溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Python中怎么獲取JS動態內容,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。

網頁的新聞在HTML源碼中一條都找不到,全是由JS動態生成加載。
遇到這種情況,我們應該如何對網頁進行爬取呢?有兩種方法:
1、從網頁響應中找到JS腳本返回的JSON數據;2、使用Selenium對網頁進行模擬訪問
在此只對第一種方法作介紹,關于Selenium的使用,后面有專門的一篇。
從網頁響應中找到JS腳本返回的JSON數據
即使網頁內容是由JS動態生成加載的,JS也需要對某個接口進行調用,并根據接口返回的JSON數據再進行加載和渲染。
所以我們可以找到JS調用的數據接口,從數據接口中找到網頁中最后呈現的數據。
就以今日頭條為例來演示:
1、從找到JS請求的數據接口
undefined
undefined
undefined
undefined
undefined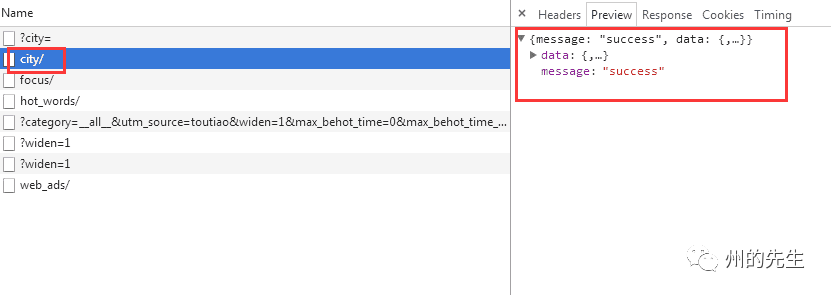
undefined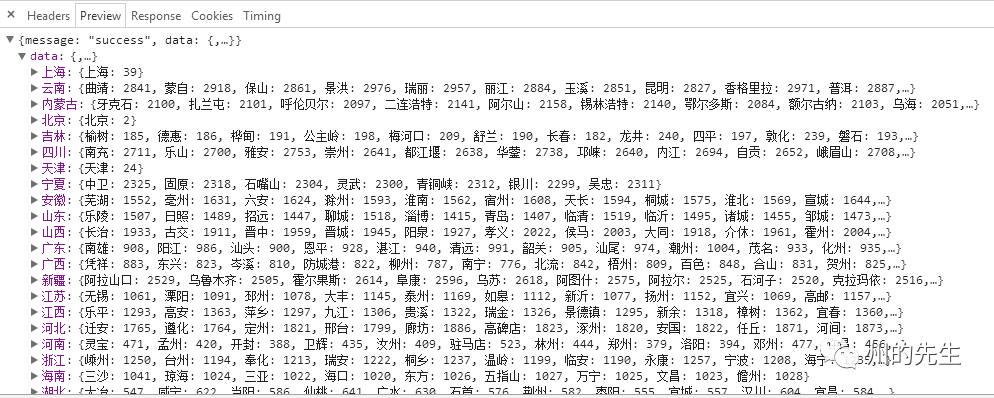
undefined
undefined
undefined
與首頁的圖片新聞呈現的數據是一樣的,那么數據應該就在這里面了。
看看其他的鏈接:
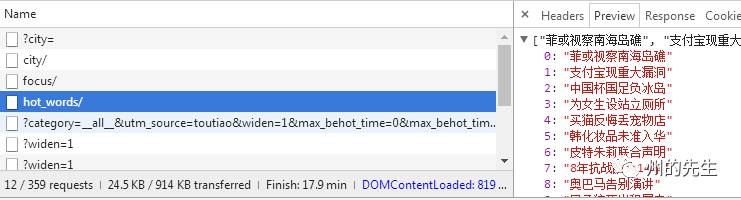
這應該是熱搜關鍵詞
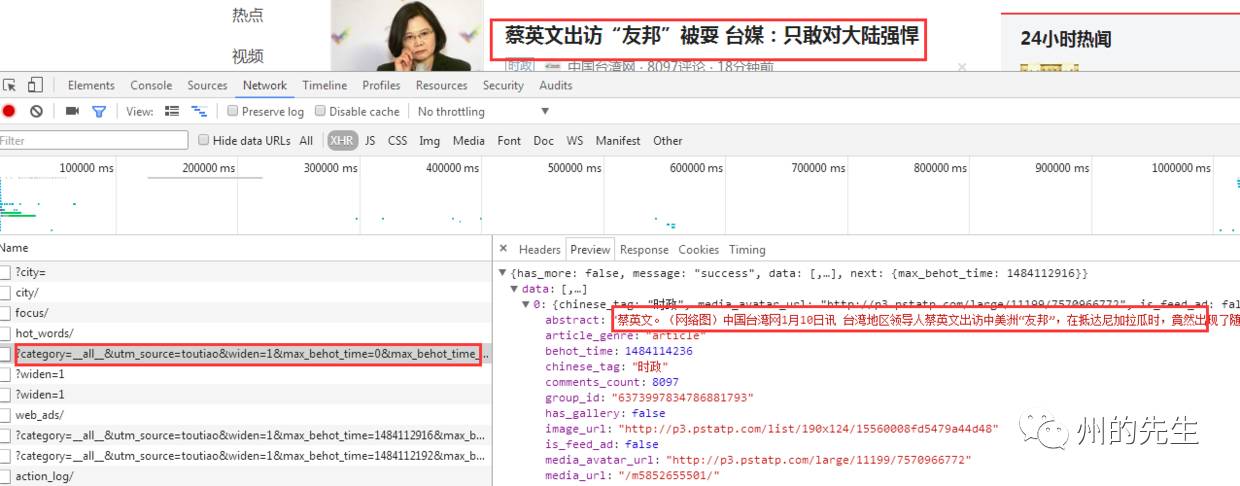
這個就是圖片新聞下面的新聞了。
我們打開一個接口鏈接看看:http://www.toutiao.com/api/pc/focus/

返回一串亂碼,但從響應中查看的是正常的編碼數據:
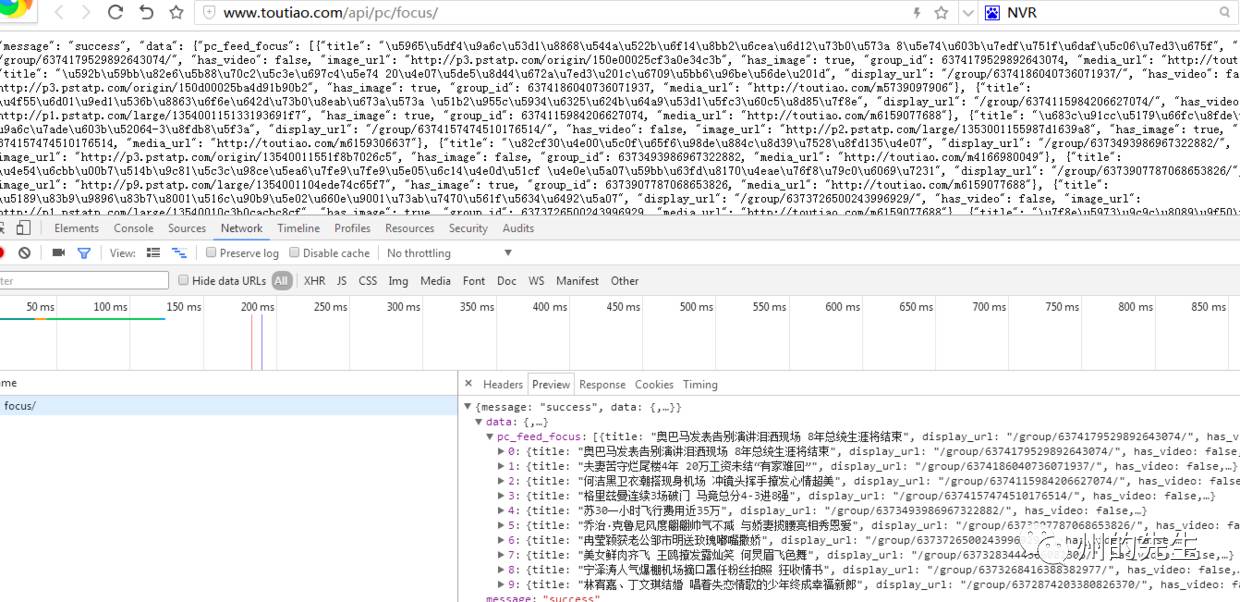
