溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Borg使用策略是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Borg的一個主要目的就是有效的利用Google的機器艦隊,這可是一大筆財務投資:讓效率提升幾個百分點就能省下幾百萬美元。
我們的job部署是有資源約束的,而且很少碰到負載高峰,我們的機器是異構的,我們從service job回收利用的資源跑batch job。所以,為了測量我們需要一個比“平均利用率”更抽象的標準。在做了一些實驗后我們選擇了cell密度(cell compaction):給定一個負載,我們不斷的從零開始(這樣可以避免被一個倒霉的配置卡住),部署到盡可能小的Cell里面去,直到再也不能從這個cell里面抽機器出來。這提供了一個清晰的終止條件,并促進了無陷阱的自動化比較,這里的陷阱指的是綜合化的工作負載和建模[31]。一個定量的比較和估算技術可以看[78],有不少微妙的細節。
我們不可能在線上的cell做性能實驗,所以我們用了Fauxmaster來達到高保真的模擬效果,使用了真的在線cell的負載數據包括所有的約束、實際限制、保留和常用數據($5.5)。這些數據從2014-10-1 14:00 PDT的Borg快照(checkpoints)里面提取出來。(其他快照也產生類似的結論)。我們選取了15個Borg cell來出報告,先排除了特殊目的的、測試的、小的(<5000機器)的cell,然后從剩下的各種量級大小的cell中平均取樣。
在壓縮cell實驗中為了保持機器異構性,我們隨機選擇去掉的機器。為了保持工作負載的異構性,我們保留了所有負載,除了那些對服務和存儲需要有特定需求的。我們把那些需要超過一半cell的job的硬限制改成軟的,允許不超過0.2%的task持續的pending如果它們過于挑剔機器;廣泛的測試表明這些結果是可重復的。如果我們需要一個大的cell,就把原cell復制擴大;如果我們需要更多的cell,就復制幾份cell。
所有的實驗都每個cell重復11次,用不同的隨機數發生器。在圖上,我們用一個橫線來表示最少和最多需要的機器,然后選擇90%這個位置作為結果,平均或者居中的結論不會代表一個系統管理員會做的最優選擇。我們相信cell壓縮提供了一個公平一致的方式去比較調度策略:好的策略只需要更少的機器來跑相同的負載。
