溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Hive中AVRO數據存儲格式的示例分析,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
Avro(讀音類似于[?vr?])是Hadoop的一個子項目,由Hadoop的創始人Doug Cutting(也是Lucene,Nutch等項目的創始人,膜拜)牽頭開發,當前最新版本1.3.3。Avro是一個數據序列化系統,設計用于支持大批量數據交換的應用。它的主要特點有:支持二進制序列化方式,可以便捷,快速地處理大量數據;動態語言友好,Avro提供的機制使動態語言可以方便地處理Avro數據。
當前市場上有很多類似的序列化系統,如Google的Protocol Buffers, Facebook的Thrift。這些系統反響良好,完全可以滿足普通應用的需求。針對重復開發的疑惑,Doug Cutting撰文解釋道:Hadoop現存的RPC系統遇到一些問題,如性能瓶頸(當前采用IPC系統,它使用Java自帶的DataOutputStream和DataInputStream);需要服務器端和客戶端必須運行相同版本的Hadoop;只能使用Java開發等。但現存的這些序列化系統自身也有毛病,以Protocol Buffers為例,它需要用戶先定義數據結構,然后根據這個數據結構生成代碼,再組裝數據。如果需要操作多個數據源的數據集,那么需要定義多套數據結構并重復執行多次上面的流程,這樣就不能對任意數據集做統一處理。其次,對于Hadoop中Hive和Pig這樣的腳本系統來說,使用代碼生成是不合理的。并且Protocol Buffers在序列化時考慮到數據定義與數據可能不完全匹配,在數據中添加注解,這會讓數據變得龐大并拖慢處理速度。其它序列化系統有如Protocol Buffers類似的問題。所以為了Hadoop的前途考慮,Doug Cutting主導開發一套全新的序列化系統,這就是Avro,于09年加入Hadoop項目族中。
上面通過與Protocol Buffers的對比,大致清楚了Avro的特長。下面著重關注Avro的細節部分。
Avro依賴模式(Schema)來實現數據結構定義。可以把模式理解為Java的類,它定義每個實例的結構,可以包含哪些屬性。可以根據類來產生任意多個實例對象。對實例序列化操作時必須需要知道它的基本結構,也就需要參考類的信息。這里,根據模式產生的Avro對象類似于類的實例對象。每次序列化/反序列化時都需要知道模式的具體結構。所以,在Avro可用的一些場景下,如文件存儲或是網絡通信,都需要模式與數據同時存在。Avro數據以模式來讀和寫(文件或是網絡),并且寫入的數據都不需要加入其它標識,這樣序列化時速度快且結果內容少。由于程序可以直接根據模式來處理數據,所以Avro更適合于腳本語言的發揮。 不是列存儲,而是一種序列化的方式而已。
Avro的模式主要由JSON對象來表示,它可能會有一些特定的屬性,用來描述某種類型(Type)的不同形式。Avro支持八種基本類型(Primitive Type)和六種混合類型(Complex Type)。基本類型可以由JSON字符串來表示。每種不同的混合類型有不同的屬性(Attribute)來定義,有些屬性是必須的,有些是可選的,如果需要的話,可以用JSON數組來存放多個JSON對象定義。在這幾種Avro定義的類型的支持下,可以由用戶來創造出豐富的數據結構來,支持用戶紛繁復雜的數據。
Avro支持兩種序列化編碼方式:二進制編碼和JSON編碼。使用二進制編碼會高效序列化,并且序列化后得到的結果會比較小;而JSON一般用于調試系統或是基于WEB的應用。對Avro數據序列化/反序列化時都需要對模式以深度優先(Depth-First),從左到右(Left-to-Right)的遍歷順序來執行。基本類型的序列化容易解決,混合類型的序列化會有很多不同規則。對于基本類型和混合類型的二進制編碼在文檔中規定,按照模式的解析順序依次排列字節。對于JSON編碼,聯合類型(Union Type)就與其它混合類型表現不一致。
