溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
接下來做的操作是:(這個操作,將程序打成jar包到集群中運行)
(1)編寫spark程序在線上的hive中創建表并導入數據
(2)查詢hive中的數據
(3)將查詢結果保存到MySQL中
代碼:
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//屏蔽多余的日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//構建編程入口
val conf: SparkConf = new SparkConf()
conf.setAppName("SparkSqlTest")
val spark: SparkSession = SparkSession.builder().config(conf)
.enableHiveSupport() //這句話表示支持hive
.getOrCreate()
//創建sqlcontext對象
val sqlContext: SQLContext = spark.sqlContext
//創建sparkContext
val sc: SparkContext = spark.sparkContext
//創建數據庫
var sql=
"""
|create database if not exists `test`
""".stripMargin
spark.sql(sql)
//使用當前創建的數據庫
sql=
"""
|use `test`
""".stripMargin
spark.sql(sql)
//創建hive表
sql=
"""
|create table if not exists `test`.`teacher_basic`(
|name string,
|age int,
|married boolean,
|children int
|) row format delimited
|fields terminated by ','
""".stripMargin
spark.sql(sql)
//加載數據
sql=
"""
|load data local inpath 'file:///home/hadoop/teacher_info.txt'
|into table `test`.`teacher_basic`
""".stripMargin
spark.sql(sql)
//執行查詢操作
sql=
"""
|select * from `test`.`teacher_basic`
""".stripMargin
val hiveDF=spark.sql(sql)
val url="jdbc:mysql://localhost:3306/test"
val table_name="teacher_basic"
val pro=new Properties()
pro.put("password","123456")
pro.put("user","root")
hiveDF.write.mode(SaveMode.Append).jdbc(url,table_name,pro)
}
}打jar包到集群中運行:https://blog.51cto.com/14048416/2337760
作業提交shell:
spark-submit \
--class com.zy.sql.SparkSqlTest \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 512M \
--total-executor-cores 1 \
file:////home/hadoop/SparkSqlTest-1.0-SNAPSHOT.jar \然后滿懷期待的等待著success,不幸的是,當程序運行到一半的時候異常終止了:
我查看了一下打印的日志: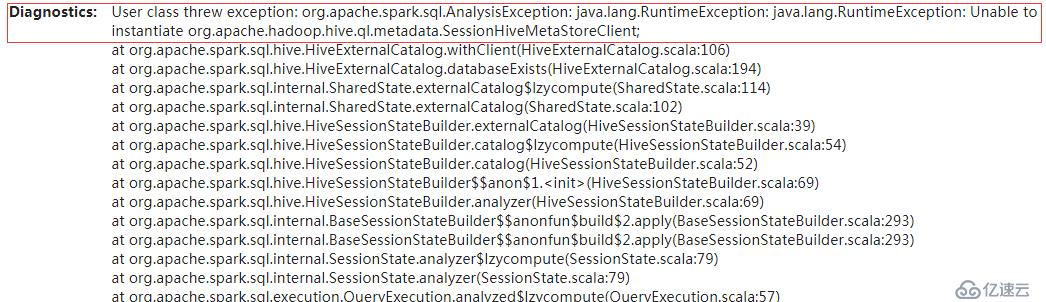
我上網查了好多資料,都說是hive的版本過高,what? I‘not why!!
然后想了想,我在集群中,使用spark的程序,去在hive表中進行操作,那么是不是spark需要和hive整合一下啊,然后我又上網查了spark如何整合hive,總的來說就是將hive的元數據庫共享出去,讓spark可以訪問。
具體操作:
①在hive的hive-site.xml加入:
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083</value> #在哪里啟動這個進程
</property>②在相應的節點上啟動在hive-site.xml中配置的進程
nohup hive --service metastore 1>/home/hadoop/logs/hive_thriftserver.log 2>&1 &ps:這里需要注意一下,nohup是后臺啟動的,而且所有的信息都是定向輸出的,這條命令使用之后,一定要檢查一下這個命令是否真的執行成功了:
使用:jsp查一下是否有相應的進程啟動,如果沒有表示啟動失敗,肯定是 /home/hadoop/logs這個父目錄沒有創建,然后創建這個目錄之后,在啟動,在檢查是否啟動成功!!!!!!!
③將hive-site.xml復制到$SPARK_HOME/conf下(注意是每一個節點都要復制)
④測試是否成功:spark-sql,如果正確進入并且可以訪問hive的表,表示spark整合hive成功!!!
之后我有將原來的程序,重新跑了一次,結果 沒有報錯,程序運行成功!!!
我不敢相信,我又查看了一下MySQL的表: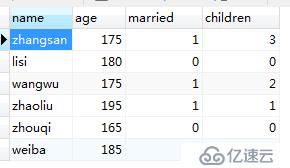
確認 程序成功!!!!!!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