我們的實驗聚焦在調度(打包)某個時間點的一個負載,而不是重放一段長期的工作蹤跡。這部分是因為復制一個開放和關閉的隊列模型比較困難,部分是因為傳統的一段時間內跑完的指標和我們環境的長期跑服務不一樣,部分是因為這樣比較起來比較明確,部分是因為我們相信怎么整都差不多,部分是因為我們在消費20萬個Borg CPU來做測試——即使在Google的量級,這也不是一個小數目(譯者:就你丫理由多!)
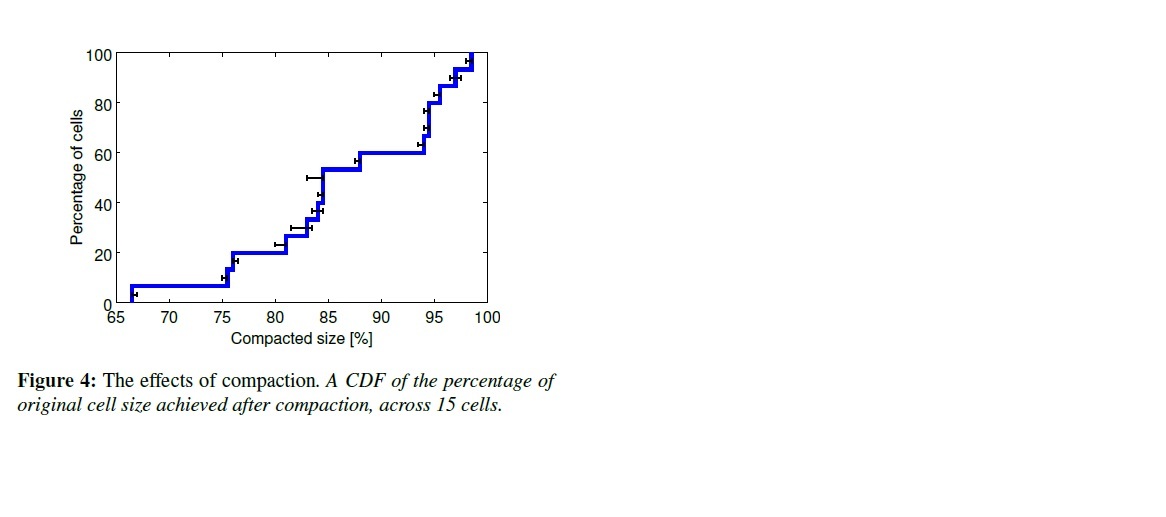
在生產環境下,我們謹慎的留下了一些頂部空間給負載的增加,比如一些“黑天鵝”時間,負載高峰,機器故障,硬件升級,以及大范圍故障(供電進灰)。圖4顯示了我們在現實世界中可以把cell壓縮到多小。上面的基線是用來表示壓縮大小的。
幾乎我們所有的機器都同時跑prod和non-prod的task:在共享Borg cell里有98%的機器同時跑這2種task,在所有Borg管理的機器里面有83%同時跑這2種task(我們有一些專用的Cell跑特定任務)。
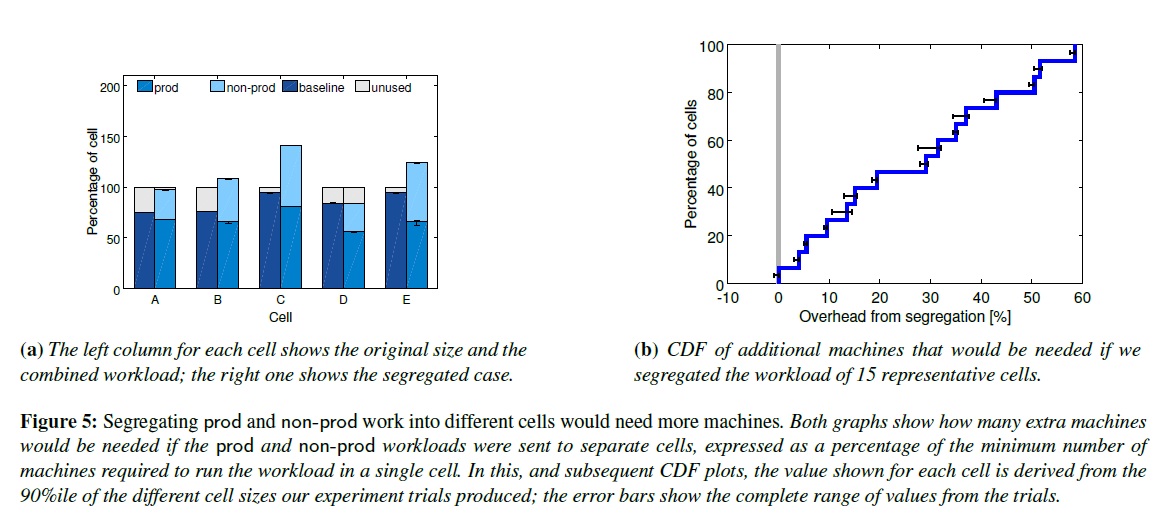
鑒于很多其他的組織把面向用戶應用和批處理應用在不同的集群上運行,我們設想一下如果我們也這么干會發生什么情況。圖5展現了在一個中等大小的Cell上分開跑我們prod和non-prod的工作負載將需要20-30%多的機器。這是因為prod的job通常會保留一些資源來應對極少發生的負載高峰,但實際上在大多情況下不會用這些資源。Borg把這批資源回收利用了($5.5)來跑很多non-prod的工作,所以最終我們只需要更少的機器。
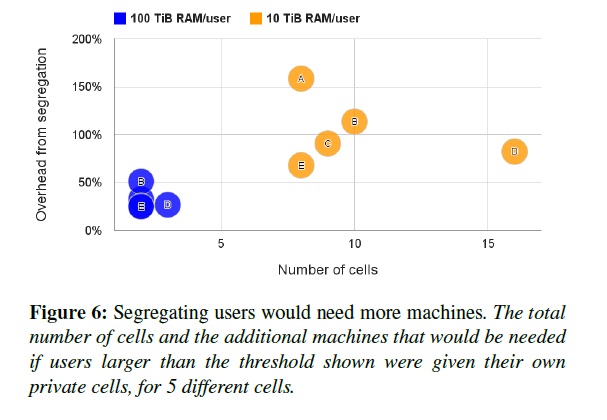
大部分Borg cell被幾千個用戶共享使用。圖6展現了為什么。對這個測試,如果一個用戶消費超過了10TiB內存(或100TiB),我們就把這個用戶的工作負載分離到一個單獨的Cell里面去。我們目前的策略展現了它的威力:即使我們設置了這么高的閾值(來分離),也需要2-16倍多的Cell,和20-150%多的機器。資源池的方案再次有效地節省了開銷。
