溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“JVM常用參數調優方法是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
對于調優這個事情來說,一般就是三個過程:
性能監控:問題沒有發生,你并不知道你需要調優什么。此時需要一些系統、應用的監控工具來發現問題。
性能分析:問題已經發生,但是你并不知道問題到底出在哪里。此時就需要使用工具、經驗對系統、應用進行瓶頸分析,以求定位到問題原因。
性能調優:經過上一步的分析定位到了問題所在,需要對問題進行解決,使用代碼、配置等手段進行優化。
Java調優也不外乎這三步。
此外,本文所講的性能分析、調優等是拋開以下因素的:
系統底層環境:硬件、操作系統等
數據結構和算法的使用
外部系統如數據庫、緩存的使用
調優是需要做好準備工作的,畢竟每一個應用的業務目標都不盡相同,性能瓶頸也不會總在同一個點上。在業務應用層面,我們需要:
需要了解系統的總體架構,明確壓力方向。比如系統的哪一個接口、模塊是使用率最高的,面臨高并發的挑戰。
需要構建測試環境來測試應用的性能,使用ab、loadrunner、jmeter都可以。
對關鍵業務數據量進行分析,這里主要指的是對一些數據的量化分析,如數據庫一天的數據量有多少;緩存的數據量有多大等
了解系統的響應速度、吞吐量、TPS、QPS等指標需求,比如秒殺系統對響應速度和QPS的要求是非常高的。
了解系統相關軟件的版本、模式和參數等,有時候限于應用依賴服務的版本、模式等,性能也會受到一定的影響。
在系統層面能夠影響應用性能的一般包括三個因素:CPU、內存和IO,可以從這三方面進行程序的性能瓶頸分析。
當程序響應變慢的時候,首先使用top、vmstat、ps等命令查看系統的cpu使用率是否有異常,從而可以判斷出是否是cpu繁忙造成的性能問題。其中,主要通過us(用戶進程所占的%)這個數據來看異常的進程信息。當us接近100%甚至更高時,可以確定是cpu繁忙造成的響應緩慢。一般說來,cpu繁忙的原因有以下幾個:
線程中有無限空循環、無阻塞、正則匹配或者單純的計算
發生了頻繁的gc
多線程的上下文切換
確定好cpu使用率最高的進程之后就可以使用jstack來打印出異常進程的堆棧信息:
jstack [pid]
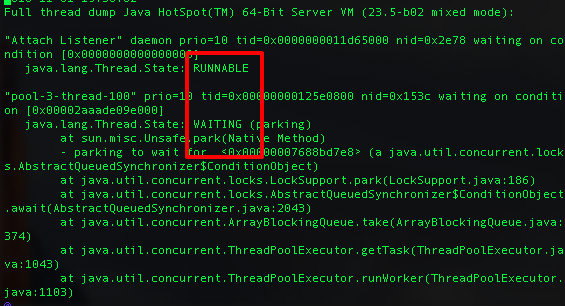
接下來需要注意的一點是,Linux下所有線程最終還是以輕量級進程的形式存在系統中的,而使用jstack只能打印出進程的信息,這些信息里面包含了此進程下面所有線程(輕量級進程-LWP)的堆棧信息。因此,進一步的需要確定是哪一個線程耗費了大量CPU,此時可以使用top -p [processId] -H來查看,也可以直接通過ps -Le來顯示所有進程,包括LWP的資源耗費信息。最后,通過在jstack的輸出文件中查找對應的LWP的id即可以定位到相應的堆棧信息。其中需要注意的是線程的狀態:RUNNABLE、WAITING等。對于Runnable的進程需要注意是否有耗費cpu的計算。對于Waiting的線程一般是鎖的等待操作。
也可以使用jstat來查看對應進程的gc信息,以判斷是否是gc造成了cpu繁忙。
jstat -gcutil [pid]

還可以通過vmstat,通過觀察內核狀態的上下文切換(cs)次數,來判斷是否是上下文切換造成的cpu繁忙。
