溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下ceph中CRUSH數據分布算法有什么用,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
CRUSH是ceph的一個模塊,主要解決可控、可擴展、去中心化的數據副本分布問題。
隨著大規模分布式存儲系統(PB級的數據和成百上千臺存儲設備)的出現。這些系統必須平衡的分布數據和負載(提高資源利用率),最大化系統的性能,并要處理系統的擴展和硬件失效。ceph設計了CRUSH(一個可擴展的偽隨機數據分布算法),用在分布式對象存儲系統上,可以有效映射數據對象到存儲設備上(不需要中心設備)。因為大型系統的結構式動態變化的,CRUSH能夠處理存儲設備的添加和移除,并最小化由于存儲設備的的添加和移動而導致的數據遷移。
對象存儲設備(object-based storage devices)管理磁盤數據塊的分配,并提供對象的讀寫接口。在一些對象存儲系統中,每個文件的數據被分成多個對象,這些對象分布在整個存儲集群中。對象存儲系統簡化了數據層(把數據塊列表換成對象列表,并把低級的數據塊分配問題交個各個設備)。對象存儲系統的基本問題是如何分布數據到上千個存儲設備上。
一個robust解決方案是把數據隨機分布到存儲設備上,這個方法能夠保證負載均衡,保證新舊數據混合在一起。但是簡單HASH分布不能有效處理設備數量的變化,導致大量數據遷移。ceph開發了CRUSH(Controoled Replication Under Scalable Hashing),一種偽隨機數據分布算法,它能夠在層級結構的存儲集群中有效的分布對象的副本。CRUSH實現了一種偽隨機(確定性)的函數,它的參數是object id或object group id,并返回一組存儲設備(用于保存object副本)。CRUSH需要cluster map(描述存儲集群的層級結構)、和副本分布策略(rule)。
CRUSH有兩個關鍵優點:
任何組件都可以獨立計算出每個object所在的位置(去中心化)。
只需要很少的元數據(cluster map),只要當刪除添加設備時,這些元數據才需要改變。
CRUSH算法通過每個設備的權重來計算數據對象的分布。對象分布是由cluster map和data distribution policy決定的。cluster map描述了可用存儲資源和層級結構(比如有多少個機架,每個機架上有多少個服務器,每個服務器上有多少個磁盤)。data distribution policy由placement rules組成。rule決定了每個數據對象有多少個副本,這些副本存儲的限制條件(比如3個副本放在不同的機架中)。
CRUSH算出x到一組OSD集合(OSD是對象存儲設備):
(osd0, osd1, osd2 … osdn) = CRUSH(x)
CRUSH利用多參數HASH函數,HASH函數中的參數包括x,使得從x到OSD集合是確定性的和獨立的。CRUSH只使用了cluster map、placement rules、x。CRUSH是偽隨機算法,相似輸入的結果之間沒有相關性。
Cluster map由device和bucket組成,它們都有id和權重值。Bucket可以包含任意數量item。item可以都是的devices或者都是buckets。管理員控制存儲設備的權重。權重和存儲設備的容量有關。Bucket的權重被定義為它所包含所有item的權重之和。CRUSH基于4種不同的bucket type,每種有不同的選擇算法。
副本在存儲設備上的分布影響數據的安全。cluster map反應了存儲系統的物理結構。CRUSH placement policies決定把對象副本分布在不同的區域(某個區域發生故障時并不會影響其他區域)。每個rule包含一系列操作(用在層級結構上)。
這些操作包括:
tack(a) :選擇一個item,一般是bucket,并返回bucket所包含的所有item。這些item是后續操作的參數,這些item組成向量i。