但是,或許把很多不相關的用戶和job類型打包放到一臺機器上,會造成CPU沖突,然后就需要更多的機器進行補償?為了驗證這一點,我們看一下在同一臺機器,鎖定時鐘周期,每指令循環數CPI(cycles per instruction)在不同環境的task下是怎么變化的。在這種情況下,CPI是一個可比較的指標而且可以代表沖突度量,因為2倍的CPI意味著CPU密集型程序要跑2倍的時間。這些數據是從一周內12000個隨機的prod的task中獲取的,用硬件測量工具[83]取的,并且對采樣做了權重,這樣每秒CPU都是平等的。測試結果不是非常明顯。
我們發現CPI在同一個時間段內和下面兩個量正相關:這臺機器上總的CPU使用量,以及(強相關)這個機器上同時跑的task數量;每往一臺機器上增加1個task,就會增加0.3%的CPI(線性模型過濾數據);增加一臺10%的CPU使用率,就會增加小于2%的CPI。即使這已經是一個統計意義顯著的正相關性,也只是解釋了我們在CPI度量上看到的5%的變化,還有其他的因素支配著這個變化,例如應用程序固有的差別和特殊的干涉圖案[24,83]。
比較我們從共享Cell和少數只跑幾種應用的專用Cell獲取的CPI采樣,我們看到共享Cell里面的CPI平均值為1.58(σ=0.35,方差),專用Cell的CPI平均值是1.53(σ=0.32,方差).也就是說,共享Cell的性能差3%。
為了搞定不同Cell的應用會有不同的工作負載,或者會有幸存者偏差(或許對沖突更敏感的程序會被挪到專用Cell里面去),我們觀察了Borglet的CPI,在所有Cell的所有機器上都會被運行。我們發現專用Cell的CPI平均值是1.20(σ=0.29,方差),而共享Cell里面的CPI平均值為1.43(σ=0.45,方差),暗示了在專用Cell上運行程序會比在共享Cell上快1.19倍,這就超過了CPU使用量輕負載的這個因素,輕微的有利于專用Cell。
這些實驗確定了倉庫級別的性能測試是比較微妙的,加強了[51]中的觀察,并且得出了共享并沒有顯著的增加程序運行的開銷。
不過,就算我們假設用了我們結果中最不好的數據,共享還是有益的:比起CPU的降速,在各個方案里面減少機器更重要,這會帶來減少所有資源的開銷,包括內存和硬盤,不僅僅是CPU。
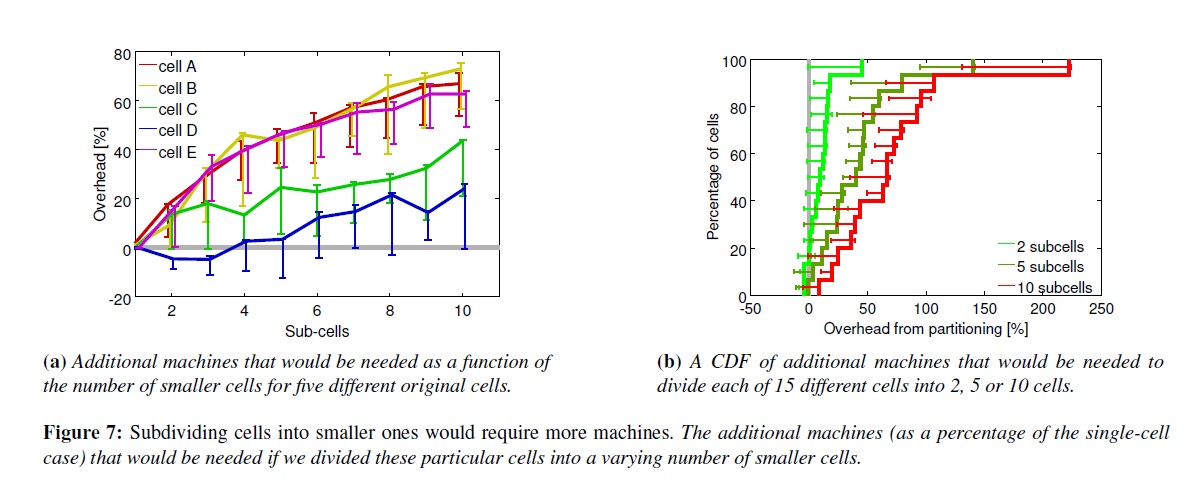
Google建立了大Cell,為了允許大的任務運行,也是為了降低資源碎片。我們通過把負載從一個cell分到多個小cell上來測試后面那個效應(降低碎片效應),隨機的把job用round-robin方式分配出去。圖7展示了用很多小cell會明顯的需要更多機器。
