溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
hadoop調優參數及原理是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
問題導讀:
1.map會將已經產生的部分結果先寫入到該buffer中.buffer大小可以通過那個參數來設置?
2.如何降低map的split的次數?
3.map中的數據什么情況下會寫入磁盤?spill是什么?
4.map其實是當buffer被寫滿到一定程度(比如80%)時,就開始進行spill有由那個參數來決定?
5.通過哪個參數可以控制map中間結果是否使用壓縮的?
6.reduce包含幾個階段,是每個reduce都必須包含?
7.Reduce task在做shuffle的過程是什么樣子的?如何調整多個并行map個數的下載?
8.reduce的數據是否全部來源磁盤,如何調整使用內存?
1 Map side tuning參數1.1 MapTask運行內部原理
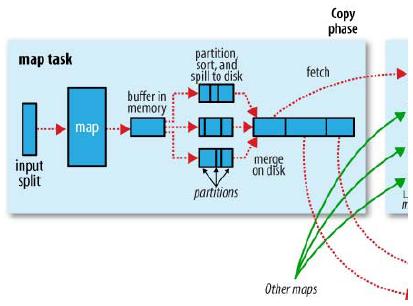
1.當map task開始運算,并產生中間數據時,其產生的中間結果并非直接就簡單的寫入磁盤。這中間的過程比較復雜,并且利用到了內存buffer來進行已經產生的部分結果的緩存,并在內存buffer中進行一些預排序來優化整個map的性能。如上圖所示,每一個map都會對應存在一個內存buffer(MapOutputBuffer,即上圖的buffer in memory),map會將已經產生的部分結果先寫入到該buffer中,這個buffer默認是100MB大小,但是這個大小是可以根據job提交時的參數設定來調整的,
該參數即為:mapreduce.task.io.sort.mb。
當map的產生數據非常大時,并且把mapreduce.task.io.sort.mb調大,那么map在整個計算過程中spill的次數就勢必會降低,map task對磁盤的操作就會變少,
如果map tasks的瓶頸在磁盤上,這樣調整就會大大提高map的計算性能。
map做sort和spill的內存結構如下如所示:
2.map在運行過程中,不停的向該buffer中寫入已有的計算結果,但是該buffer并不一定能將全部的map輸出緩存下來,當map輸出超出一定閾值(比如100M),那么map就必須將該buffer中的數據寫入到磁盤中去,這個過程在mapreduce中叫做spill。map并不是要等到將該buffer全部寫滿時才進行spill,因為如果全部寫滿了再去寫spill,勢必會造成map的計算部分等待buffer釋放空間的情況。所以,map其實是當buffer被寫滿到一定程度(比如80%)時,就開始進行spill。
這個閾值也是由一個job的配置參數來控制,
即mapreduce.map.sort.spill.percent,默認為0.80或80%。
這個參數同樣也是影響spill頻繁程度,進而影響map task運行周期對磁盤的讀寫頻率的。但非特殊情況下,通常不需要人為的調整。調整mapreduce.task.io.sort.mb對用戶來說更加方便。
3.當map task的計算部分全部完成后,如果map有輸出,就會生成一個或者多個spill文件,這些文件就是map的輸出結果。map在正常退出之前(cleanup),需要將這些spill合并(merge)成一個,所以map在結束之前還有一個merge的過程。merge的過程中,有一個參數可以調整這個過程的行為,該參數為:mapreduce.task.io.sort.factor。該參數默認為10。它表示當merge spill文件時,最多能有多少并行的stream向merge文件中寫入。比如如果map產生的數據非常的大,產生的spill文件大于10,而mapreduce.task.io.sort.factor使用的是默認的10,那么當map計算完成做merge時,就沒有辦法一次將所有的spill文件merge成一個,而是會分多次,每次最多10個stream。這也就是說,當map的中間結果非常大,調大mapreduce.task.io.sort.factor,有利于減少merge次數,進而減少map對磁盤的讀寫頻率,有可能達到優化作業的目的。
4.當job指定了combiner的時候,我們都知道map介紹后會在map端根據combiner定義的函數將map結果進行合并。運行combiner函數的時機有可能會是merge完成之前,或者之后,這個時機可以由一個參數控制,即mapreduce.map.combine.minspills(default 3),當job中設定了combiner,并且spill數大于等于3的時候,那么combiner函數就會在merge產生結果文件之前運行。通過這樣的方式,就可以在spill非常多需要merge,并且很多數據需要做conbine的時候,減少寫入到磁盤文件的數據數量,同樣是為了減少對磁盤的讀寫頻率,有可能達到優化作業的目的。
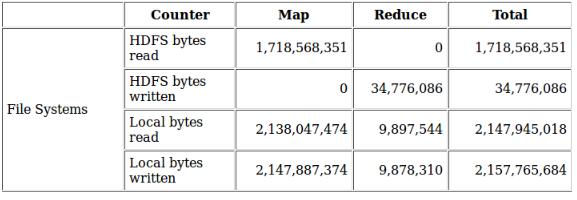