Avro為了便于MapReduce的處理定義了一種容器文件格式(Container File Format)。這樣的文件中只能有一種模式,所有需要存入這個文件的對象都需要按照這種模式以二進制編碼的形式寫入。對象在文件中以塊(Block)來組織,并且這些對象都是可以被壓縮的。塊和塊之間會存在同步標記符(Synchronization Marker),以便MapReduce方便地切割文件用于處理。下圖是根據文檔描述畫出的文件結構圖:
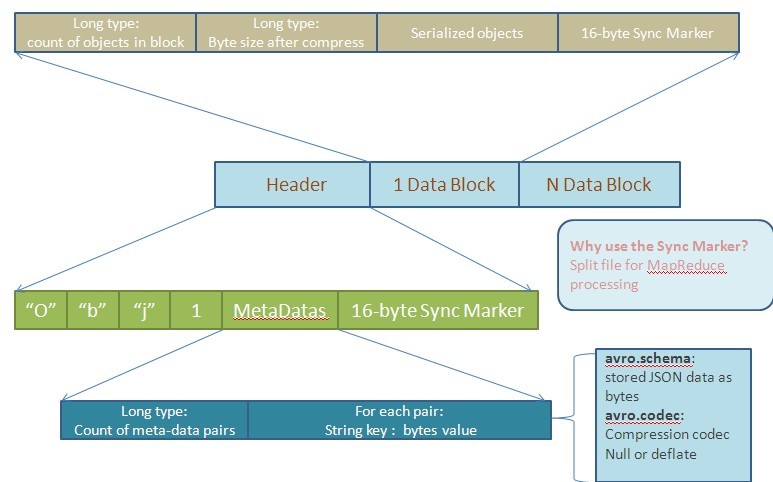
上圖已經對各塊做肢解操作,但還是有必要再詳細說明下。一個存儲文件由兩部分組成:頭信息(Header)和數據塊(Data Block)。而頭信息又由三部分構成:四個字節的前綴(類似于Magic Number),文件Meta-data信息和隨機生成的16字節同步標記符。這里的Meta-data信息讓人有些疑惑,它除了文件的模式外,還能包含什么。文檔中指出當前Avro認定的就兩個Meta-data:schema和codec。這里的codec表示對后面的文件數據塊(File Data Block)采用何種壓縮方式。Avro的實現都需要支持下面兩種壓縮方式:null(不壓縮)和deflate(使用Deflate算法壓縮數據塊)。除了文檔中認定的兩種Meta-data,用戶還可以自定義適用于自己的Meta-data。這里用long型來表示有多少個Meta-data數據對,也是讓用戶在實際應用中可以定義足夠的Meta-data信息。對于每對Meta-data信息,都有一個string型的key(需要以“avro.”為前綴)和二進制編碼后的value。對于文件中頭信息之后的每個數據塊,有這樣的結構:一個long值記錄當前塊有多少個對象,一個long值用于記錄當前塊經過壓縮后的字節數,真正的序列化對象和16字節長度的同步標記符。由于對象可以組織成不同的塊,使用時就可以不經過反序列化而對某個數據塊進行操作。還可以由數據塊數,對象數和同步標記符來定位損壞的塊以確保數據完整性。
上面是將Avro對象序列化到文件的操作。與之相應的,Avro也被作為一種RPC框架來使用。客戶端希望同服務器端交互時,就需要交換雙方通信的協議,它類似于模式,需要雙方來定義,在Avro中被稱為消息(Message)。通信雙方都必須保持這種協議,以便于解析從對方發送過來的數據,這也就是傳說中的握手階段。
消息從客戶端發送到服務器端需要經過傳輸層(Transport Layer),它發送消息并接收服務器端的響應。到達傳輸層的數據就是二進制數據。通常以HTTP作為傳輸模型,數據以POST方式發送到對方去。在Avro中,它的消息被封裝成為一組緩沖區(Buffer),類似于下圖的模型:
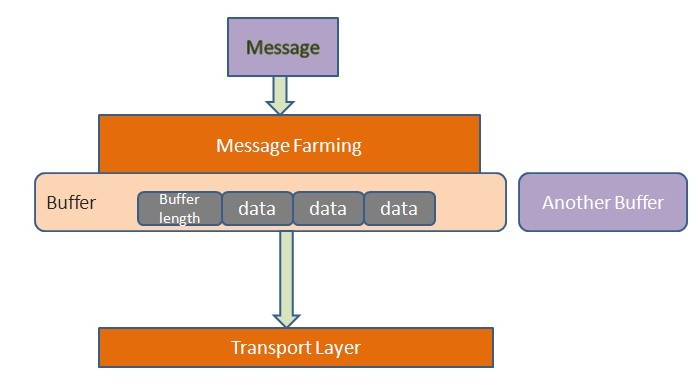
如上圖,每個緩沖區以四個字節開頭,中間是多個字節的緩沖數據,最后以一個空緩沖區結尾。這種機制的好處在于,發送端在發送數據時可以很方便地組裝不同數據源的數據,接收方也可以將數據存入不同的存儲區。還有,當往緩沖區中寫數據時,大對象可以獨占一個緩沖區,而不是與其它小對象混合存放,便于接收方方便地讀取大對象。
下面聊下Avro的其它方面信息。前文中引述Doug Cutting的話說,Protocol Buffer在傳輸數據時,往數據中加入注釋(annotation),以應對數據結構與數據不匹配的問題。但直接導致數據量變大,解析困難等缺點。那Avro是如何應對模式與數據的不同呢?為了保證Avro的高效,假定模式至少大部分是匹配的,然后定義一些驗證規則,如果在規則滿足的前提下,做數據驗證。如果模式不匹配就會報錯。相同模式,交互數據時,如果數據中缺少某個域(field),用規范中的默認值設置;如果數據中多了些與模式不匹配的數據。則忽視這些值。
Avro列出的優點中還有一項是:可排序的。就是說,一種語言支持的Avro程序在序列化數據后,可由其它語言的Avro程序對未反序列化的數據排序。我不知道這種機制是在什么樣的場景下使用,但看起來還是挺不錯的。