select(n, t):迭代操作每個item(向量i中的item),對于每個item(向量i中的item)向下遍歷(遍歷這個item所包含的item),都返回n個不同的item(type為t的item),并把這些item都放到向量i中。select函數會調用c(r, x)函數,這個函數會在每個bucket中偽隨機選擇一個item。
emit:把向量i放到result中。
存儲設備有一個確定的類型。每個bucket都有type屬性值,用于區分不同的bucket類型(比如”row”、”rack”、”host”等,type可以自定義)。rules可以包含多個take和emit語句塊,這樣就允許從不同的存儲池中選擇副本的storage target。
select(n, t)操作會循環選擇第 r=1,…,n 個副本,r作為選擇參數。在這個過程中,假如選擇到的item遇到三種情況(沖突,故障,超載)時,CRUSH會拒絕選擇這個item,并使用r'(r’和r、出錯次數、firstn參數有關)作為選擇參數重新選擇item。
沖突:這個item已經在向量i中,已被選擇。
故障:設備發生故障,不能被選擇。
超載:設備使用容量超過警戒線,沒有剩余空間保存數據對象。
故障設備和超載設備會在cluster map上標記(還留在系統中),這樣避免了不必要的數據遷移。
當添加移除存儲設備,或有存儲設備發生故障時(cluster map發生改變時),存儲系統中的數據會發生遷移。好的數據分布算法可以最小化數據遷移大小。
CRUSH映射算法解決了效率和擴展性這兩個矛盾的目標。而且當存儲集群發生變化時,可以最小化數據遷移,并重新恢復平衡分布。CRUSH定義了四種具有不同算法的的buckets。每種bucket基于不同的數據結構,并有不同的c(r,x)偽隨機選擇函數。
不同的bucket有不同的性能和特性:
Uniform Buckets:適用于具有相同權重的item,而且bucket很少添加刪除item。它的查找速度是最快的。
List Buckets:它的結構是鏈表結構,所包含的item可以具有任意的權重。CRUSH從表頭開始查找副本的位置,它先得到表頭item的權重Wh、剩余鏈表中所有item的權重之和Ws,然后根據hash(x, r, item)得到一個[0~1]的值v,假如這個值v在[0~Wh/Ws)之中,則副本在表頭item中,并返回表頭item的id。否者繼續遍歷剩余的鏈表。
Tree Buckets:鏈表的查找復雜度是O(n),決策樹的查找復雜度是O(log n)。item是決策樹的葉子節點,決策樹中的其他節點知道它左右子樹的權重,節點的權重等于左右子樹的權重之和。CRUSH從root節點開始查找副本的位置,它先得到節點的左子樹的權重Wl,得到節點的權重Wn,然后根據hash(x, r, node_id)得到一個[0~1]的值v,假如這個值v在[0~Wl/Wn)中,則副本在左子樹中,否者在右子樹中。繼續遍歷節點,直到到達葉子節點。Tree Bucket的關鍵是當添加刪除葉子節點時,決策樹中的其他節點的node_id不變。決策樹中節點的node_id的標識是根據對二叉樹的中序遍歷來決定的(node_id不等于item的id,也不等于節點的權重)。
Straw Buckets:這種類型讓bucket所包含的所有item公平的競爭(不像list和tree一樣需要遍歷)。這種算法就像抽簽一樣,所有的item都有機會被抽中(只有最長的簽才能被抽中)。每個簽的長度是由length = f(Wi)*hash(x, r, i) 決定的,f(Wi)和item的權重有關,i是item的id號。c(r, x) = MAXi(f(Wi) * hash(x, r, i))。
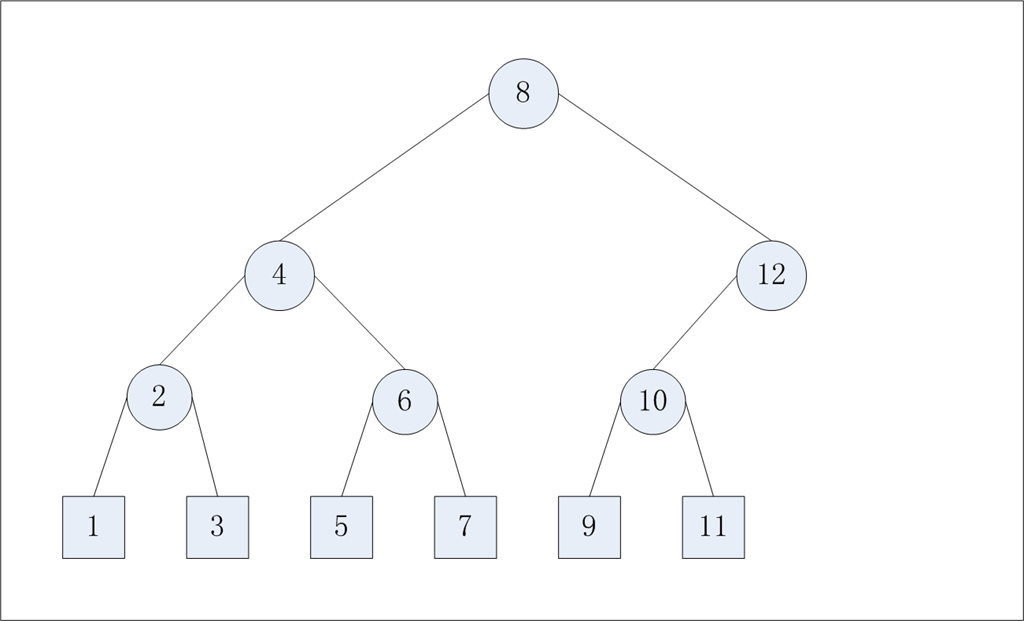
圖1 Tree Buckets的結構
以上是“ceph中CRUSH數據分布算法有什么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