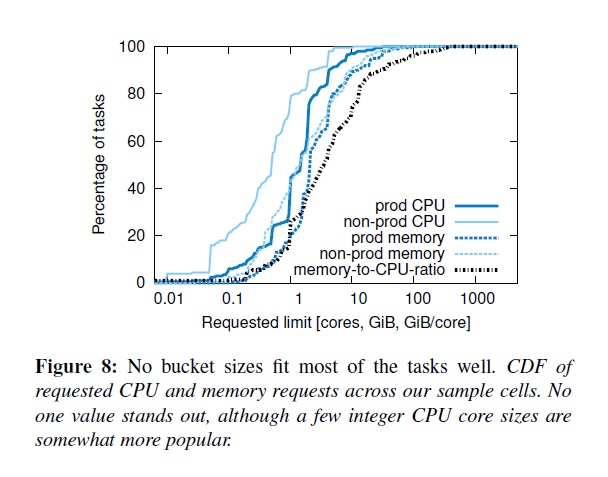
Borg用戶請求的CPU單位是千分之一核,內存和硬盤單位是byte。(1核是一個CPU的超線程,在不同機器類型中的一個通用單位)。圖8展現了這個粒度的好處:CPU核和內存只有少數的“最佳擊球點”,以及這些資源很少的相關性。這個分布和[68]里面的基本差不多,除了我們看到大內存的請求在90%這個線上。
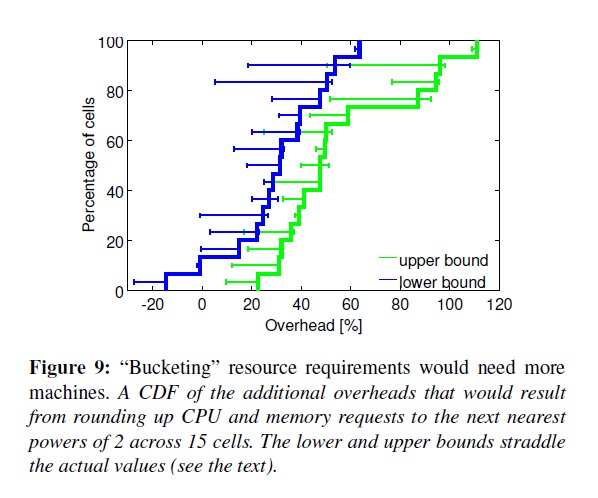
提供一個固定尺寸的容器和虛擬機,在IaaS(infrastructure-as-a-service)提供商里面或許是比較流行的,但不符合我們的需求。為了展現這一點,我們把CPU核和內存限制做成一個個尺寸,然后把prod的job按照大一點最近的尺寸去跑(取這2個維度的平方值之和最近,也就是2維圖上的直線),0.5核的CPU,1G的內存為差值。圖9顯示了一般情況下我們需要30-50%多的資源來運行。上限來自于把大的task跑在一整臺機器上,這些task即使擴大四倍也沒辦法在原有Cell上壓縮跑。下限是允許這些task等待(pending)。(這比[37]里面的數據要大100%,因為我們支持超過4中尺寸而且允許CPU和內存無限擴張)。
一個job可以聲明一個限制資源,是每個task能強制保證的資源上限。Borg會先檢查這個限制是不是在用戶的配額內,然后檢查具體的機器是否有那么多資源來調度這個task。有的用戶會買超過他們需要的配額,也有用戶會的task實際需要更多的資源去跑,因為Borg會殺掉那些需要更多的內存和硬盤空間的task,或者卡住CPU使用率不上去。另外,一些task偶爾需要使用他們的所有資源(例如,在一天的高峰期或者受到了一個拒絕服務攻擊),大多時候用不上那么多資源。
比起把那些分出來但不用的資源浪費掉,我們估計了一個task會用多少資源然后把其他的資源回收再利用給那些可以忍受低質量資源的工作,例如批處理job。這整個過程被叫做資源再利用(resource reclamation)。這個估值叫做task自留地資源(reservation),被Borgmaster每過幾秒就計算一次,是Borglet抓取的細粒度資源消費用率。最初的自留地資源被設置的和資源限制一樣大;在300s之后,也就是啟動那個階段,自留地資源會緩慢的下降到實際用量加上一個安全值。自留地資源在實際用量超過它的時候會迅速上升。
