溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Hadoop中怎么實現MapReduce的數據輸入”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Hadoop中怎么實現MapReduce的數據輸入”吧!
接下來我們按照MapReduce過程中數據流動的順序,來分解org.apache.hadoop.mapreduce.lib.*的相關內容,并介紹對應的基類的功能。首先是input部分,它實現了MapReduce的數據輸入部分。類圖如下: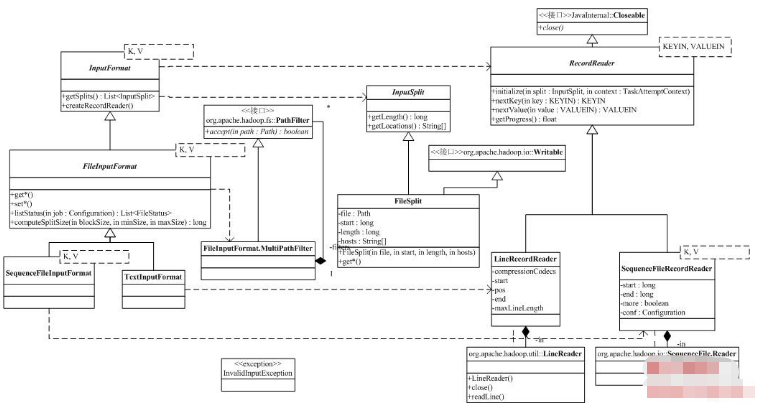
類圖的右上角是InputFormat,它描述了一個MapReduceJob的輸入,通過InputFormat,Hadoop可以:
l 檢查MapReduce輸入數據的正確性;
l 將輸入數據切分為邏輯塊InputSplit,這些塊會分配給Mapper;
l 提供一個RecordReader實現,Mapper用該實現從InputSplit中讀取輸入的<K,V>對。
在org.apache.hadoop.mapreduce.lib.input中,Hadoop為所有基于文件的InputFormat提供了一個虛基類FileInputFormat。下面幾個參數可以用于配置FileInputFormat:
l mapred.input.pathFilter.class:輸入文件過濾器,通過過濾器的文件才會加入InputFormat;
l mapred.min.split.size:最小的劃分大小;
l mapred.max.split.size:最大的劃分大小;
l mapred.input.dir:輸入路徑,用逗號做分割。
類中比較重要的方法有:
protectedList<FileStatus> listStatus(Configuration job)
遞歸獲取輸入數據目錄中的所有文件(包括文件信息),輸入的job是系統運行的配置Configuration,包含了上面我們提到的參數。
publicList<InputSplit> getSplits(JobContext context)
將輸入劃分為InputSplit,包含兩個循環,第一個循環處理所有的文件,對于每一個文件,根據輸入的劃分最大/最小值,循環得到文件上的劃分。注意,劃分不會跨越文件。
FileInputFormat沒有實現InputFormat的createRecordReader方法。
FileInputFormat有兩個子類,SequenceFileInputFormat是Hadoop定義的一種二進制形式存放的鍵/值文件(參考http://hadoop.apache.org/core/do ... o/SequenceFile.html),它有自己定義的文件布局。由于它有特殊的擴展名,所以SequenceFileInputFormat重載了listStatus,同時,它實現了createRecordReader,返回一個SequenceFileRecordReader對象。TextInputFormat處理的是文本文件,createRecordReader返回的是LineRecordReader的實例。這兩個類都沒有重載FileInputFormat的getSplits方法,那么,在他們對于的RecordReader中,必須考慮FileInputFormat對輸入的劃分方式。
FileInputFormat的getSplits,返回的是FileSplit。這是一個很簡單的類,包含的屬性(文件名,起始偏移量,劃分的長度和可能的目標機器)已經足以說明這個類的功能。
RecordReader用于在劃分中讀取<Key,Value>對。RecordReader有五個虛方法,分別是:
l initialize:初始化,輸入參數包括該Reader工作的數據劃分InputSplit和Job的上下文context;
l nextKey:得到輸入的下一個Key,如果數據劃分已經沒有新的記錄,返回空;
l nextValue:得到Key對應的Value,必須在調用nextKey后調用;
l getProgress:得到現在的進度;
l close,來自java.io的Closeable接口,用于清理RecordReader。
我們以LineRecordReader為例,來分析RecordReader的構成。前面我們已經分析過FileInputFormat對文件的劃分了,劃分完的Split包括了文件名,起始偏移量,劃分的長度。由于文件是文本文件,LineRecordReader的初始化方法initialize會創建一個基于行的讀取對象LineReader(定義在org.apache.hadoop.util中,我們就不分析啦),然后跳過輸入的最開始的部分(只在Split的起始偏移量不為0的情況下進行,這時最開始的部分可能是上一個Split的最后一行的一部分)。nextKey的處理很簡單,它使用當前的偏移量作為Key,nextValue當然就是偏移量開始的那一行了(如果行很長,可能出現截斷)。進度getProgress和close都很簡單。
感謝各位的閱讀,以上就是“Hadoop中怎么實現MapReduce的數據輸入”的內容了,經過本文的學習后,相信大家對Hadoop中怎么實現MapReduce的數據輸入這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