5.減少中間結果讀寫進出磁盤的方法不止這些,還有就是壓縮。也就是說map的中間,無論是spill的時候,還是最后merge產生的結果文件,都是可以壓縮的。壓縮的好處在于,通過壓縮減少寫入讀出磁盤的數據量。對中間結果非常大,磁盤速度成為map執行瓶頸的job,尤其有用。控制map中間結果是否使用壓縮的參數為:mapreduce.map.output.compress(true/false)。 將這個參數設置為true時,那么map在寫中間結果時,就會將數據壓縮后再寫入磁盤,讀結果時也會采用先解壓后讀取數據。這樣做的后果就是:寫入磁盤的 中間結果數據量會變少,但是cpu會消耗一些用來壓縮和解壓。所以這種方式通常適合job中間結果非常大,瓶頸不在cpu,而是在磁盤的讀寫的情況。說的 直白一些就是用cpu換IO。根據觀察,通常大部分的作業cpu都不是瓶頸,除非運算邏輯異常復雜。所以對中間結果采用壓縮通常來說是有收益的。以下是一 個wordcount中間結果采用壓縮和不采用壓縮產生的map中間結果本地磁盤讀寫的數據量對比:
map中間結果不壓縮:
map中間結果壓縮:
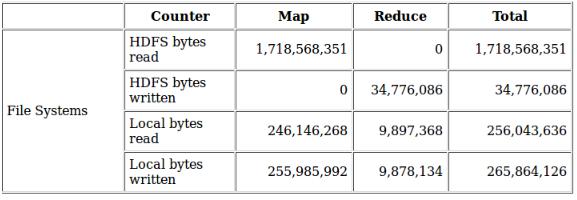
可以看出,同樣的job,同樣的數據,在采用壓縮的情況下,map中間結果能縮小將近10倍,如果map的瓶頸在磁盤,那么job的性能提升將會非常可觀。
當采用map中間結果壓縮的情況下,用戶還可以選擇壓縮時采用哪種壓縮格式進行壓縮,現在hadoop支持的壓縮格式有:GzipCodec,LzoCodec,BZip2Codec,LzmaCodec等壓縮格式。通常來說,想要達到比較平衡的cpu和磁盤壓縮比,LzoCodec比較適合。但也要取決于job的具體情況。用戶若想要自行選擇中間結果的壓縮算法,可以設置配置參數:mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.DefaultCodec或者其他用戶自行選擇的壓縮方式。
1.2 Map side相關參數調優
| 選項 | 類型 | 默認值 | 描述 |
| mapreduce.task.io.sort.mb | int | 100 | 緩存map中間結果的buffer大小(in MB) |
| io.sort.record.percent | float | 0.05 | io.sort.mb中用來保存map output記錄邊界的百分比,其他緩存用來保存數據 |
| io.sort.spill.percent mapreduce.map.sort.spill.percent | float | 0.80 | map開始做spill操作的閾值 |
| io.sort.factor mapreduce.task.io.sort.factor | int | 10 | 做merge操作時同時操作的stream數上限。 |
| min.num.spill.for.combine | int | 3 | combiner函數運行的最小spill數 |
| mapred.compress.map.output | boolean | false | map中間結果是否采用壓縮 |
| mapred.map.output.compression.codec | class name | org.apache.hadoop.io. compress.DefaultCodec | map中間結果的壓縮格式 |
2 Reduce side tuning參數2.1 ReduceTask運行內部原理
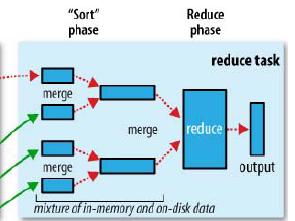
1.reduce的運行是分成三個階段的。分別為copy->sort->reduce。由于job的每一個map都會根據reduce(n)數將數據分成map 輸出結果分成n個partition,所以map的中間結果中是有可能包含每一個reduce需要處理的部分數據的。所以,為了優化reduce的執行時間,hadoop中是等job的第一個map結束后,所有的reduce就開始嘗試從完成的map中下載該reduce對應的partition部分數據。這個過程就是通常所說的shuffle,也就是copy過程。
2.Reduce task在做shuffle時,實際上就是從不同的已經完成的map上去下載屬于自己這個reduce的部分數據,由于map通常有許多個,所以對一個reduce來說,下載也可以是并行的從多個map下載,這個并行度是可以調整的,調整參數為:mapreduce.reduce.shuffle.parallelcopies(default 5)。默 認情況下,每個只會有5個并行的下載線程在從map下數據,如果一個時間段內job完成的map有100個或者更多,那么reduce也最多只能同時下載 5個map的數據,所以這個參數比較適合map很多并且完成的比較快的job的情況下調大,有利于reduce更快的獲取屬于自己部分的數據。