Borg調度器(scheduler)使用限制資源來計算prod task的可用性($3.2),所以這些task從來不依賴于回收的資源,也不提供超售的資源;對于non-prod的task,使用了目前運行task的自留地資源,這么新的task可以被調度到回收資源。
一臺機器有可能因為自留地預估錯度而導致運行時資源不足 —— 即使所有的task都在限制資源之內跑。如果這種情況發生了,我們殺掉或者限制non-prod task,從來不對prod task下手。
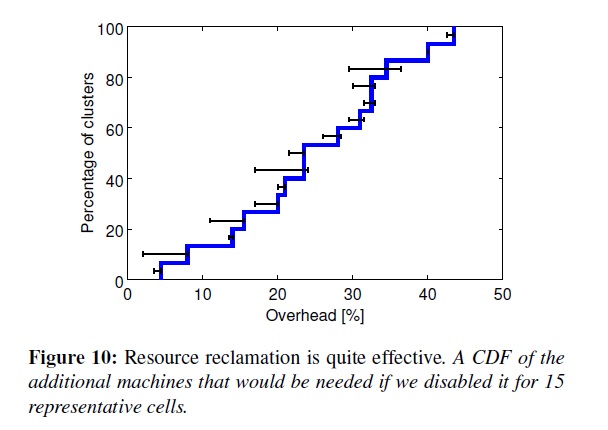
圖10展示了如果沒有資源再利用會需要更多的機器。在一個中等大小的Cell上大概有20%的工作負載跑在回收資源上。
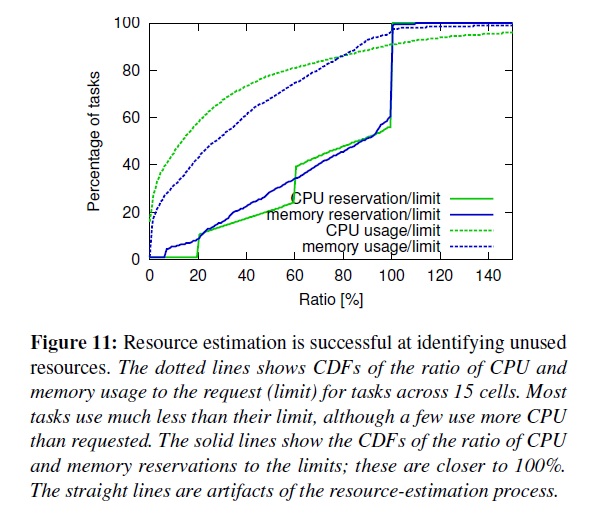
圖11可以看到更多的細節,包括回收資源、實際使用資源和限制資源的比例。一個超內存限制的task首先會被重新調度,不管優先級有多高,所以這樣就很少有task會超過內存限制。另一方面,CPU使用率是可以輕易被卡住的,所以短期的超過自留地資源的高峰時沒什么損害的。
圖11暗示了資源再利用可能是沒必要的保守:在自留地和實際使用中間有一大片差距。為了測試這一點,我們選擇了一個生產cell然后調試它的預估參數到一個激進策略上,把安全區劃小點,然后做了一個介于激進和基本之間的中庸策略跑,然后恢復到基本策略。
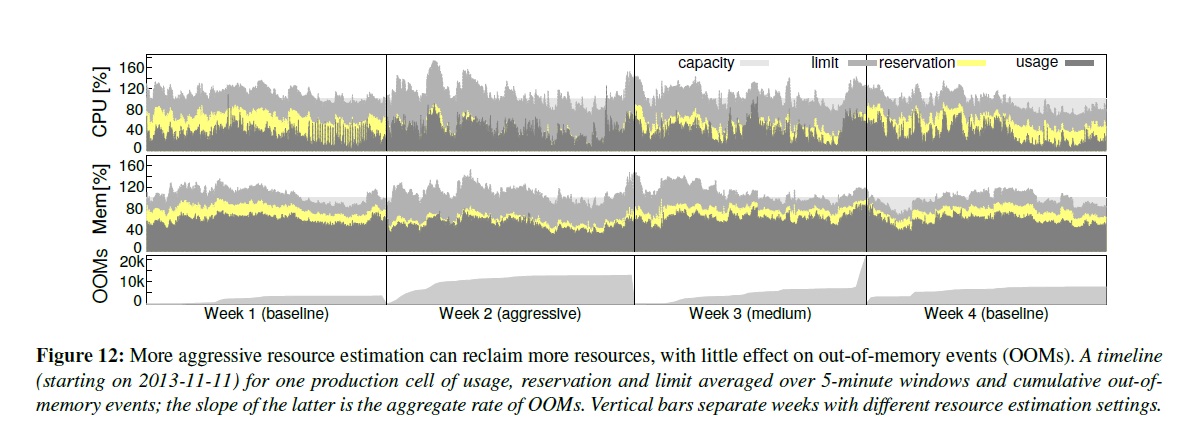
圖12展現了結果。第二周自留地資源和實際資源的差值是最小的,比第三周要小,最大的是第一和第四周。和預期的一樣,周2和周3的OOM率有一個輕微的提升。在復查了這個結果后,我們覺得利大于弊,于是把中庸策略的參數放到其他cell上部署運行。
50%的機器跑9個以上的task;最忙的10%的機器大概跑25個task,4500個線程[83]。雖然在應用間共享機器會增加使用率,也需要一個比較好的機制來保證task之間不互相沖突。包括安全和性能都不能互相沖突。
我們使用Linux chroot監獄作為同一臺機器不同task之間主要的安全隔離機制。為了允許遠程debug,我們以前會分發ssh key來自動給用戶權限去訪問跑他們task的機器,現在不這么干了。對大多數用戶來說,現在提供的是borgssh命令,這個程序和Borglet協同,來構建一個ssh shell,這個shell和task運行在同樣的chroot和cgroup下,這樣限制就更加嚴格了。