有了對應的數據接口,我們就可以仿照之前的方法對數據接口進行請求和獲取響應了
2、請求和解析數據接口數據
先上完整代碼:
# coding:utf-8 import requests import json url = 'http://www.toutiao.com/api/pc/focus/' wbdata = requests.get(url).text data = json.loads(wbdata) news = data['data']['pc_feed_focus'] for n in news: title = n['title'] img_url = n['image_url'] url = n['media_url'] print(url,title,img_url)
返回出來的結果如下:
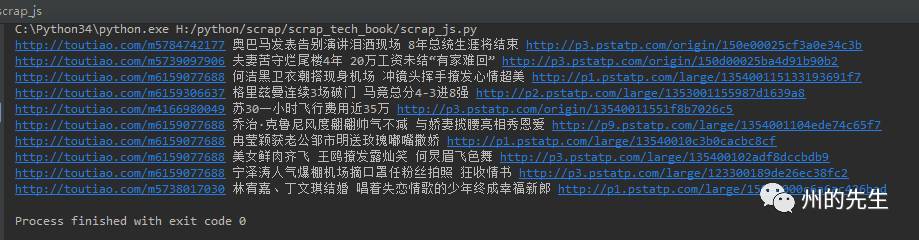
照例,稍微講解一下代碼:
代碼分為四部分,
第一部分:引入相關的庫
# coding:utf-8 import requests import json
第二部分:對數據接口進行http請求
url = ' wbdata = requests.get(url).text
第三部分:對HTTP響應的數據JSON化,并索引到新聞數據的位置
data = json.loads(wbdata) news = data['data']['pc_feed_focus']
第四部分:對索引出來的JSON數據進行遍歷和提取
for n in news: title = n['title'] img_url = n['image_url'] url = n['media_url'] print(url,title,img_url)
關于Python中怎么獲取JS動態內容就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