3.reduce 的每一個下載線程在下載某個map數據的時候,有可能因為那個map中間結果所在機器發生錯誤,或者中間結果的文件丟失,或者網絡瞬斷等等情況,這樣 reduce的下載就有可能失敗,所以reduce的下載線程并不會無休止的等待下去,當一定時間后下載仍然失敗,那么下載線程就會放棄這次下載,并在隨 后嘗試從另外的地方下載(因為這段時間map可能重跑)。所以reduce下載線程的這個最大的下載時間段是可以調整的,調整參數為:mapred.reduce.copy.backoff(default 300秒)。如果集群環境的網絡本身是瓶頸,那么用戶可以通過調大這個參數來避免reduce下載線程被誤判為失敗的情況。不過在網絡環境比較好的情況下,沒有必要調整。通常來說專業的集群網絡不應該有太大問題,所以這個參數需要調整的情況不多。
4.Reduce將map結果下載到本地時,同樣也是需要進行merge的,所以mapreduce.task.io.sort.factor的配置選項同樣會影響reduce進行merge時的行為,該參數的詳細介紹上文已經提到,當發現reduce在shuffle階段iowait非常的高的時候,就有可能通過調大這個參數來加大一次merge時的并發吞吐,優化reduce效率。
5.Reduce在shuffle階段對下載來的map數據,并不是立刻就寫入磁盤的,而是會先緩存在內存中,然后當使用內存達到一定量的時候才刷入磁盤。這個內存大小的控制就不像map一樣可以通過mapreduce.task.io.sort.mb來設定了,而是通過另外一個參數來設置:mapreduce.reduce.shuffle.input.buffer.percent(default 0.7),這個參數其實是一個百分比,意思是說,shuffile在reduce內存中的數據最多使用內存量為:0.7 × maxHeap of reduce task。也就是說,如果該reduce task的最大heap使用量(通常通過mapreduce.reduce.java.opts來設置,比如設置為-Xmx1024m)的一定比例用來緩存數據。默認情況下,reduce會使用其heapsize的70%來在內存中緩存數據。如果reduce的heap由于業務原因調整的比較大,相應的緩存大小也會變大,這也是為什么reduce用來做緩存的參數是一個百分比,而不是一個固定的值了。
6.假設mapreduce.reduce.shuffle.input.buffer.percent為0.7,reduce task的max heapsize為1G,那么用來做下載數據緩存的內存就為大概700MB左右,這700M的內存,跟map端一樣,也不是要等到全部寫滿才會往磁盤刷的,而是當這700M中被使用到了一定的限度(通常是一個百分比),就會開始往磁盤刷。這個限度閾值也是可以通過job參數來設定的,設定參數為:mapreduce.reduce.shuffle.merge.percent(default 0.66)。如果下載速度很快,很容易就把內存緩存撐大,那么調整一下這個參數有可能會對reduce的性能有所幫助。
7.當reduce將所有的map上對應自己partition的數據下載完成后,就會開始真正的reduce計算階段(中間有個sort階段通常時間非常短,幾秒鐘就完成了,因為整個下載階段就已經是邊下載邊sort,然后邊merge的)。當reduce task真正進入reduce函數的計算階段的時候,有一個參數也是可以調整reduce的計算行為。也就是:mapreduce.reduce.input.buffer.percent(default 0.0)。 由于reduce計算時肯定也是需要消耗內存的,而在讀取reduce需要的數據時,同樣是需要內存作為buffer,這個參數是控制,需要多少的內存百 分比來作為reduce讀已經sort好的數據的buffer百分比。默認情況下為0,也就是說,默認情況下,reduce是全部從磁盤開始讀處理數據。 如果這個參數大于0,那么就會有一定量的數據被緩存在內存并輸送給reduce,當reduce計算邏輯消耗內存很小時,可以分一部分內存用來緩存數據, 反正reduce的內存閑著也是閑著。
2.2 Reduce side相關參數調優
| 選項 | 類型 | 默認值 | 描述 |
| mapred.reduce.parallel.copies | int | 5 | 每個reduce并行下載map結果的最大線程數 |
| mapred.reduce.copy.backoff | int | 300 | reduce下載線程最大等待時間(in sec) |
| io.sort.factor | int | 10 | 同上 |
| mapred.job.shuffle.input.buffer.percent | float | 0.7 | 用來緩存shuffle數據的reduce task heap百分比 |
| mapred.job.shuffle.merge.percent | float | 0.66 | 緩存的內存中多少百分比后開始做merge操作 |
| mapred.job.reduce.input.buffer.percent | float | 0.0 | sort完成后reduce計算階段用來緩存數據的百分比 |
看完上述內容,你們掌握hadoop調優參數及原理是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





