溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下spark mllib如何實現快速迭代聚類,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
package spark.clustering
import org.apache.spark.mllib.clustering.{PowerIterationClustering}
import org.apache.spark.{SparkConf, SparkContext}
/**
* 快速迭代聚類
* 基本原理:使用含有權重的無向線將樣本數據連接在一張無向圖中,之后按照相似度劃分,
* 使得劃分后的子圖內部具有最大的相似度二不同的子圖具有最小的相似度從而達到聚類的效果.
* 數據源要求 RDD[(Long), (Long), (Double)]
* 第一個參數和第二個參數是第一個點和第二個點的編號,即其之間 ID,第三個參數是相似度計算值.
* Created by eric on 16-7-21.
*/
object PIC {
val conf = new SparkConf() //創建環境變量
.setMaster("local") //設置本地化處理
.setAppName("pic") //設定名稱
val sc = new SparkContext(conf)
def main(args: Array[String]) {
val data = sc.textFile("./src/main/spark/clustering/pic.txt")
val similarities = data.map { line =>
val parts = line.split(" ")
(parts(0).toLong, parts(1).toLong, parts(2).toDouble)
}
val pic = new PowerIterationClustering()
.setK(2) //設置聚類數
.setMaxIterations(10) //設置迭代次數
val model = pic.run(similarities)
model.assignments.foreach {a =>
println(s"${a.id} -> ${a.cluster}")
}
}
}pic.txt
0 1 1.0 0 2 1.0 0 3 1.0 1 2 1.0 1 3 1.0 2 3 1.0 3 4 0.1 4 5 1.0 4 15 1.0 5 6 1.0 6 7 1.0 7 8 1.0 8 9 1.0 9 10 1.0 10 11 1.0 11 12 1.0 12 13 1.0 13 14 1.0 14 15 1.0
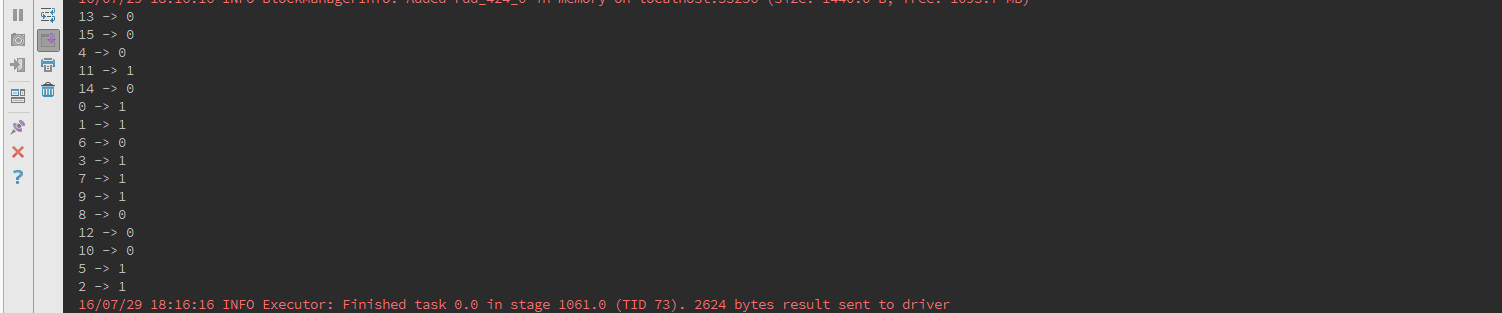
看完了這篇文章,相信你對“spark mllib如何實現快速迭代聚類”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