vmstat 1 5

此外,有時候可能會由jit引起一些cpu飚高的情形,如大量方法編譯等。這里可以使用-XX:+PrintCompilation這個參數輸出jit編譯情況,以排查jit編譯引起的cpu問題。
對Java應用來說,內存主要是由堆外內存和堆內內存組成。
堆外內存
堆外內存主要是JNI、Deflater/Inflater、DirectByteBuffer(nio中會用到)使用的。對于這種堆外內存的分析,還是需要先通過vmstat、sar、top、pidstat(這里的sar,pidstat以及iostat都是 sysstat軟件套件的一部分,需要單獨安裝)等查看swap和物理內存的消耗狀況再做判斷的。此外,對于JNI、Deflater這種調用可以通過 Google-preftools來追蹤資源使用狀況。
堆內內存
此部分內存為Java應用主要的內存區域。通常與這部分內存性能相關的有:
以上使用不當很容易造成:
排查堆內存問題的常用工具是jmap,是jdk自帶的。一些常用用法如下:
此外,不管是使用jmap還是在OOM時產生的dump文件,可以使用Eclipse的MAT(MEMORY ANALYZER TOOL)來分析,可以看到具體的堆棧和內存中對象的信息。當然jdk自帶的jhat也能夠查看dump文件(啟動web端口供開發者使用瀏覽器瀏覽堆內對象的信息)。此外,VisualVM也能夠打開hprof文件,使用它的heap walker查看堆內存信息。

查看jvm內存使用狀況:jmap -heap
查看jvm內存存活的對象:jmap -histo:live
把heap里所有對象都dump下來,無論對象是死是活:jmap -dump:format=b,file=xxx.hprof
先做一次full GC,再dump,只包含仍然存活的對象信息:jmap -dump:format=b,live,file=xxx.hprof
Heap space:堆內存不足
PermGen space:永久代內存不足
Native thread:本地線程沒有足夠內存可分配
頻繁GC -> Stop the world,使你的應用響應變慢
OOM,直接造成內存溢出錯誤使得程序退出。OOM又可以分為以下幾種:
創建的對象:這個是存儲在堆中的,需要控制好對象的數量和大小,尤其是大的對象很容易進入老年代
全局集合:全局集合通常是生命周期比較長的,因此需要特別注意全局集合的使用
緩存:緩存選用的數據結構不同,會很大程序影響內存的大小和gc
ClassLoader:主要是動態加載類容易造成永久代內存不足
多線程:線程分配會占用本地內存,過多的線程也會造成內存不足
通常與應用性能相關的包括:文件IO和網絡IO。
文件IO
可以使用系統工具pidstat、iostat、vmstat來查看io的狀況。這里可以看一張使用vmstat的結果圖。
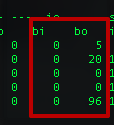
這里主要注意bi和bo這兩個值,分別表示塊設備每秒接收的塊數量和塊設備每秒發送的塊數量,由此可以判定io繁忙狀況。進一步的可以通過使用strace工具定位對文件io的系統調用。通常,造成文件io性能差的原因不外乎:
大量的隨機讀寫
設備慢
文件太大
網絡IO
查看網絡io狀況,一般使用的是netstat工具。可以查看所有連接的狀況、數目、端口信息等。例如:當time_wait或者close_wait連接過多時,會影響應用的相應速度。
