溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Hadoop MapReduce是什么”,在日常操作中,相信很多人在Hadoop MapReduce是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Hadoop MapReduce是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
MapReduce是一個分布式運算程序的編程框架,是用戶開發“基于Hadoop的數據分析應用”的核心框架。
MapReduce核心功能是將用戶編寫的業務邏輯代碼和自帶默認組件整合成一個完整的分布式運算程序,并發運行在一個Hadoop集群上。
MapReduce思想在生活中處處可見。或多或少都曾接觸過這種思想。MapReduce的思想核心是“分而治之”,適用于大量復雜的任務處理場景(大規模數據處理場景)。即使是發布過論文實現分布式計算的谷歌也只是實現了這種思想,而不是自己原創。
Map負責“分”,即把復雜的任務分解為若干個“簡單的任務”來并行處理。可以進行拆分的前提是這些小任務可以并行計算,彼此間幾乎沒有依賴關系。
Reduce負責“合”,即對map階段的結果進行全局匯總。
這兩個階段合起來正是MapReduce思想的體現。
還有一個比較形象的語言解釋MapReduce:
我們要數圖書館中的所有書。你數1號書架,我數2號書架。這就是“Map”。我們人越多,數書就越快。
現在我們到一起,把所有人的統計數加在一起。這就是“Reduce”。
MapReduce是采用一種分而治之的思想設計出來的分布式計算框架
那什么是分而治之呢?
比如一復雜、計算量大、耗時長的的任務,暫且稱為“大任務”;
此時使用單臺服務器無法計算或較短時間內計算出結果時,可將此大任務切分成一個個小的任務,小任務分別在不同的服務器上并行的執行;
最終再匯總每個小任務的結果
MapReduce由兩個階段組 成:
Map階段(切分成一個個小的任務)
Reduce階段(匯總小任務的結果) 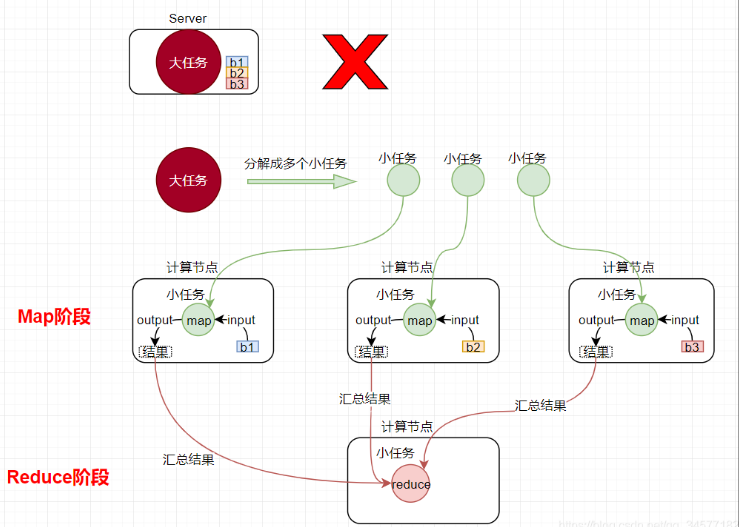
map階段有一個關鍵的map()函數;
此函數的輸入是鍵值對
輸出是一系列鍵值對,輸出寫入本地磁盤。
reduce階段有一個關鍵的函數reduce()函數
此函數的輸入也是鍵值對(即map的輸出(kv對))
輸出也是一系列鍵值對,結果最終寫入HDFS
Map&Reduce
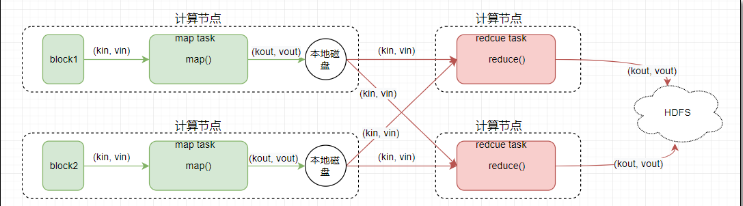
mapReduce編程模型的總結:
MapReduce的開發一共有八個步驟其中map階段分為2個步驟,shuffle階段4個步驟,reduce階段分為2個步驟
第一步:設置inputFormat類,將我們的數據切分成key,value對,輸入到第二步
第二步:自定義map邏輯,處理我們第一步的輸入數據,然后轉換成新的key,value對進行輸出
第三步:對輸出的key,value對進行分區。(相同key的數據屬于同一分區)
第四步:對不同分區的數據按照相同的key進行排序
第五步:對分組后的數據進行規約(combine操作),降低數據的網絡拷貝(可選步驟)
第六步:對排序后的數據進行分組,分組的過程中,將相同key的value放到一個集合當中(每組數據調用一次reduce方法)
第七步:對多個map的任務進行合并,排序,寫reduce函數自己的邏輯,對輸入的key,value對進行處理,轉換成新的key,value對進行輸出
第八步:設置outputformat將輸出的key,value對數據進行保存到文件中。
hadoop沒有沿用java當中基本的數據類型,而是自己進行封裝了一套數據類型,其自己封裝的類型與java的類型對應如下
下表常用的數據類型對應的Hadoop數據序列化類型
| Java類型 | Hadoop Writable類型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| byte[] | BytesWritable |

需求:現有數據格式如下,每一行數據之間都是使用逗號進行分割,求取每個單詞出現的次數
hello,hello world,world hadoop,hadoop hello,world hello,flume hadoop,hive hive,kafka flume,storm hive,oozie
<repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0-mr1-cdh6.14.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0-cdh6.14.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.0-cdh6.14.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.0-cdh6.14.2</version> </dependency> <!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <version>RELEASE</version> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> <!-- <verbal>true</verbal>--> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <minimizeJar>true</minimizeJar> </configuration> </execution> </executions> </plugin> </plugins> </build>
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 自定義mapper類需要繼承Mapper,有四個泛型,
* keyin: k1 行偏移量 Long
* valuein: v1 一行文本內容 String
* keyout: k2 每一個單詞 String
* valueout : v2 1 int
* 在hadoop當中沒有沿用Java的一些基本類型,使用自己封裝了一套基本類型
* long ==>LongWritable
* String ==> Text
* int ==> IntWritable
*
*/
