溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關大數據存儲格式parquet是怎樣的,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
首先我們從關系數據庫入手,來看關系數據庫的一些常見查詢。對于關系數據庫而言,我們常見的查詢一般有詳情查詢或者統計分組,但是如果是大數據量的情況下,關系數據庫是不能很好的支持統計類的查詢,所以一般關系數據庫多有于對OLTP業務,那么常見的大數據的查詢有個特點,由于數據量很大,獲取具體的詳情數據意義不大,所以基本都是統計類的查詢,如:select count(1) cnt,ip from access_log group by ip,查詢每個ip的訪問次數。當然也可能有查詢詳細做深度的數據分析。
對于查詢速度當然是越快越好,我們可以從以下幾個方面來提高這個系統的查詢速度(當然緩存不在考慮的范疇內),1.查詢系統框架的優化,這里可能包含了(執行計劃啊,分布式計算等等等),2.底層文件存儲格式的優化,盡量減少IO.3.當然還有索引技術.
針對上面的sql:select count(1) cnt,ip from access_log group by ip
我們假設access_log的格式如下: <code> access_log{ string ip; string access_time; ............(其他N個屬性)
} </code>
如果是行存儲:

我們需要讀取一行的所有數據,然后獲取其中的ip字段,在做分組統計。增加的磁盤的IO,同時也增加了計算壓力.
如果是列存儲會如何: 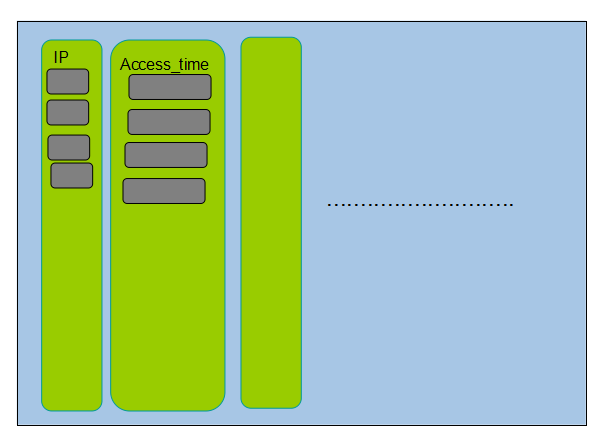
對于上面的統計,我們只需要讀取IP就可以,讀取不需要的列信息,這就是列存儲對于大數據的統計類查詢的優點所在,當然除此之外大數據本身的稀疏性,采用列式可能更好的去優化存儲結構,減少存儲空間.
parquet是twitter在2013年開源的數據結構,google的Dremel: [Interactive Analysis of Web-Scale Datasets http://research.google.com/pubs/pub36632.html](Interactive Analysis of Web-Scale Datasets http://research.google.com/pubs/pub36632.html "Interactive Analysis of Web-Scale Datasets http://research.google.com/pubs/pub36632.html").這個大數據查詢利器的paper里面,其實主要也是在闡述底層文件存儲格式。
Parquet支持復雜嵌套的數據結構組成,并使用重復級別/定義級別(repetition/definition level )的方法來對數據結構進行編碼,嵌套的方式其實可以避免了大數據的join問題.
Parquet支持對某一列數據進行壓縮,支持任意開發語言的讀寫操作.目前是apache的頂級項目.
首先來看一下如何定義一個parquet的文件格式,這里也是采用類似PB的格式定義 這里采用了班級信息來作為示例,有多個班級,每一個班級有個master,有多個學生(可以無),每個學生有名稱和多個愛好,還有每一門可課程的成績以及課程名稱. schema定義: <code> message classroom{ required string master; repeated group students{ required string name; repeated string hobbys; repeated group coursescore{ required string name; optional string score; } } } </code> required 表示必填 repeated 表示可以有任意個 optional 0 or 1 對于數據可以關系可以分為Map以及List,如果為List可以采用repeated,Map采用group 關鍵字修飾.
這里我們來定義一組數據:
<code> { master:"jack", student: name:"tom" student: name:"joy", hobbys:"basketball", hobbys:"football", coursescore: name:"math", coursescore: name:"chinese", score:100 } { master:"BoBo" } </code>
兩個班級一個有學生一個沒有,一個學生有愛好有課程,一個什么也沒有. 我們先來看看如何存儲.