netstat -anp
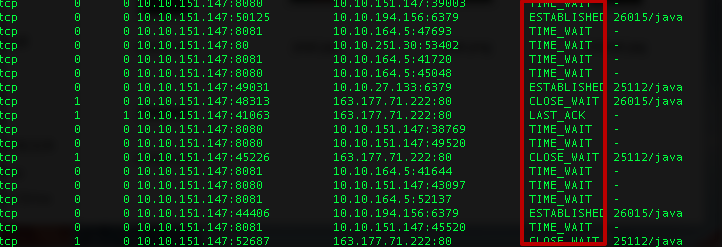
此外,還可以使用tcpdump來具體分析網絡io的數據。當然,tcpdump出的文件直接打開是一堆二進制的數據,可以使用wireshark閱讀具體的連接以及其中數據的內容。
tcpdump -i eth0 -w tmp.cap -tnn dst port 8080 #監聽8080端口的網絡請求并打印日志到tmp.cap中
還可以通過查看/proc/interrupts來獲取當前系統使用的中斷的情況。
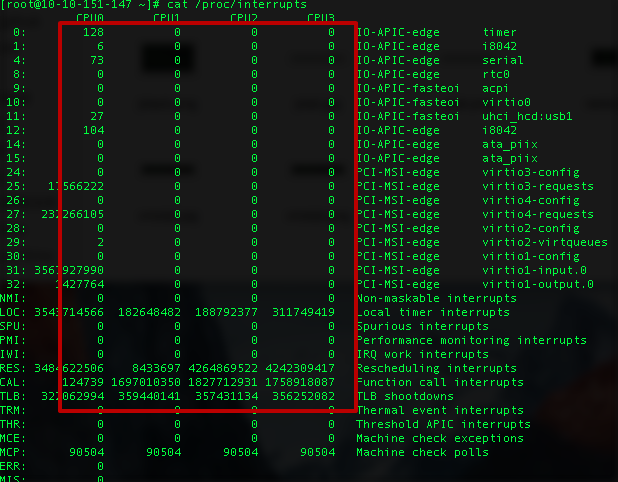
各個列依次是:
irq的序號, 在各自cpu上發生中斷的次數,可編程中斷控制器,設備名稱(request_irq的dev_name字段)
通過查看網卡設備的終端情況可以判斷網絡io的狀況。
上面分別針對CPU、內存以及IO講了一些系統/JDK自帶的分析工具。除此之外,還有一些綜合分析工具或者框架可以更加方便我們對Java應用性能的排查、分析、定位等。
VisualVM
這個工具應該是Java開發者們非常熟悉的一款java應用監測工具,原理是通過jmx接口來連接jvm進程,從而能夠看到jvm上的線程、內存、類等信息。
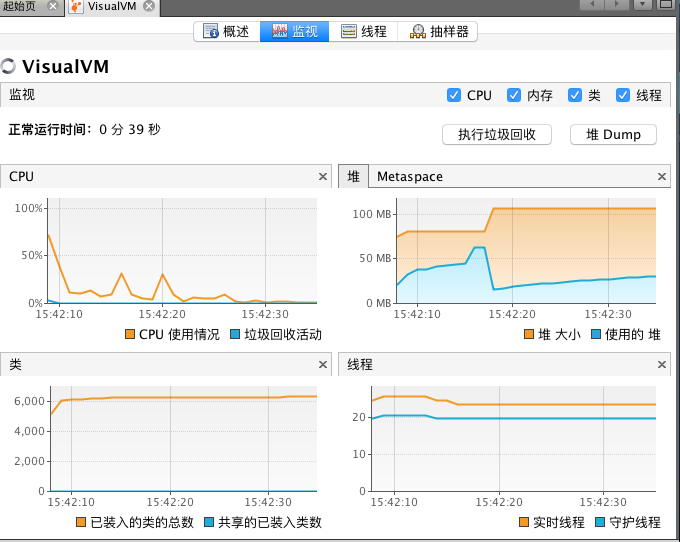 如果想進一步查看gc情況,可以安裝visual gc插件。此外,visualvm也有btrace的插件,可以可視化直觀的編寫btrace代碼并查看輸出日志。 與VisualVm類似的,jconsole也是通過jmx查看遠程jvm信息的一款工具,更進一步的,通過它還可以顯示具體的線程堆棧信息以及內存中各個年代的占用情況,也支持直接遠程執行MBEAN。當然,visualvm通過安裝jconsole插件也可以擁有這些功能。
如果想進一步查看gc情況,可以安裝visual gc插件。此外,visualvm也有btrace的插件,可以可視化直觀的編寫btrace代碼并查看輸出日志。 與VisualVm類似的,jconsole也是通過jmx查看遠程jvm信息的一款工具,更進一步的,通過它還可以顯示具體的線程堆棧信息以及內存中各個年代的占用情況,也支持直接遠程執行MBEAN。當然,visualvm通過安裝jconsole插件也可以擁有這些功能。
 但由于這倆工具都是需要ui界面的,因此一般都是通過本地遠程連接服務器jvm進程。服務器環境下,一般并不用此種方式。
但由于這倆工具都是需要ui界面的,因此一般都是通過本地遠程連接服務器jvm進程。服務器環境下,一般并不用此種方式。
Java Mission Control(jmc)
此工具是jdk7 u40開始自帶的,原來是JRockit上的工具,是一款采樣型的集診斷、分析和監控與一體的非常強大的工具:
https://docs.oracle.com/javacomponents/jmc-5-5/jmc-user-guide/toc.htm。但是此工具是基于JFR(jcmd
Btrace
這里不得不提的是btrace這個神器,它使用java attach api+ java agent + instrument api能夠實現jvm的動態追蹤。在不重啟應用的情況下可以加入攔截類的方法以打印日志等。具體的用法可以參考 Btrace入門到熟練小工完全指南。