public class MyMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
/**
* 繼承mapper之后,覆寫map方法,每次讀取一行數據,都會來調用一下map方法
* @param key:對應k1
* @param value:對應v1
* @param context 上下文對象。承上啟下,承接上面步驟發過來的數據,通過context將數據發送到下面的步驟里面去
* @throws IOException
* @throws InterruptedException
* k1 v1
* 0;hello,world
*
* k2 v2
* hello 1
* world 1
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//獲取我們的一行數據
String line = value.toString();
String[] split = line.split(",");
Text text = new Text();
IntWritable intWritable = new IntWritable(1);
for (String word : split) {
//將每個單詞出現都記做1次
//key2 Text類型
//v2 IntWritable類型
text.set(word);
//將我們的key2 v2寫出去到下游
context.write(text,intWritable);
}
}
}import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
//第三步:分區 相同key的數據發送到同一個reduce里面去,相同key合并,value形成一個集合
/**
* 繼承Reducer類之后,覆寫reduce方法
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int result = 0;
for (IntWritable value : values) {
//將我們的結果進行累加
result += value.get();
}
//繼續輸出我們的數據
IntWritable intWritable = new IntWritable(result);
//將我們的數據輸出
context.write(key,intWritable);
}
}import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*
這個類作為mr程序的入口類,這里面寫main方法
*/
public class WordCount extends Configured implements Tool{
/**
* 實現Tool接口之后,需要實現一個run方法,
* 這個run方法用于組裝我們的程序的邏輯,其實就是組裝八個步驟
* @param args
* @return
* @throws Exception
*/
@Override
public int run(String[] args) throws Exception {
//獲取Job對象,組裝我們的八個步驟,每一個步驟都是一個class類
Configuration conf = super.getConf();
Job job = Job.getInstance(conf, "mrdemo1");
//實際工作當中,程序運行完成之后一般都是打包到集群上面去運行,打成一個jar包
//如果要打包到集群上面去運行,必須添加以下設置
job.setJarByClass(WordCount.class);
//第一步:讀取文件,解析成key,value對,k1:行偏移量 v1:一行文本內容
job.setInputFormatClass(TextInputFormat.class);
//指定我們去哪一個路徑讀取文件
TextInputFormat.addInputPath(job,new Path("文件位置"));
//第二步:自定義map邏輯,接受k1 v1 轉換成為新的k2 v2輸出
job.setMapperClass(MyMapper.class);
//設置map階段輸出的key,value的類型,其實就是k2 v2的類型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//第三步到六步:分區,排序,規約,分組都省略
//第七步:自定義reduce邏輯
job.setReducerClass(MyReducer.class);
//設置key3 value3的類型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第八步:輸出k3 v3 進行保存
job.setOutputFormatClass(TextOutputFormat.class);
//一定要注意,輸出路徑是需要不存在的,如果存在就報錯
TextOutputFormat.setOutputPath(job,new Path("輸出文件位置"));
//提交job任務
boolean b = job.waitForCompletion(true);
return b?0:1;
/***
* 第一步:讀取文件,解析成key,value對,k1 v1
* 第二步:自定義map邏輯,接受k1 v1 轉換成為新的k2 v2輸出
* 第三步:分區。相同key的數據發送到同一個reduce里面去,key合并,value形成一個集合
* 第四步:排序 對key2進行排序。字典順序排序
* 第五步:規約 combiner過程 調優步驟 可選
* 第六步:分組
* 第七步:自定義reduce邏輯接受k2 v2 轉換成為新的k3 v3輸出
* 第八步:輸出k3 v3 進行保存
*
*
*/
}
/*
作為程序的入口類
*/
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.set("hello","world");
//提交run方法之后,得到一個程序的退出狀態碼
int run = ToolRunner.run(configuration, new WordCount(), args);
//根據我們 程序的退出狀態碼,退出整個進程
System.exit(run);
}
}到此,關于“Hadoop MapReduce是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





