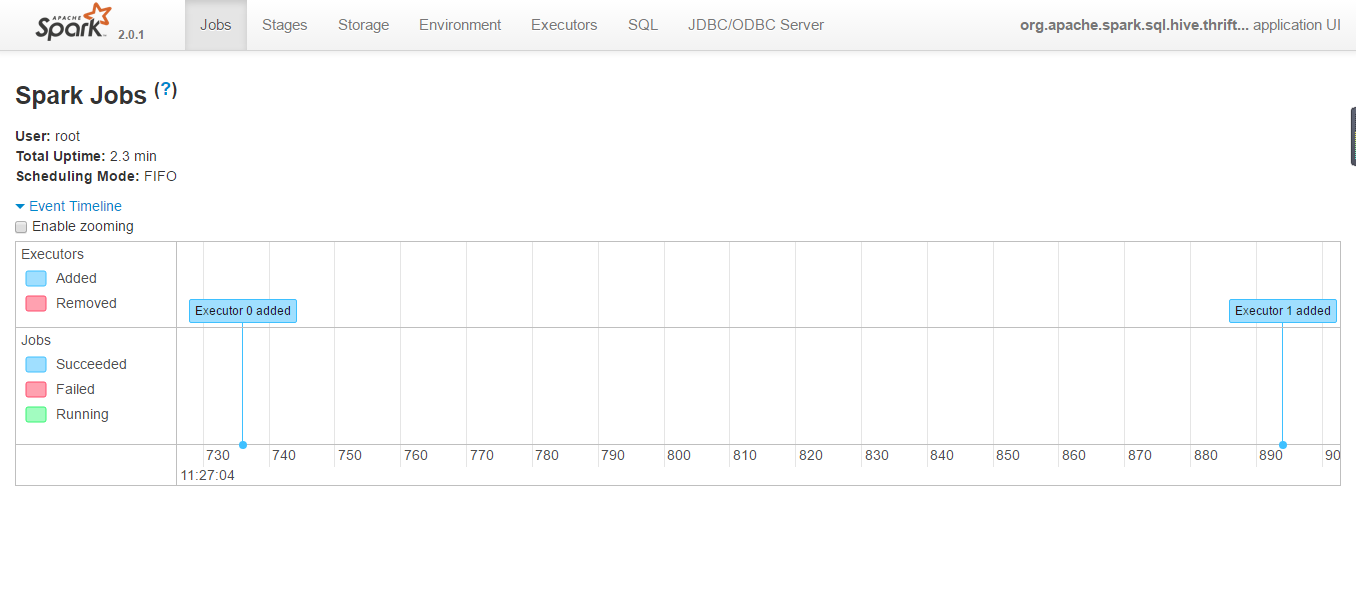
啟動historyserver
cd $SPARK_HOME/sbin ./start-history-server.sh
spark histroy ui:http://hadoop-n:18080
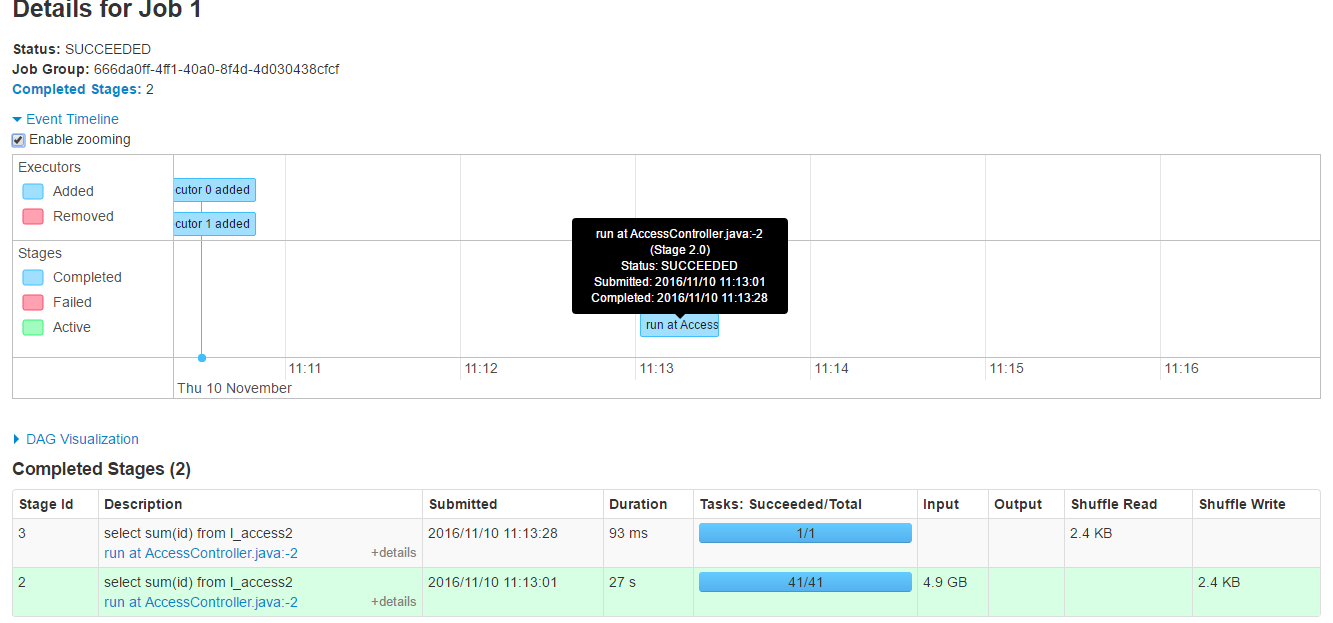
a)如果hive啟動了hiveserver2,關閉
b)執行如下命令啟動服務
cd $SPARK_HOME/sbin ./start-thriftserver.sh
執行如下命令測試是否啟動成功
cd $SPARK_HOME/bin ./beeline -u jdbc:hive2://ip:10000 #如下是實際輸出 [root@hadoop-n bin]# ./beeline -u jdbc:hive2://hadoop-n:10000 Connecting to jdbc:hive2://hadoop-n:10000 16/11/08 21:03:05 INFO jdbc.Utils: Supplied authorities: hadoop-n:10000 16/11/08 21:03:05 INFO jdbc.Utils: Resolved authority: hadoop-n:10000 16/11/08 21:03:05 INFO jdbc.HiveConnection: Will try to open client transport with JDBC Uri: jdbc:hive2://hadoop-n:10000 Connected to: Spark SQL (version 2.0.1) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 1.2.1.spark2 by Apache Hive 0: jdbc:hive2://hadoop-n:10000> show databases; +---------------+--+ | databaseName | +---------------+--+ | default | | test | +---------------+--+ 2 rows selected (0.829 seconds) 0: jdbc:hive2://hadoop-n:10000>
編寫代碼連接sparksql
按照自己的環境添加依賴
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>然后編寫類
/**
*
* @Title: HiveJdbcTest.java
* @Package com.scc.hive
* @Description: TODO(用一句話描述該文件做什么)
* @author scc
* @date 2016年11月9日 上午10:16:32
*/
package com.scc.hive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
*
* @ClassName: HiveJdbcTest
* @Description: TODO(這里用一句話描述這個類的作用)
* @author scc
* @date 2016年11月9日 上午10:16:32
*
*/
public class HiveJdbcTest {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
Connection con = DriverManager.getConnection("jdbc:hive2://10.5.3.100:10000", "", "");
Statement stmt = con.createStatement();
String tableName = "l_access";
String sql = "";
ResultSet res = null;
sql = "describe " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
sql = "select * from " + tableName + " limit 10;";
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getObject("id"));
}
sql = "select count(1) from " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println("count:" + res.getString(1));
}
}
}下面是控制臺輸出
log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. id int req_name string req_version string req_param string req_no string req_status string req_desc string ret string excute_time int req_time date create_time date 212 213 214 215 216 217 218 219 220 221 count:932
集群要配置ssh免密碼登錄
不要忘記拷貝hive的配置文件,不然spark會在本地創建物理數據庫文件
hive啟動時提示ls: cannot access /opt/spark/spark-2.0.1-bin-hadoop2.6/lib/spark-assembly-*.jar: No such file or directory,不影響程序運行。
看完上述內容,你們掌握如何進行spark2.0.1安裝部署及使用jdbc連接基于hive的sparksql的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