Jwebap
Jwebap是一款JavaEE性能檢測框架,基于asm增強字節碼實現。支持:http請求、jdbc連接、method的調用軌跡跟蹤以及次數、耗時的統計。由此可以獲取最耗時的請求、方法,并可以查看jdbc連接的次數、是否關閉等。但此項目是2006年的一個項目,已經將近10年沒有更新。根據筆者使用,已經不支持jdk7編譯的應用。如果要使用,建議基于原項目二次開發,同時也可以加入對redis連接的軌跡跟蹤。當然,基于字節碼增強的原理,也可以實現自己的JavaEE性能監測框架。
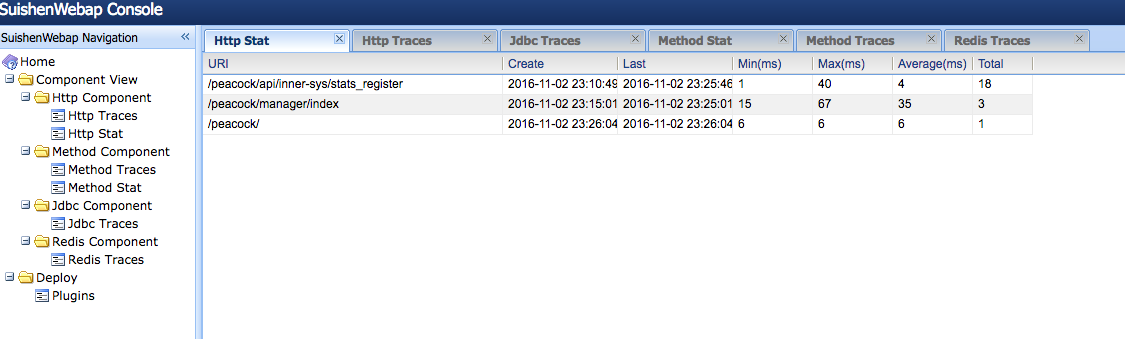
上圖來自筆者公司二次開發過的jwebap,已經支持jdk8和redis連接追蹤。
useful-scripts
這里有一個本人參與的開源的項目: https://github.com/superhj1987/useful-scripts,封裝了很多常用的性能分析命令,比如上文講的打印繁忙java線程堆棧信息,只需要執行一個腳本即可。
與性能分析相對應,性能調優同樣分為三部分。
不要存在一直運行的線程(無限while循環),可以使用sleep休眠一段時間。這種情況普遍存在于一些pull方式消費數據的場景下,當一次pull沒有拿到數據的時候建議sleep一下,再做下一次pull。
輪詢的時候可以使用wait/notify機制
避免循環、正則表達式匹配、計算過多,包括使用String的format、split、replace方法(可以使用apache的commons-lang里的StringUtils對應的方法),使用正則去判斷郵箱格式(有時候會造成死循環)、序列/反序列化等。
結合jvm和代碼,避免產生頻繁的gc,尤其是full GC。
此外,使用多線程的時候,還需要注意以下幾點:
使用線程池,減少線程數以及線程的切換
多線程對于鎖的競爭可以考慮減小鎖的粒度(使用ReetrantLock)、拆分鎖(類似ConcurrentHashMap分bucket上鎖), 或者使用CAS、ThreadLocal、不可變對象等無鎖技術。此外,多線程代碼的編寫最好使用jdk提供的并發包、Executors框架以及ForkJoin等,此外 Discuptor和 Actor在合適的場景也可以使用。
內存的調優主要就是對jvm的調優。
合理設置各個代的大小。避免新生代設置過小(不夠用,經常minor gc并進入老年代)以及過大(會產生碎片),同樣也要避免Survivor設置過大和過小。
選擇合適的GC策略。需要根據不同的場景選擇合適的gc策略。這里需要說的是,cms并非全能的。除非特別需要再設置,畢竟cms的新生代回收策略parnew并非最快的,且cms會產生碎片。此外,G1直到jdk8的出現也并沒有得到廣泛應用,并不建議使用。
jvm啟動參數配置-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:[log_path],以記錄gc日志,便于排查問題。
其中,對于第一點,具體的還有一點建議:
年輕代大小選擇:響應時間優先的應用,盡可能設大,直到接近系統的最低響應時間限制(根據實際情況選擇)。在此種情況下,年輕代收集發生gc的頻率是最小的。同時,也能夠減少到達年老代的對象。吞吐量優先的應用,也盡可能的設置大,因為對響應時間沒有要求,垃圾收集可以并行進行,建議適合8CPU以上的應用使用。