VM和安全沙箱技術被使用在外部的軟件上,在Google’s AppEngine (GAE) [38]和Google Compute Engine (GCE)環境下。我們把KVM進程中的每個hosted VM按照一個Borg task運行。
早期的Borglet使用了一種相對原始粗暴的資源隔離措施:事后內存、硬盤、CPU使用率檢查,然后終止使用過多內存和硬盤的task,或者把用太多CPU的激進task通過Linux CPU優先級降下來。不過,很多粗暴的task還是很輕易的能影響同臺機器上其他task的性能,然后很多用戶就會多申請資源來讓Borg減少調度的task數量,然后會導致系統資源利用率降低。資源回收可以彌補一些損失,但不是全部,因為要保證資源安全紅線。在極端情況下,用戶請求使用專用的機器或者cell。
目前,所有Borg task都跑在Linux cgroup-based資源容器[17,58,62]里面,Borglet操作這些容器的設置,這樣就增強了控制因為操作系統內核在起作用。即使這樣,偶爾還是有低級別的資源沖突(例如內存帶寬和L3緩存污染)還是會發生,見[60,83]
為了搞定超負荷和超請求,Borg task有一個應用階級(appclass)。最主要的區分在于延遲敏感latency-sensitive (LS)的應用和其他應用的區別,其他應用我們在文章里面叫batch。LS task是包括面向用戶的應用和需要快速響應的共享基礎設施。高優先級的LS task得到最高有待,可以為了這個把batch task一次餓個幾秒種。
第二個區分在于可壓縮資源(例如CPU循環,disk I/O帶寬)都是速率性的可以被回收的,對于一個task可以降低這些資源的量而不去殺掉task;和不可壓縮資源(例如內存、硬盤空間)這些一般來說不殺掉task就沒法回收的。如果一個機器用光了不可壓縮資源,Borglet馬上就會殺掉task,從低優先級開始殺,直到剩下的自留地資源夠用。如果機器用完了可壓縮資源,Borglet會卡住使用率這樣當短期高峰來到時不用殺掉任何task。如果情況沒有改善,Borgmaster會從這個機器上去除一個或多個task。