依據上面定義的schema,可以先轉化為一個tree表示結構
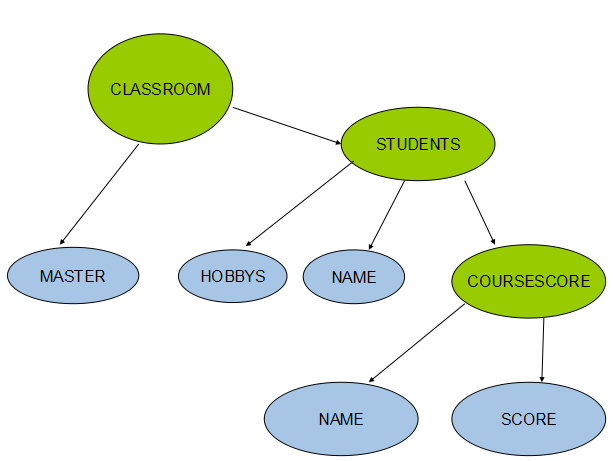
只有樹的根節點是需要實際存儲的數據節點,其余的只是關系的一種維系。 下圖展示了其嵌套關系
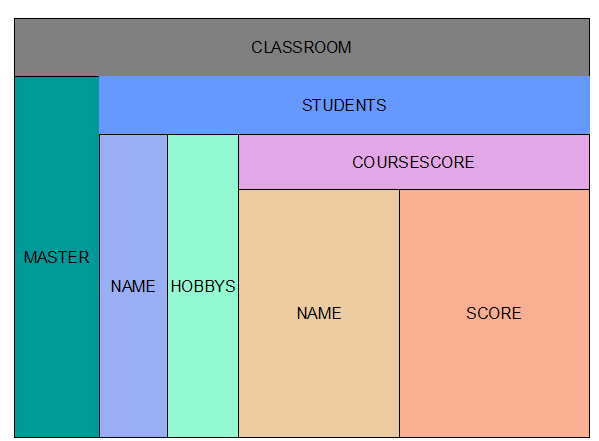
實際存儲也是這樣,每一列存儲了所有的數據信息。是不是存儲很容易。
既然所有的同一類的數據存儲在一起,那么數據如何還原為原來的數據。這里引入了parquet的元數據信息,如何還原數據需要 Repetition Level以及Definition Level這兩個元數據信息。
首先我們需要知道哪些數據是一組的,其實還需要知道數據和數據之間的層級關系,OK。這兩個元數據信息可以幫我們搞的.(當然也是存儲的時候寫入的元數據信息)
Repetition Level是記錄該列的值是在哪一個級別上重復的。
用剛才的兩個classroom信息來舉例: 對于兩個classroom的master來說,由于都是獨立的沒有直接關系,所以他們的Repetition level是0
Jack 0
BoBO 0
對于jack的學生tom,joy來說,tom是第一個學生,所以level是0,而joy平級,所以是1.
<table> <tr><td>master</td><td>Repetition Level</td><tr> <tr><td>Jack</td><td>0</td><tr> <tr><td>BoBo</td><td>0</td><tr> </table>
<table> <tr><td>student.name</td><td>Repetition Level</td><tr> <tr><td>tom</td><td>0</td><tr> <tr><td>joy</td><td>1</td><tr> <tr><td>null</td><td>2</td><tr> </table>
<table> <tr><td>student.coursescore.score</td><td>Repetition Level</td><tr> <tr><td>null</td><td>0</td><tr> <tr><td>null</td><td>2</td><tr> <tr><td>100</td><td>1</td><tr> </table>
基于Repetition level是可以把原有的數據分好類,但是我們現在我們還不知道一條記錄到什么位置STOP,以及數據之前的關系,這個時候在引入Definition Level。
這個時候在引入Definition Level 是定義的深度,用來記錄該列是否是虛擬出來的。所以對于非NULL的記錄,是沒有意義的,其值必然為相同。同樣舉個例子。 比如對于master來說深度就是0,因為是required。
<table> <tr><td>master</td><td>Definition Level</td><tr> <tr><td>Jack</td><td>0</td><tr> <tr><td>BoBo</td><td>0</td><tr> </table>
<table> <tr><td>student.name</td><td>Definition Level</td><tr> <tr><td>tom</td><td>1</td><tr> <tr><td>joy</td><td>2</td><tr> <tr><td>null</td><td>1</td><tr> <table> 通過Definition Level可以還原數據的嵌套關系。
關于大數據存儲格式parquet是怎樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