年老代大小選擇:響應時間優先的應用,年老代一般都是使用并發收集器,所以其大小需要小心設置,一般要考慮并發會話率和會話持續時間等一些參數。如果堆設置小了,會造成內存碎片、高回收頻率以及應用暫停而使用傳統的標記清除方式;如果堆大了,則需要較長的收集時間。最優化的方案,一般需要參考以下數據獲得:
一般吞吐量優先的應用都應該有一個很大的年輕代和一個較小的年老代。這樣可以盡可能回收掉大部分短期對象,減少中期的對象,而年老代存放長期存活對象。
并發垃圾收集信息
持久代并發收集次數
傳統GC信息
花在年輕代和年老代回收上的時間比例
此外,較小堆引起的碎片問題:因為年老代的并發收集器使用標記、清除算法,所以不會對堆進行壓縮。當收集器回收時,會把相鄰的空間進行合并,這樣可以分配給較大的對象。但是,當堆空間較小時,運行一段時間以后,就會出現“碎片”,如果并發收集器找不到足夠的空間,那么并發收集器將會停止,然后使用傳統的標記、清除方式進行回收。如果出現“碎片”,可能需要進行如下配置:-XX:+UseCMSCompactAtFullCollection,使用并發收集器時,開啟對年老代的壓縮。同時使用-XX:CMSFullGCsBeforeCompaction=xx設置多少次Full GC后,對年老代進行壓縮。
其余對于jvm的優化問題可見后面JVM參數進階一節。
代碼上,也需要注意:
避免保存重復的String對象,同時也需要小心String.subString()與String.intern()的使用,尤其是后者其底層數據結構為StringTable,當字符串大量不重復時,會使得StringTable非常大(一個固定大小的hashmap,可以由參數-XX:StringTableSize=N設置大小),從而影響young gc的速度。在jackson和fastjson中使用了此方法,某些場景下會引起gc問題: YGC越來越慢,為什么。
盡量不要使用finalizer
釋放不必要的引用:ThreadLocal使用完記得釋放以防止內存泄漏,各種stream使用完也記得close。
使用對象池避免無節制創建對象,造成頻繁gc。但不要隨便使用對象池,除非像連接池、線程池這種初始化/創建資源消耗較大的場景,
緩存失效算法,可以考慮使用SoftReference、WeakReference保存緩存對象
謹慎熱部署/加載的使用,尤其是動態加載類等
不要用Log4j輸出文件名、行號,因為Log4j通過打印線程堆棧實現,生成大量String。此外,使用log4j時,建議此種經典用法,先判斷對應級別的日志是否打開,再做操作,否則也會生成大量String。
if (logger.isInfoEnabled()) {
logger.info(msg);
}文件IO上需要注意:
考慮使用異步寫入代替同步寫入,可以借鑒redis的aof機制。
利用緩存,減少隨機讀
盡量批量寫入,減少io次數和尋址
使用數據庫代替文件存儲
網絡IO上需要注意:
和文件IO類似,使用異步IO、多路復用IO/事件驅動IO代替同步阻塞IO
批量進行網絡IO,減少IO次數
使用緩存,減少對網絡數據的讀取
使用協程: Quasar
算法、邏輯上是程序性能的首要,遇到性能問題,應該首先優化程序的邏輯處理
優先考慮使用返回值而不是異常表示錯誤
查看自己的代碼是否對內聯是友好的: 你的Java代碼對JIT編譯友好么?