轉帖:http://langyu.iteye.com/blog/708568
在hive中實現avro存儲非常簡單。https://cwiki.apache.org/confluence/display/Hive/AvroSerDe 里面有非常詳細的介紹
高版本的hive,可以直接使用avro格式存儲,而不需要手動指定avro的schema文件,hive自己會根據table的創建方式自行解析并將schema存儲到文件的頭部。
create table kst(
> name string,age int
> ) stored as avro;
之后,通過手段將數據導入到kst表中,1)通過其他表select insert into,2)通過其他程序生成avro格式的數據,并load到hive表中,或者add partition進去也可以。
第一種方式:
from (select * from stus) base insert into kst select *;
之后,可以查看hive最終生成的數據。
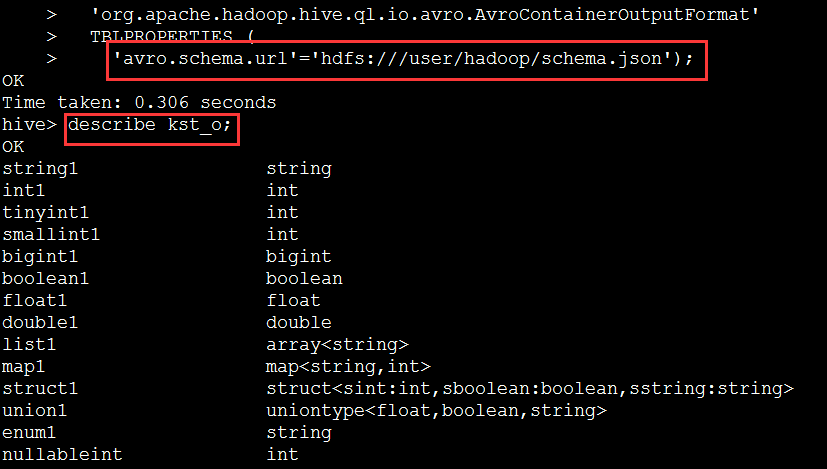
可以看到,自動生成了表。
2)創建表的時候,schema直接寫在table中(Use schema.literal and embed the schema in the create statement)
CREATE EXTERNAL TABLE tweets
COMMENT "A table backed by Avro data with the
Avro schema embedded in the CREATE TABLE statement"
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/user/wyp/examples/input/'
TBLPROPERTIES (
'avro.schema.literal'='{
"type": "record",
"name": "Tweet",
"namespace": "com.miguno.avro",
"fields": [
{ "name":"username", "type":"string"},
{ "name":"tweet", "type":"string"},
{ "name":"timestamp", "type":"long"}
]
}'
);

3)通過hive腳本(Use avro.schema.literal and pass the schema into the script)
Hive can do simple variable substitution and you can pass the schema embedded in a variable to the script. Note that to do this, the schema must be completely escaped (carriage returns converted to \n, tabs to \t, quotes escaped, etc). An example:
|
To execute this script file, assuming $SCHEMA has been defined to be the escaped schema value:
|
Note that $SCHEMA is interpolated into the quotes to correctly handle spaces within the schema.
最后,即使額外指定sechema自動生成表,那么最終的schema也寫入到最后生成的文件中。
看完了這篇文章,相信你對“Hive中AVRO數據存儲格式的示例分析”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