Borglet的用戶空間控制循環在未來預期的基礎上給prod task分配內存,在內存壓力基礎上給non-prod task分配內存;從內核事件來處理Out-of-Memory (OOM);殺掉那些想獲取超過自身限制內存的task,或者在一個超負載的機器上實際超過負載時。Linux的積極文件緩存策略讓我們的實現更負載一點,因為精確計算內存用量會麻煩很多。
為了增強性能隔離,LS task可以獨占整個物理CPU核,不讓別的LS task來用他們。batch task可以在任何核上面跑,不過他們只被分配了很少的和LS task共享的資源。Borglet動態的調整貪婪LS task的資源限制來保證他們不會把batch task餓上幾分鐘,有選擇的在需要時使用CFS帶寬控制[75];光有共享是不行的,我們有多個優先級。
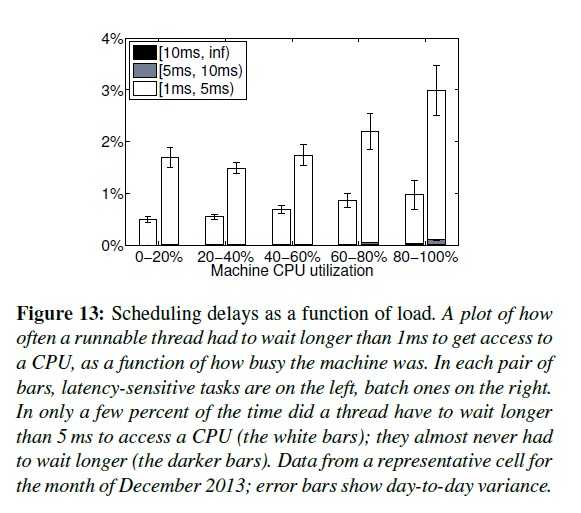
就像Leverich [56],我們發現標準的Linux CPU調度(CFS)需要大幅調整來支持低延遲和高使用率。為了減少調度延遲,我們版本的CFS使用了額外的每cgroup歷史[16],允許LS task驅逐batch task,并且避免多個LS task跑在一個CPU上的調度量子效應(scheduling quantum,譯者:或許指的是互相沖突?)。幸運的是,大多我們的應用使用的每個線程處理一個請求模型,這樣就緩和了持久負載不均衡。我們節儉地使用cpusets來分配CPU核給有特殊延遲需求的應用。這些措施的一部分結果展現在圖13里面。我們持續在這方面投入,增加了線程部署和CPU管理包括NUMA超線程、能源覺察(例如[81]),增加Borglet的控制精確度。
Task被允許在他們的限制范圍內消費資源。其中大部分task甚至被允許去使用更多的可壓縮資源例如CPU,充分利用沒有被使用的資源。大概5%的LS task禁止這么做,主要是為了增加可預測性;小于1%的batch task也禁止。使用超量內存默認是被禁止的,因為這會增加task被殺的概率,不過即使這樣,10%的LS task打開了這個限制,79%的batch task也開了因為這事MapReduce框架默認的。這事對資源再回收($5.5)的一個補償。Batch task很樂意使用沒有被用起來的內存,也樂意不時的釋放一些可回收的內存:大多情況下這跑的很好,即使有時候batch task會被急需資源的LS task殺掉。
“Borg使用策略是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