此外,jdk7、8在jvm的性能上做了一些增強:
通過-XX:+TieredCompilation開啟JDK7的 多層編譯(tiered compilation)支持。多層編譯結合了客戶端C1編譯器和服務端C2編譯器的優點(客戶端編譯能夠快速啟動和及時優化,服務器端編譯可以提供更多的高級優化),是一個非常高效利用資源的切面方案。在開始時先進行低層次的編譯,同時收集信息,在后期再進一步進行高層次的編譯進行高級優化。需要注意的一點:這個參數會消耗比較多的內存資源,因為同一個方法被編譯了多次,存在多份native內存拷貝,建議把code cache調大一點兒(-XX:+ReservedCodeCacheSize,InitialCodeCacheSize)。否則有可能由于code cache不足,jit編譯的時候不停的嘗試清理code cache,丟棄無用方法,消耗大量資源在jit線程上。
Compressed Oops:壓縮指針在jdk7中的server模式下已經默認開啟。
Zero-Based Compressed Ordinary Object Pointers:當使用了上述的壓縮指針時,在64位jvm上,會要求操作系統保留從一個虛擬地址0開始的內存。如果操作系統支持這種請求,那么就開啟了Zero-Based Compressed Oops。這樣可以使得無須在java堆的基地址添加任何地址補充即可把一個32位對象的偏移解碼成64位指針。
逃逸分析(Escape Analysis): Server模式的編譯器會根據代碼的情況,來判斷相關對象的逃逸類型,從而決定是否在堆中分配空間,是否進行標量替換(在棧上分配原子類型局部變量)。此外,也可以根據調用情況來決定是否自動消除同步控制,如StringBuffer。這個特性從Java SE 6u23開始就默認開啟。
NUMA Collector Enhancements:這個重要針對的是The Parallel Scavenger垃圾回收器。使其能夠利用NUMA (Non Uniform Memory Access,即每一個處理器核心都有本地內存,能夠低延遲、高帶寬訪問) 架構的機器的優勢來更快的進行gc。可以通過-XX:+UseNUMA開啟支持。
此外,網上還有很多過時的建議,不要再盲目跟隨:
變量用完設置為null,加快內存回收,這種用法大部分情況下并沒有意義。一種情況除外:如果有個Java方法沒有被JIT編譯但里面仍然有代碼會執行比較長時間,那么在那段會執行長時間的代碼前顯式將不需要的引用類型局部變量置null是可取的。具體的可以見R大的解釋: https://www.zhihu.com/question/48059457/answer/113538171
方法參數設置為final,這種用法也沒有太大的意義,尤其在jdk8中引入了effective final,會自動識別final變量。
jvm的參數設置一直是比較理不清的地方,很多時候都搞不清都有哪些參數可以配置,參數是什么意思,為什么要這么配置等。這里主要針對這些做一些常識性的說明以及對一些容易讓人進入陷阱的參數做一些解釋。
以下所有都是針對Oracle/Sun JDK 6來講
啟動參數默認值
Java有很多的啟動參數,而且很多版本都并不一樣。但是現在網上充斥著各種資料,如果不加辨別的全部使用,很多是沒有效果或者本來就是默認值的。一般的,我們可以通過使用java -XX:+PrintFlagsInitial來查看所有可以設置的參數以及其默認值。也可以在程序啟動的時候加入-XX:+PrintCommandLineFlags來查看與默認值不相同的啟動參數。如果想查看所有啟動參數(包括和默認值相同的),可以使用-XX:+PrintFlagsFinal。


輸出里“=”表示使用的是初始默認值,而“:=”表示使用的不是初始默認值,可能是命令行傳進來的參數、配置文件里的參數或者是 ergonomics自動選擇了別的值。
此外,還可以使用jinfo命令顯示啟動的參數。
這里需要指出的是,當你配置jvm參數時,最好是先通過以上命令查看對應參數的默認值再確定是否需要設置。也最好不要配置你搞不清用途的參數,畢竟默認值的設置是有它的合理之處的。
jinfo -flags [pid] #查看目前啟動使用的有效參數
jinfo -flag [flagName] [pid] #查看對應參數的值
動態設置參數
當Java應用啟動后,定位到了是GC造成的性能問題,但是你啟動的時候并沒有加入打印gc的參數,很多時候的做法就是重新加參數然后重啟應用。但這樣會造成一定時間的服務不可用。最佳的做法是能夠在不重啟應用的情況下,動態設置參數。使用jinfo可以做到這一點(本質上還是基于jmx的)。
jinfo -flag [+/-][flagName] [pid] #啟用/禁止某個參數 jinfo -flag [flagName=value] [pid] #設置某個參數
對于上述的gc的情況,就可以使用以下命令打開heap dump并設置dump路徑。
jinfo -flag +HeapDumpBeforeFullGC [pid] jinfo -flag +HeapDumpAfterFullGC [pid] jinfo -flag HeapDumpPath=/home/dump/dir [pid]
同樣的也可以動態關閉。
jinfo -flag -HeapDumpBeforeFullGC [pid] jinfo -flag -HeapDumpAfterFullGC [pid]
其他的參數設置類似。
-verbose:gc 與 -XX:+PrintGCDetails
很多gc推薦設置都同時設置了這兩個參數,其實,只要打開了-XX:+PrintGCDetails,前面的選項也會同時打開,無須重復設置。
-XX:+DisableExplicitGC
這個參數的作用就是使得system.gc變為空調用,很多推薦設置里面都是建議開啟的。但是,如果你用到了NIO或者其他使用到堆外內存的情況,使用此選項會造成oom。可以用XX:+ExplicitGCInvokesConcurrent或XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses(配合CMS使用,使得system.gc觸發一次并發gc)代替。
此外,還有一個比較有意思的地方。如果你不設置此選項的話,當你使用了RMI的時候,會周期性地來一次full gc。這個現象是由于分布式gc造成的,為RMI服務。
此參數是設置的堆外內存的上限值。當不設置的時候為-1,此值為-Xmx減去一個survivor space的預留大小。
由于遺留原因,作用相同的參數
-Xss 與 -XX:ThreadStackSize
-Xmn 與 -XX:NewSize,此外這里需要注意的是設置了-Xmn的話,NewRatio就沒作用了。
-XX:MaxTenuringThreshold
使用工具查看此值默認值為15,但是選擇了CMS的時候,此值會變成4。當此值設置為0時,所有eden里的活對象在經歷第一次minor GC的時候就會直接晉升到old gen,survivor space直接就沒用。還有值得注意的一點,當使用并行回收器時,此值是沒有作用的,并行回收器默認是自動調整這些參數以求達到吞吐量最大的。此外,即使是使用CMS等回收器,晉升到老年代的age也不是不變的,當某一age的對象的大小達到年輕代的50%時,這個age會被動態調整為晉升年齡。
-XX:HeapDumpPath
使用此參數可以指定-XX:+HeapDumpBeforeFullGC、-XX:+HeapDumpAfterFullGC、-XX:+HeapDumpOnOutOfMemoryError觸發heap dump文件的存儲位置。
-XX:+UseAdaptiveSizePolicy
此參數在并行回收器時是默認開啟的,會根據應用運行狀況做自我調整,如MaxTenuringThreshold、survivor區大小等。其中第一次晉升老年代的年齡以InitialTenuringThreshold(默認為7)開始,后續會自動調整。如果希望跟蹤每次minor GC后新的存活周期的閾值,可在啟動參數上增加:-XX:+PrintTenuringDistribution。如果想要可以配置這些參數,可以關閉此選項,但paralle的性能很難達到最佳。其他垃圾回收期則慎重開啟此開關。
“JVM常用參數調優方法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





